
新智元报道
编辑:桃子
【新智元导读】在万亿级大模型横行的时代,单纯靠「堆芯片」已经玩不动了。中兴交出了一份不一样的答卷:跳出单一芯片的性能内卷,靠「系统级协同」重构智算底座。
当前AI大模型参数规模已突破万亿量级,单GPU芯片的物理功耗密度、互连带宽与内存容量瓶颈,成为制约算力发展的核心问题,传统「芯片堆砌」的算力建设模式,正面临通信开销剧增、算力利用率骤降的行业共性痛点。
随着技术的快速演进和迭代,当前已经不是「一颗芯片决定算力」的时代,AI基础设施的竞争正在由「单一芯片」转向以「整机系统」为核心的竞争。
在各大GPU厂商聚焦芯片研发竞赛的背景下,中兴通讯从系统级协同架构出发,推出超节点技术,通过重构算力互联体系,将数十至数百颗多厂家GPU逻辑整合为统一计算单元,实现了算力的系统级优化。
近期中兴通讯发布的《中兴通讯超节点白皮书》,不仅为突破单GPU芯片瓶颈提供了全新解决方案,更重塑了AI算力基础设施的构建逻辑,其背后的技术创新与设计思路,对整个智算行业的发展都具有重要的参考意义。
核心底层逻辑
跳出GPU竞赛,锚定系统级算力协同
面对单GPU芯片的性能瓶颈,行业内早已形成共识,即通过高速无损互联技术将多颗GPU整合为逻辑上的「超级计算机」,是突破单芯片性能上限的核心技术路径,中兴超节点的底层设计逻辑,正是深度契合这一行业趋势,跳出单芯片性能竞赛的传统思路,将核心发力点放在系统级的算力协同上。
从第三方视角来看,这一选择既避开了GPU芯片研发的高壁垒、长周期竞争,又精准切中了当前算力建设的核心痛点——传统模式的问题并非单芯片性能不足,而是多芯片协同的效率过低。
中兴超节点并非GPU的简单物理堆砌,而是融合多芯片、整机硬件、高速互联与配套软件的集成系统,其构建严格遵循四大核心前提,为系统级算力协同筑牢基础:
一是芯片能力的均衡性,要求GPU的算力、显存、互联带宽三者匹配,避免资源浪费;
二是互联架构的有效性,超节点内任意GPU间的互联带宽达到机间互联的8倍左右,兼顾通信效率、扩展性与场景适配性;
三是内存访问的便捷性,所有GPU支持统一内存编址,兼容内存语义和消息语义,保障编程易用性与数据访问效率;
四是架构扩展的原生性,且集群扩展后仍属于高带宽域,满足算力按需配置的需求。
这四大前提的设计,让中兴超节点从底层就确立了「系统级算力最优」的目标,所有后续技术创新均围绕这一核心展开。
硬件架构创新
OEX正交无背板互联,重构GPU物理协同基础
传统GPU集群依赖Cable Tray线缆架构,存在信号损耗大、算力密度低、运维难度高、组网成本高的明显短板,这也是制约多GPU协同效率的物理层关键问题。
中兴超节点在硬件架构上的核心创新,就是推出了Orthogonal Electrical eXchange(OEX)正交无背板互联交换架构,这一架构也于2025年成功入选ODCC「年度重大技术突破」案例,从第三方视角来看,这一创新实现了GPU物理互联体系的底层重构,为高密度、高可靠性的GPU协同奠定了物理基础。
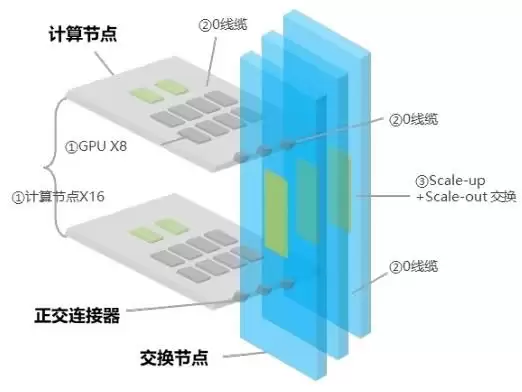
图1 OEX互联示意图
OEX架构的核心设计,是让计算托盘与交换托盘实现垂直交叉物理直连,彻底摒弃传统的高速线缆,通过正交连接器与单级交换拓扑构建无线缆的互联体系,这一设计带来的实际价值可通过白皮书的核心数据直观体现:
在112G高速信号场景下,SerDes链路长度缩短30%以上,直接消除了线缆引入的6.5dB插损,让端到端链路插损余量大于3dB,大幅降低了误码率,为TB级互联带宽提供了稳定的物理支撑;
无线缆设计直接释放了机柜内部的宝贵空间,让标准机柜可集成64/128卡甚至更多GPU,实现了单位空间算力密度的跨越式提升;
同时从根源上减少了线缆松动、老化导致的宕机风险,将系统故障修复时间MTTR从传统的小时级缩短至分钟级,完美适配AI大模型7×24小时不间断训练的高可靠性需求;
此外,交换板内集成参数面leaf交换,省去了传统组网所需的leaf层级交换机、光模块和光纤,在简化系统架构的同时,显著降低了组网的硬件成本与复杂度。
相较于行业内其他正交架构方案,中兴OEX架构的无集中式背板设计,进一步降低了层间损耗与硬件复杂度,成为当前高密度GPU互联的优质物理架构选择。
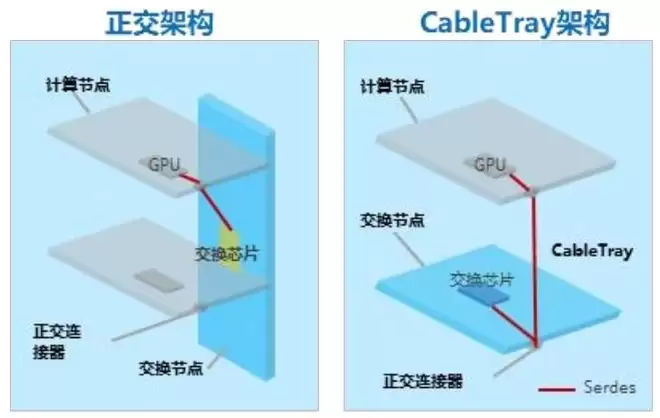
图2 OEX与Cable Tray方案对比
高速互联技术创新
自研芯片+全维度优化,打通算力协同通信瓶颈
GPU间的高效互联是系统级算力协同的核心支撑,传统GPU集群的「通信卡脖子」问题,本质是互联带宽、时延、协议兼容性的多重限制,而中兴通讯依托其在通信领域数十年的技术积累,从芯片、物理层、协议层、计算卸载、扩展性五个维度实现了高速互联技术的全面创新,打造出适配AI算力需求的TB级通信通道,从第三方视角来看,这一系列创新将通信领域的技术优势与智算需求深度结合,真正解决了多GPU协同通信的核心痛点。
在核心硬件上,中兴自研大容量交换芯片,成为高速互联的基石,该芯片实现了三大突破:
带宽与时延跃升至TB级、百纳秒级,满足海量AI数据的高速传输;
拓扑架构从点对点升级为大规模全对等互联,适配数十到数百颗GPU的协同计算;
全面兼容RDMA、CLink、OISA、Ethlink、SUE、UEC等国内外主流互联协议,为后续多厂家GPU兼容埋下伏笔。
在物理层选型上,中兴放弃了传统PCIe总线,选择以太网物理层,白皮书数据显示,PCIe 5.0 x16双向带宽仅约128GB/s,而以太网SerDes主流速率已达112Gbps,224Gbps产品已进入商用阶段,支持多通道灵活绑定,可轻松实现TB/s级端口带宽,完美契合AI训练对超高带宽的需求。
在协议层,中兴立足开放架构,既支持UALink、ESUN等国际主流开放协议,又积极参与工信部牵头的CLink协议制定,推动国内算力互联协议的统一,打破私有协议的生态壁垒。
同时,中兴将在网计算技术深度集成至交换芯片,将GPU的高负载通信操作卸载至交换芯片完成,让GPU专注核心计算,这一设计的优化效果十分显著:
在传统稠密模型训练中,All-Reduce操作复杂度从O(logN)降至O(C),大幅减少节点间消息传递次数;
在MoE混合专家模型训练中,Dispatch Multicast和Combine Reduce操作的分发时延下降20%-50%,归约时延下降40%-60%以上,干线流量减少超30%,彻底解决了MoE模型通信开销大的行业难题。
此外,中兴从互联协议、拓扑、物理形态、介质四个维度做Scale-Up可扩展性设计,预留GPU ID标识bit位满足未来十万级GPU集群寻址需求,采用线性无收敛扩展拓扑避免通信瓶颈,以机柜为单元做模块化设计实现「即插即用」扩容,遵循「能铜尽铜,距远用光」原则兼顾传输效率与成本,为算力的无限扩展提供了技术支撑。
功耗管理创新
液冷+高压直流,适配高密度算力的能源需求
超节点的高密度GPU集成,必然带来功耗的指数级增长,白皮书援引英伟达的数据显示,GPU超节点机柜功耗已从2024年H100的50kW,提升至2025年GB300 NVL72的120-150kW,未来更将向600kW乃至兆瓦级演进,功耗与散热问题成为高密度算力建设的必解难题。
从第三方视角来看,中兴超节点并未简单采用常规的散热与供电方案,而是结合算力发展趋势,打造了一套「前瞻布局、全维度适配」的功耗管理体系,从散热和供电两大维度实现创新,确保算力高效释放的同时,实现能效最优。
在散热方面,中兴构建了全维度的液冷散热体系,兼顾当前需求与未来趋势:
当前阶段采用单相冷板式液冷,这一方案是目前应用最广泛、工程化最成熟的液冷技术,市场占有率超过70%-80%,可有效支撑百千瓦级机柜的散热需求;
针对未来单芯片功耗突破2000W的趋势,未来规划硅基微通道冷板和两相冷板液冷技术,硅基微通道冷板适配HBM堆叠、Chiplet等先进封装的高热流密度需求,两相冷板液冷可在低流量下实现超高散热效率;
同时兼容浸没式液冷技术,为未来兆瓦级机柜的散热需求提供解决方案。
液冷技术的全面应用,不仅解决了高密度算力的散热问题,更推动数据中心从「算力导向」向「能效导向」转型,契合绿色智算的行业发展趋势。
在供电方面,中兴突破传统48V/54V供电体系的物理极限,采用HVDC高压直流供电架构,主流演进方向为±400V DC和800V DC,这一设计带来的优势十分突出:同等功率下,电流可降低8-16倍,铜材用量减少40%-50%,为机柜内的计算与冷却组件释放关键空间;有效抑制传输热损,整体端到端供电效率提升3%-5%,在电力成本占比30%-50%的智算中心,这一提升能带来显著的运营成本节约;可轻松支撑从当前100-150kW向250kW乃至1MW+级机柜的演进需求;减少中间能量变换层级,从根本上缓解功率因数校正与无功功率管理压力。
该架构与OCP Diablo 400、英伟达800VDC等行业主流趋势接轨,确保了供电体系的前瞻性与兼容性。
集群扩展创新:Nebula Matrix集群超节点,实现算力规模化平滑升级
单台单体超节点的算力终究有限,面对万亿乃至十万亿参数大模型的训练需求,算力的规模化扩展成为必然要求,而传统算力集群的扩展往往面临性能下降、成本激增、组网复杂等问题。
从第三方视角来看,中兴超节点的一大亮点,就是构建了「单体超节点-集群超节点」的完整扩展体系,通过Nebula Matrix集群超节点实现算力从百卡到万卡的平滑扩展,既满足了超大规模算力需求,又实现了性能与成本的最优平衡。
中兴Matrix集群超节点采用业界主流的「电交换+光互联」技术路线,通过高性能电交换机实现机柜内GPU间的互联,受铜缆传输距离限制,跨机柜场景则采用光纤介质完成互联,这一路线依托电交换技术的高成熟度、高业务普适性,规避了全光交换技术门槛高、生态不完善、对业务适配要求高的问题,成为当前大规模集群超节点建设的最优选择。
基于这一路线,中兴现有Nebula X32单体超节点可灵活扩展为Nebula Matrix X256/800集群超节点,面向未来,依托更高密度的Nebula X128单体超节点,更可进一步扩展至X8192/16384的超大规模集群,充分满足超大规模模型训练的算力需求。
同时,中兴创新提出Scale-Up与Scale-Out网络融合设计,打破了传统两类网络独立组网的模式,Scale-Up网络承载张量并行、专家并行等对带宽和时延要求极高的通信流量,Scale-Out网络承载数据并行、流水并行等对网络性能要求相对较低的通信流量,融合后构建统一的超节点互联网络,既满足了集群超节点内部的高性能互联需求,又适配了集群间的常规互联需求。
白皮书的模型测算显示,这一融合架构相比独立组网模式,能显著降低总拥有成本(TCO),同时保障了集群部署和扩容的平滑性,让用户可根据算力需求按需扩展,真正实现了「算力灵活选择,性能与成本最佳平衡」。
软件栈创新
打造超节点「操作系统」,充分释放硬件算力潜能
硬件是算力的物理基础,而软件是释放硬件算力的核心支撑,再好的硬件架构,若缺乏适配的软件体系,也无法将物理算力转化为实际的有效算力。
从第三方视角来看,中兴超节点的一大设计亮点,就是充分重视软硬件的协同优化,打造了一套深度协同、全栈优化的软件栈体系,将其定义为超节点的「操作系统」,实现了对硬件资源的统一调度、管理、优化与监控,确保物理层的所有创新都能转化为实际的算力输出。
这套软件栈的创新体现在六大核心维度:
一是实现统一虚拟化资源池与智能编排,将超节点内的算力、内存、存储资源抽象池化,根据AI训练、推理等不同工作负载需求,动态弹性分配和隔离资源,支持多任务、多租户环境下的共享与安全隔离;
二是做到极致通信优化与拓扑感知,通过深度优化的通信库和运行时系统,自动识别最优数据传输路径,结合计算与通信重叠、梯度压缩等技术,将通信开销隐藏于计算过程之中,提升系统整体效率;
三是支持异构计算统一调度与编译器优化,实现CPU/GPU/DSA等异构单元的统一调度,通过算子融合、内核生成等方式提升单卡效率与跨芯片协同效率;
四是构建全栈可观测性与智能运维体系,实现芯片-节点-集群的多级监控,实时可视化功耗、温度、性能等指标,结合AI运维实现故障预测、根因分析,将故障定位时间从小时级缩短至分钟级;
五是设置高可靠冗余机制,通过冗余算力节点与故障切换机制,避免单点故障导致的大模型训练中断,保障业务连续性;
六是引入「算力-电力」协同的绿色调度,结合任务优先级、功耗模型与实时电价,动态调整算力调度与芯片频率,在保障服务水平协议(SLA)的前提下,平滑功率波动,降低能耗与运营成本。
此外,中兴还打造了算力仿真平台,为超节点的算力配置提供「数字孪生」推演能力,该平台基于硬件参数、模型结构、算子实测数据,可模拟不同超节点形态下的训练/推理性能,为用户的硬件选型、并行策略设计提供科学依据。
白皮书以Qwen3-235B模型为例,通过算力仿真平台得出结论:在2K卡的规模下,256卡超节点相比8卡服务器,训练性能提升15%,这一结果能有效帮助用户规避试错成本,实现算力配置的最优选择。
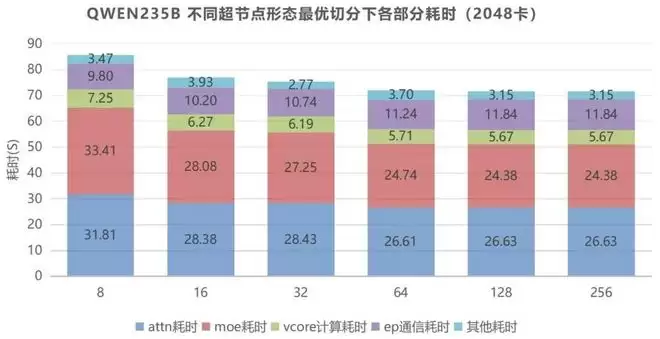
图3 Qwen3-235B不同超节点形态最优切分下各部分耗时
多维度设计
实现多厂家GPU兼容,打破生态锁定
在各大厂商纷纷构建封闭算力生态的背景下,中兴超节点将多厂家GPU兼容作为核心创新点之一,这一设计不仅是其「绕开GPU瓶颈、另辟蹊径」的重要体现,更契合了行业开放、融合、创新的发展趋势。
从第三方视角来看,中兴超节点并非简单实现多厂家GPU的「接入」,而是通过硬件、芯片、协议、生态、集群五个维度的系统化设计,真正打破了单一GPU厂商的生态锁定,为用户提供了灵活的算力选择,也推动了国产GPU生态的繁荣发展。
在硬件层,中兴Nebula单体超节点的OEX正交架构采用高度组件化设计,将GPU适配的核心模块独立为UBB模组,针对不同厂家的GPU,用户仅需更换UBB模组,无需对超节点的整体架构、交换托盘、供电散热等核心部件做任何改动,即可实现「即插即用」的适配,大幅降低了多厂家GPU的集成门槛。
在芯片层,自研的大容量交换芯片成为多厂家GPU兼容的硬件核心,该芯片全面兼容国内外主流的GPU互联协议,而目前国内外主流GPU厂商的产品均已适配这些通用协议,从底层解决了多厂家GPU的通信兼容问题,打造了「一次设计,多卡兼容」的通用互联底座。
在协议层,中兴不仅是现有互联协议的适配者,更是行业标准的制定者,积极参与工信部牵头的CLink协议制定,推动形成统一的国内算力互联标准,同时其自研的OLink协议采用开放标准设计,向行业开放协议规范,让各GPU厂商可轻松适配。
在生态层,中兴秉持「开放解耦」的理念,全面开放OEX正交架构的机械与电气接口规范,第三方GPU厂商只需按照该规范设计计算/交换托盘,即可实现与中兴超节点的标准化接入,无需单独定制;同时,中兴已于2025年6月在ODCC网络工作组成功立项《基于正交架构的超节点硬件系统》,推动超节点硬件的行业标准化,让多厂家GPU的兼容从企业设计升级为行业规范。
在集群层,多厂家GPU的兼容能力更延伸至Nebula Matrix集群超节点,其Scale-Up/Scale-Out融合组网架构继承了单体超节点的协议兼容和组件化适配能力,无论组成集群的各单体超节点搭载不同厂家GPU,还是同一超节点内混布多品牌GPU,都能通过自研大容量交换芯片的多协议支持、融合网络的统一调度,实现跨机柜、跨品牌GPU的高带宽、低时延协同,让多厂家GPU的规模化组网成为现实。
小结
从第三方视角对中兴超节点技术进行全面解读后可以发现,中兴通讯始终围绕「做TCO最优算力系统级整合者」这一核心定位,跳出传统的芯片研发竞赛,从系统级协同架构出发,通过硬件架构、高速互联、功耗管理、集群扩展、软件栈、多厂家GPU兼容六大维度的全方位创新,成功绕开了单GPU芯片的性能瓶颈,拼出了AI算力的系统级最优解。
这份创新的价值,不仅体现在具体的技术指标提升上——白皮书数据显示,MoE模型分发时延下降20%-50%、归约时延下降40%-60%以上,更体现在对算力建设模式的重构上:中兴超节点让算力建设从「芯片堆叠」走向「协同释放」,从「单一硬件性能竞争」走向「全栈系统优化」,并以此为核心打造了「AI工厂」,将AI开发从传统的「手工作坊」升级为标准化、规模化、自动化的「现代化流水线」,为AI大模型的训练与推理提供了高效的算力底座。
更重要的是,中兴超节点的开放兼容设计,打破了单一厂商的生态锁定,为用户提供了灵活的GPU选择,推动了智算行业的开放与融合。
正如中兴超节点技术白皮书中所言,未来算力的竞争不再是「每秒浮点运算次数(FLOPS)」的竞争,而是「每瓦Token数」的竞争,中兴超节点通过系统级的创新设计,实现了算力效率、扩展能力、生态兼容性的多重最优,不仅为自身在智算行业占据了一席之地,更为整个智算行业的发展提供了全新的思路与方向。
在AI大模型持续发展的背景下,中兴超节点技术的落地与推广,必将为千行百业的智能化升级提供坚实的算力支撑,推动智算基础设施向更高效率、更绿色、更开放的方向演进。
