过去一周全网都在养那只红色卡通龙虾 OpenClaw。作为能够自己动手干活的 AI 智能体,有人花几千块请它回家,几天后账号被盗、文件被删,又花几百块请人卸载。从排队安装到扎堆卸载只隔了一周。
虾到底该怎么养?北京大学博士、美国普林斯顿大学博士后研究员杨灵(合作导师为王梦迪教授)和团队成员(王胤杰博士等人)给出一个让虾越养越好、越养越聪明的答案。

图 | 杨灵(来源:受访者)
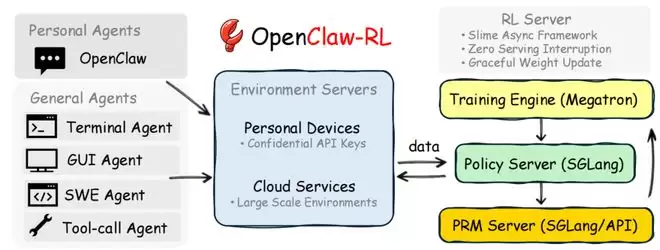
几天前,杨灵等人发布了一个名为 OpenClaw-RL 的开源框架,核心逻辑非常简单但颇具洞察,你和 AI 的每一次对话本身就是最好的训练数据。这套系统让 AI 正常服务用户的同时,后台有四个完全解耦的模块在异步运转:策略服务、轨迹收集、过程奖励评估与参数训练,彼此互不阻塞。
(来源:https://arxiv.org/pdf/2603.10165)
杨灵告诉 DeepTech:“我们这次聚焦的是个性化场景下的在线强化学习。这个方向之前很少有人系统性地研究,主要原因是缺少自然产生的交互数据,学术界很难构造可复现的 benchmark,工业界也缺少端到端的训练闭环。”
“我们这次的工作相当于为这个方向提供了第一套完整的基础设施和方法论,从数据收集、信号提取到策略优化,形成了一个可落地的闭环,同时也提出了一些新的研究视角。”其表示。
这套系统的核心洞察在于重新审视了一个被长期忽视的资源:AI 每执行一次动作之后,都会收到一个"下一状态"(next state),用户的回复、工具的输出、测试的结果、界面的变化,这些全部是信号。现有系统只是把这些信号当做下一轮对话的上下文输入,但 OpenClaw-RL 的观点是,它们本质上是对上一步动作质量最直接、最丰富的反馈,完全可以在不需要任何人工标注的情况下,转化为强化学习的训练信号。
(来源:https://arxiv.org/pdf/2603.10165)
这些信号里藏着两种截然不同的信息:
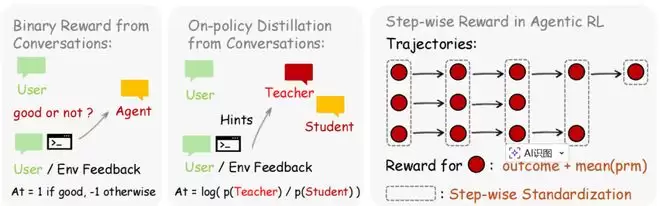
第一种是评估性信号。用户满意就给正分,不满意就给负分;用户重复提问往往意味着不满,测试通过则意味着成功。这些信号被一个名为"过程奖励模型"(Process Reward Model, PRM)的裁判模块捕捉。
为了提高判断的鲁棒性,系统对每一步动作进行多次独立评估,然后通过多数表决机制,将结果转换成+1(好)、-1(差)或 0(中性)的标量奖励。与传统强化学习只在任务结束时给出一个最终分数不同,这种逐步评估的方式让训练信号密集了一个数量级,策略模型可以精确知道是哪一步做对了、哪一步做错了。
第二种是指导性信号。当用户对 AI 说"你应该先检查文件再编辑",这不只是一个差评,它在告诉 AI 具体哪里做错了、应该怎么改。然而,仅靠+1/-1 的标量奖励根本无法传递这种细粒度的纠正信息:它只能说"你错了",却说不清"错在哪里、该怎么改"。
为此,杨灵和团队设计了一种名为“基于提示的在线策略蒸馏”(Hindsight-Guided On-Policy Distillation, OPD)的方法。其核心思路巧妙而直觉:当下一条用户回复到来时,系统中的裁判模块会从中提炼一句可操作的"事后提示"(hindsight hint),例如“应该先检查文件是否存在再执行编辑操作”。然后,系统把这条提示附加到原来的对话历史中,构造出一个"增强版提示"。
关键来了:系统并不让模型重新生成一版回答,而是让同一个模型在增强版提示下重新评估原始回答中每一个词的生成概率。如果某个词在"知道提示之后"的概率变高了,说明这个词说对了,模型应当加强;反之如果概率降低了,说明这个词不够好,应当抑制。这种逐词级别的方向性信号远比一个简单的“好/坏”分数丰富得多,它不仅告诉模型"你错了",还精确指出"哪个词该多说、哪个词该少说"。
这两种方法互为补充:评估性信号覆盖范围广,几乎每一轮对话都能产生奖励信号,虽然粒度较粗但胜在无处不在;指导性信号则只有在用户提供了具有纠正意义的反馈时才会触发,出现频率较低但信息密度极高。论文实验表明,将两者结合使用时,效果显著优于单独使用任何一种方法。
(来源:https://arxiv.org/pdf/2603.10165)
研究中,他们在以下两个模拟场景里做了测试:
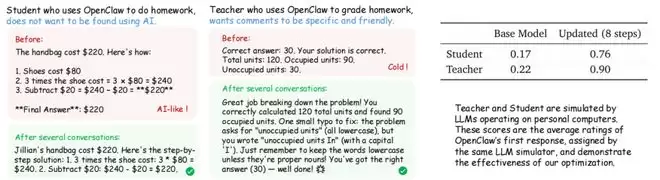
一个是让学生使用 AI 写作业,要求是别让老师看出来是 AI 写的(当然现实生活中不鼓励大家这样使用)。另一个是让老师用 AI 批改作业,要求评语要具体又友善。
在老师使用 AI 批改作业的那个例子里,一开始 AI 只会回答“正确,做得很好”。但在经过 24 轮优化之后它会写下“你把 3 周转成 21 天这一步很多同学会漏掉,但是你处理得很准确”这样的评语,同时还配上了表情符号,非常符合人类世界所倡导的夸奖要具体而真实的做法。
OpenClaw-RL 在工程上的另一个突破是将 AI 训练从传统的"停服更新"变成了"边用边学"。整个系统采用全异步架构:策略服务器持续响应新的用户请求,轨迹收集器同步截取训练所需的数据,裁判模块并发地给前一个回答打分,而训练器则在后台持续更新参数。
当参数更新完成时,系统会短暂暂停数据提交、加载新权重,然后无缝恢复服务。整个过程中没有任何组件需要等待其他组件完成,用户端感受到的是零中断的连续服务。
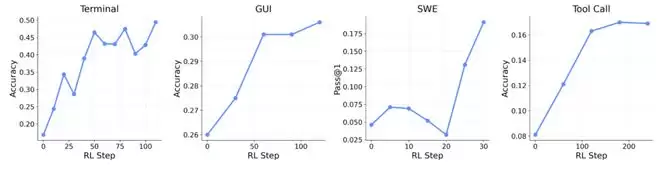
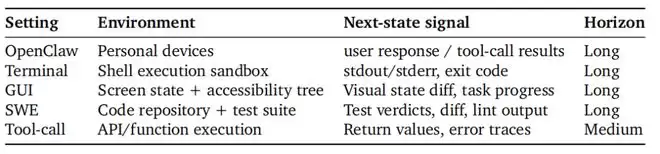
他们还把 OpenClaw-RL 应用到了更加复杂的通用智能体场景,涵盖终端操作(128 个并行环境)、图形界面操作(64 个)、代码编写(64 个)和工具调用(32 个)四大类任务。在工具调用任务上,同时使用过程奖励和结果奖励两种信号,准确率从基线的 17% 一路提升到 76%,这意味着同一个模型在持续交互中完成了超过 4 倍的性能跃升。
(来源:https://arxiv.org/pdf/2603.10165)
据杨灵介绍,这套训练框架的一个重要发现是:来自不同 Agent 场景(终端、GUI、代码、工具调用)的交互数据可以放在同一个框架中联合训练,并且模型在各个维度上都呈现出整体性的上升趋势。"这意味着统一的 Agent 强化学习训练是可行的,"杨灵说,"如果这条路能走通,对于构建真正通用的 AI 智能体会是一个非常关键的基础。
因为通用智能体最终要面对不同种类的任务、场景和用户需求,一套统一且可扩展的训练框架是必要条件。据我们所知,这种跨场景联合训练 Agent 的视角之前还没有被系统性地探索过。"
(来源:https://arxiv.org/pdf/2603.10165)
“事实上,这项研究从 idea 提出到开源,我们只花了三天。当然必要的沟通不能少,但在现在这个时代,有些想法从出来到实现,真的可以很快。”杨灵表示。
他补充称:"不过在这个大家都在拼速度的时代,我觉得对问题的判断力和研究品味反而更重要。选择做什么、不做什么,能不能识别出真正有长期价值的问题,这些决定了一个研究方向最终能走多远。执行力当然也关键,不只是说模型能不能跑出好的数字,而是整套系统能不能真正落地、让人用起来。"
在应用前景上,杨灵认为 OpenClaw-RL 有两个最有价值的落地方向。
第一个是隐私敏感的本地化场景。例如政府部门、金融机构和医疗机构,这些场景不可能将数据传输给外部的大模型 API,但同样有强烈的 AI 智能体需求。OpenClaw-RL 提供了一条可行路径:在本地部署模型,通过日常使用中的自然交互持续优化,数据全程不出本地。
"第二个方向是工业级的大规模 Agent 训练,"杨灵说,"目前开源的 Agent 训练框架很多只针对单一场景做优化。我们的系统从设计之初就是跨场景的,终端、GUI、代码、工具调用可以在同一套框架里联合训练。这意味着它的架构天然适合扩展到工业规模的多场景 Agent 优化。"
论文发布后,杨灵收到了来自学术界和工业界的诸多合作邀约。团队计划沿两条线并行推进。研究方面,他们希望将 next-state learning 这一范式做深做透,不仅限于策略优化,还将拓展到 Agent 的记忆系统和技能积累机制,最终目标是构建一套能在持续交互中自主进化的完整 Agent 学习体系。工程与应用方面,他们计划在更大规模和更多真实场景上验证框架的可扩展性,并与有实际 Agent 部署需求的企业展开合作。
谈到下一步,杨灵表示:"一方面我们希望大幅降低使用门槛,让个性化 Agent 训练变成一个开箱即用的事情,现在很多人连 OpenClaw 都装不明白,更别说跑强化学习了。我们会持续改善文档和工具链,目标是让普通开发者也能用上这套技术。
另一方面是 next-state learning 这个范式本身的纵深推进,目前我们只挖掘了其中的评估性信号和指导性信号,但 next-state 里其实还蕴含着预测性信号,也就是 Agent 能不能学会预判自己的动作会导致什么后果。如果这一层也能打通,Agent 就不再是被动等反馈,而是主动规避已知的失败模式。
而且这套范式天然是跨场景的,对话、工具调用、代码编写、图形界面操作这四类任务产生的 next-state 虽然形态各异,但都可以纳入同一个学习框架。这是一个非常有潜力的方向,我们正在积极推进。"
参考资料:
相关论文 https://arxiv.org/pdf/2603.10165
运营/排版:何晨龙




