
7 毛的电经过显卡生成 Token 就能 18 块卖给美国人?
没错,这段时间地球另一端的电脑里,国产 AI 大模型正在 OpenRouter 上大杀四方。
要知道,这可是全球最大的 AI 模型聚合平台,就像买游戏大家上 Steam,买 Token 一般就选 OpenRouter 了。
上面每天各种模型的使用量加起来超过 1 万亿 Token,一直以来大半份额都被美国模型牢牢占据。
但国产模型近期表现异常强劲,据每日经济新闻统计,今年 2 月份,国产模型的调用量三周大涨 127%,首次超越美国。
尤其在 2 月 9 日至 15 日这周,国产模型以 4.12 万亿 Token 的惊人调用量,超越了同期美国模型的 2.94 万亿 Token,实现了历史性的赶超。
这可是 AI 啊,这种在别人家最引以为傲的地盘上啪啪打人脸的新闻,听起来确实带派。
而众所周知,AI 的尽头是算力,算力的尽头是电力,想满足全球数十亿人的需求,明显需要非常庞大的电力。
同样的一度电,费劲吧啦的拉电网搞基建才能卖个几毛,算进电解铝冶炼里顶多卖两块。
可换成 Token 出海直接就翻了几十倍,妥妥的降维打击,再加上光速运输、超低损耗、无视关税,一下子大家开始纷纷下场,把这 Token 背后燃烧的电力搬上台来。
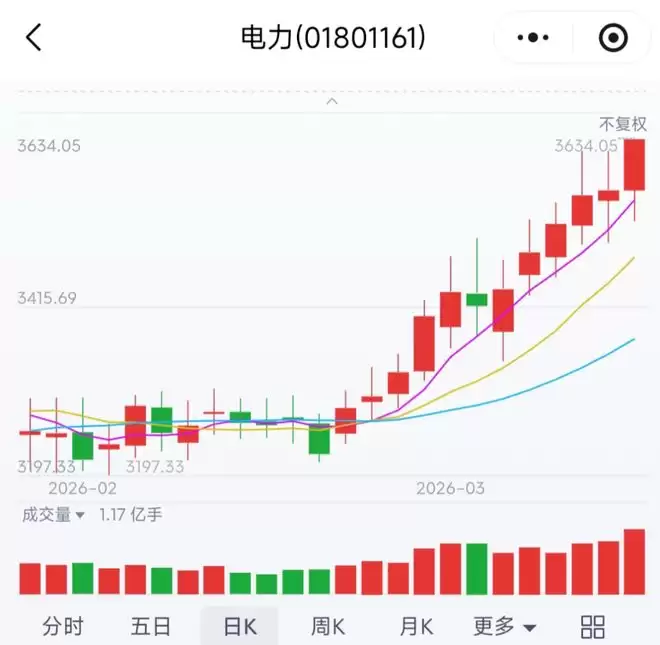
看着 A 股一路飘红的电力板,似乎借着 Token,把中国的电卖给全世界真就指日可待了。
那这波 Token 到底有没有带着电力一起出海呢?
翻完资料算完账世超发现,前景确实诱人,条件嘛有待商榷。
这波 Token 大卖其实最主要的原因就是那个搅动 AI 界的开源项目:OpenClaw。
因为这只大龙虾每次干活,就要消耗大量 Token,连带着全世界消费者的 Token 消耗量都一起蹭蹭涨。
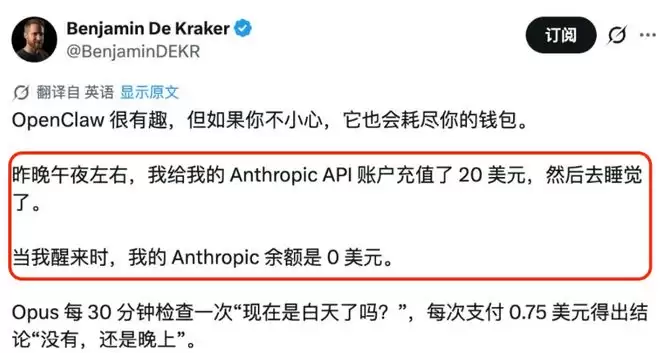
有网友就抱怨过,刚充的 20 刀 Token 余额,想着设定个小任务慢慢跑,结果第二天起床一看,花光了。。。
再加上项目前些天刚刚登顶 Github 星标榜历史第一,眼看着要迎来更多新用户,这 Token 开销如流水的日子想必还要持续一段时间。
这个时候,国产模型量大管饱的优点就凸显出来了,比起美国那些用着肉疼的模型,咱这不仅价格便宜足足十几倍,干起活儿来还没差多少,那用脚投票都知道该选什么模型了。
也就导致 OpenRouter 上的模型调用数据,前五个里住进了三个雷打不动的国产模型:MiniMax M2.5,Kimi K2.5 和 DeepSeek V3.2,虽偶尔起伏,但始终在榜。
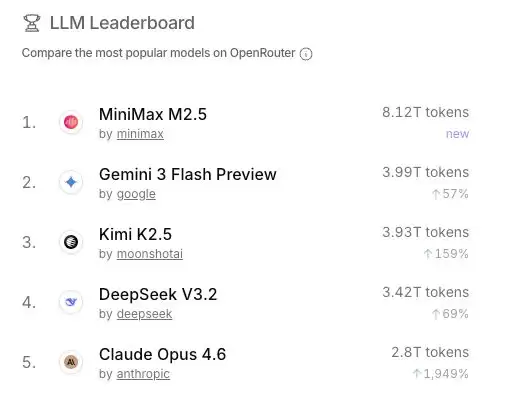
这么一看,Token 出海的市场表现是相当来劲儿,那伴随着的,就是电力出海也有了充足的未来预期。
世超是赶紧打开计算机捣鼓了起来,拿 DeepSeek V3.2 来举例,之前就有人算过,每 Token 生成需要约 0.4 焦耳能量,那 7 毛一度的电,算上损耗,就能生成约 600 万的 Token,按市场价就是 18 块钱呐。
好家伙,25 倍的价差,这哪是充足的预期,这得给电力拉得起飞了啊。
但再回想对比一下现在的这点儿声量,明显哪里不对啊。
于是世超又继续在 OpenRouter 正式扒拉了起来,这一扒拉,就发现了猫腻。
原来模型是国产的没错,但产 Token 的电就说不准儿了,根据服务器地址统计,很多 Token 的算力来源其实是美国的机房。
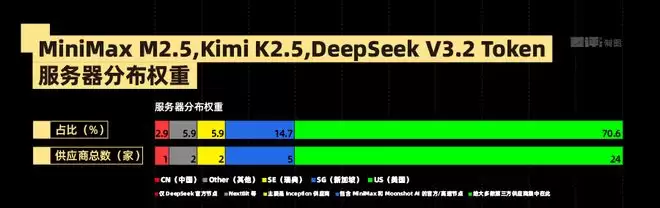
比如 MiniMax M2.5 的 Token 服务器,地址就基本以美国为主。而三个头部国产模型,只有 DeepSeek 一家有一个明确的国内服务器。
当然,不排除有一部分可能是中转的国内算力,但更多的部分确实来自海外的供应商。
所以简单点说,现阶段的 Token 出海一大部分是中国的模型外国的电,只能说是模型出海,距离算力出海和电力出海还有段距离。
好家伙,规划了半天出口中国电力,结果都没咋用上,那还卖给全世界个锤子,敢情是“未来可欺”啊。
但现在又有了个新问题,为啥这中国模型非得跑到美国去算,而不是带着电力一起出海呢?
其实这事儿挺好解释的,跟其他行业没啥两样。
就是法律合规、成本控制以及用户体验综合起来的商业化原因,很现实,也很直接。
美国那地儿,不说差友们也都清楚,总喜欢动不动拿数据安全来说事儿,放 AI 模型这儿也不例外。
美国第 14117 号行政令的核心内容就是禁止或限制向“关注国家”(包括中国)传输批量敏感个人数据,包括基因、生物识别、个人健康、地理位置、金融数据等等。

如果 AI 模型涉及处理这些敏感数据,且服务器位于中国,就会直接面临被禁的风险。
除了法律合规的需求,还有算力芯片的考量,由于国内难以获得最高能效比的顶尖制程芯片,所以在推理效率上肯定要落后最新一代很多的。
就比如英伟达 B200 ,同等单位下推理能效足足有 H100 的 25 倍,既快又便宜,这差距一下就拉开了。

所以如果面向全球市场,目前的标准操作模式是:
研发在国内(使用国产卡或存量卡)+ 推理在海外(租用海外算力)+ 运营主体隔离。
比如拿海外成绩非常亮眼的 Talkie 来说,定位是跟 AI 互动聊天的手机应用,用户超五千万,每天都需要消耗海量的 Token。
他们用的是 MiniMax 自家训练的模型,但推理的算力服务器是租自美国的供应商,如亚马逊、谷歌或者微软,数据同样存在美国的服务器上。
这样一方面可以避免用户跟 AI 交互时延迟过高,毕竟谁也不想说句话等半天才有回复;另一方面也符合美国的法规要求。
至于日常运营,是在新加坡注册的子公司负责,能规避更多的潜在风险,正符合这套标准的出海打法。

也就是说,咱们默认的那种美国人电脑上敲个回车,中国这边算力中心就库库耗电跑 Token,跑好再卖到大洋那边电脑上的场景基本不会发生。
但是,事情并非没有转机。。。
在继续研究了一些资料后,世超发现,虽然现在条件欠妥,但在未来,通过卖 Token 实现电力出口的路,其实并没被完全堵死。
一方面,美国虽然缺电,但不是简单的缺发电量,而是一种结构性缺电。
像马斯克那样简单的建几个电厂能应付一时,但对于规划里源源不断的算力中心来说,仍然是杯水车薪。
结构性缺电是美国几十年来电力基础设施老化的历史遗留,叠加老美不像咱能集中力量办大事儿的国情,这电力基建的差距,根本不是三两年能追上的。
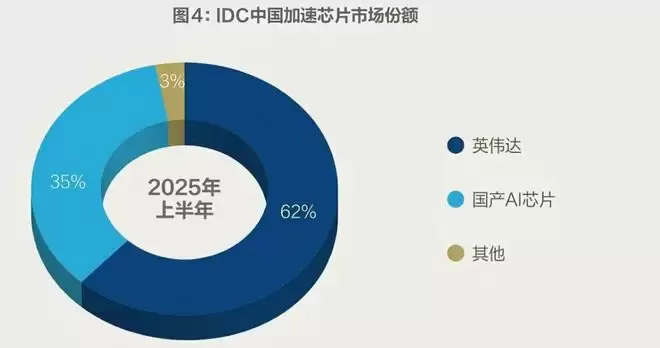
另一方面,近些年国产 GPU 一直在迅速成长,无论是新上市的芯片四小龙,还是闷头做事的带头大哥华为昇腾,都在悄悄抢占大模型在推理端的市场。
据 IDC 2025 年的市场调研,国产 AI 芯片在英伟达的垄断下增长到了 35% 左右的市场份额,早已不再是 PPT 里的备胎,而是真的能买来干活的主力。
注:IDC称,2025上半年中国加速芯片的市场规模达到190万张,资料来源:《中国半年度加速计算市场(2025上半年)跟踪》《财经》整理
再说了,AI 大基建时代才刚刚开始,全世界都缺算力。
闲置绿电这波虽然搭不上 Token 出海的快车,但我国几十年积累的电力基建还是很能打的。
随着模型能力提升的速度逐渐放缓,当我们算力芯片的脚步跟上时,这便宜大碗的电力,可能真会成为划分市场份额的关键一手,带着国产模型一起去撬动更大的利润。
撰文: 风华
编辑: 江江 & 面线
美编: 焕妍
图片、资料来源:
IDC,OpenRouter,arXiv,uvation,X,部分图源网络





