
机器之心编辑部
电子游戏一直是 AI 领域发展的极大推动力之一。
游戏本身就构建了一个相对完整的世界,并且具有相当易于理解的世界规则。不仅可以训练人工智能对物理世界的理解,训练智能体的交互,更是许多世界模型的构建基础。
研究与视觉相关的 AI 永远绕不开的电子游戏两座大山,其一是代表真实世界风格的《GTA》 ,另一个则是代表虚拟自由风格的《我的世界》。
我们关注到,谢赛宁团队最近在探索世界模型的全新研究方向,把实验目标投向了《我的世界》。




Solaris 模型样本。每一行显示一个生成的视频:左右两侧是模型为每个玩家生成的第一人称视图,中间是模型的第三人称真实视图(未提供给模型)。
视频画面中清楚地展示了两个游戏角色的行为与第一视角的游玩录像。但如果告诉你,这两个第一视角画面均为视频世界模型生成的,你能找到破绽吗?
这就是谢赛宁团队的最新视频世界模型 Solaris,首个多人视频世界模型,能够同时生成多个玩家之间保持一致的第一视角。

项目主页: https://solaris-wm.github.io/引擎代码: https://github.com/solaris-wm/solaris-engine模型代码 :https://github.com/solaris-wm/solaris数据集链接:https://huggingface.co/collections/nyu-visionx/solaris-data模型链接:https://huggingface.co/collections/nyu-visionx/solaris-models
研究团队发现,目前的视频世界模型仅能处理单人视角,这并不能反映现实世界的真实运作方式,希望能够能够实现多人同步观察一个统一世界。于是,研究团队把视角投向了电子游戏。
Solaris 的核心贡献之一是我们完全自主设计并构建的多人数据采集系统 SolarisEngine,因为现有平台仅针对单人设定而设计。该引擎支持在《我的世界》等游戏中进行协调的多智能体交互和同步视觉捕捉。它是一个可扩展的框架,由 12.6M 帧协调的《我的世界》游戏游玩数据创建。
模型与数据集
SolarisEngine

利用 SolarisEngine 采集的多人数据集任务示例。每一列展示了不同的任务类型(建筑、搭桥、PvP、PvE、追逐、探索、采矿和采集),每种任务包含三个回合。此处展示的第三人称视角仅用于可视化;SolarisEngine 实际渲染的是第一人称观察视角和动作数据,这也是模型训练所使用的输入。
目前已有多种用于控制 Minecraft 智能体的框架,包括 Malmo、MineRL、MineDojo 和 Mineflayer。尽管这些工具各具特色,但没有一个是为多人数据采集而设计的。市面上没有现成的系统可以用来采集真实的多人游戏数据,因此研究团队选择从零开始搭建一个。
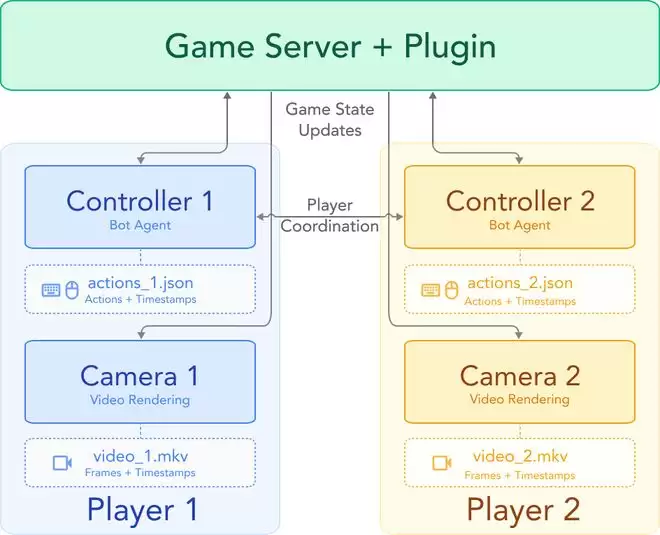
SolarisEngine 架构概览。
在数据采集上,研究团队选择以 Mineflayer 为基础,因为它为寻路、方块放置和战斗等操作提供了可组合的基本方法。在此之上,我们构建了一个通信层,允许机器人在任务回合中相互协作。通过这些基础方法的组合,可以形成完整的任务回合,让两个机器人共同完成预设目标。
研究团队构建了一个任务类型库,涵盖了 Minecraft 交互的核心方面:建造房屋和桥梁、PvP 与 PvE 战斗、追逐与探索,以及采矿。尽管任务逻辑是用这些高级原语编写的,但系统会将所有操作转换为低级动作空间,从而兼容从人类玩家那里采集的单人数据集 VPT。
在覆盖游玩动作以外,要构建世界模型的数据集,必须实现提取视觉画面并与动作的对齐。
Mineflayer 虽然能控制角色,但无法渲染图形。为了获取视觉观察数据,团队将每个控制机器人与一个运行最新 Minecraft Java 版客户端的摄像机机器人配对。通过自定义的服务端插件,我们实现了摄像机与控制器的实时同步,使其位置、朝向甚至动作动画完全一致。在后期处理中,我们利用共享的 20 FPS 帧率时间戳,将动作与视觉观察数据进行对齐。
利用 SolarisEngine,团队采集了一个多人 Minecraft 训练数据集,总计包含 9,240 个任务回合,每名玩家贡献 632 万帧,总计 1,264 万帧。
这些任务回合大致分为四大类:建筑(房屋、墙壁、塔楼、桥梁)、战斗(PvP 和 PvE)、移动(追逐、导航、探索)以及采矿。在采样任务类型时,团队采用了与典型任务长度成反比的权重,以保持整体分布平衡。所有动作均被标注为与 VPT 格式兼容的语义游戏事件,涵盖了移动、视角控制以及挖掘、放置、攻击等交互输入。
这是首个带有动作标注、适用于训练世界模型的多人 Minecraft 数据集。
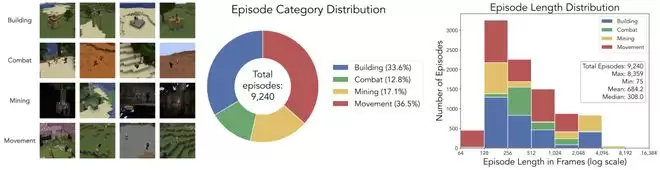
数据集统计。(左)数据集包含四个场景类别。(中)在总共 9,240 个场景和每个玩家 6.32M 帧的情况下,场景类型分布。(右)场景长度分布,大多数场景在 128 到 512 帧之间。
视频世界模型 Solaris
Solaris 是一种可控的视频扩散模型,它能够在给定各玩家历史观察与动作的条件下,联合预测多名玩家的未来观察结果。结合了流匹配(Flow Matching)与扩散强迫(Diffusion Forcing)对其进行训练,其中每个玩家及每个时间步都会采样独立的噪声水平。这使得模型在学习对各玩家观察流进行去噪的同时,保持玩家间的一致性。
研究团队基于 MatrixGame 2.0 构建了该模型,是一个在包括 Minecraft 在内的多种视频游戏上预训练过的单人视频 DiT 模型。研究团队沿用了其预训练权重和冻结的 VAE,并进行了三项关键改进以支持多人模式。
首先,扩展了动作空间以涵盖来自 VPT 的全量 Minecraft 输入,增加了动作条件模块的输入维度。
其次,引入了多人自注意力层,将所有玩家的 Token 进行拼接并互相对照,使得信息可以在每个 DiT 模块内部实现玩家间的交换。对每名玩家独立应用 3D RoPE ,并添加了可学习的玩家 ID 嵌入,以便模型区分不同个体。
第三,所有其他模块(用于首帧条件的交叉注意力、前馈层、动作条件)均保持与 MatrixGame 2.0 一致,并对每名玩家独立运行。尽管我们目前仅在两名玩家的数据上进行训练,但该架构可泛化至任意数量的玩家。
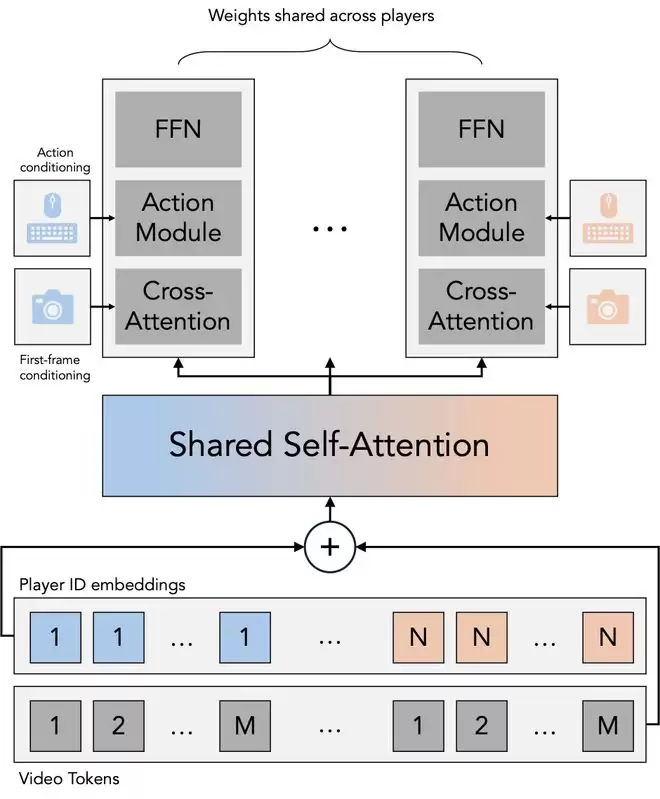
改进型 DiT 模块通过在序列维度上进行视觉交错(visual interleaving)来实现多人建模。多人信息通过一个共享的自注意力(self-attention)模块进行交换。其他模块与 MatrixGame 2.0 保持一致,并对每名玩家独立应用。
评估指标与实验结果
研究团队创建了 Solaris Eval 数据集,通过 7 个独特的、不参与训练的真值任务回合,来测试五种多人协作能力。
首先是移动能力:该部分测试了模型同时在两名玩家视角中渲染视觉一致的智能体位移(WASD)和相机旋转(鼠标)的能力。其中一个机器人移动,另一个观察;由 VLM(视觉语言模型)判断移动玩家的位置在观察者视角中是否发生了正确且一致的变化。
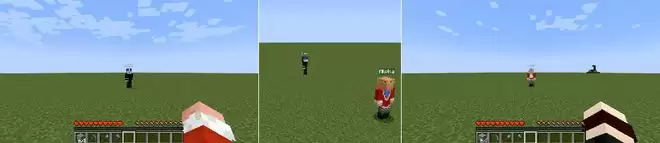
第二是定位能力:测试模型是否能够通过观察记住另一名玩家的位置。一名智能体转身(失去对另一名玩家的视野),停顿,然后转回原位。由于转身的智能体一直处于静止玩家的持续观察中,它应当知道对方所处的位置 ——VLM 会检查该智能体在转回时是否能看到另一名玩家。
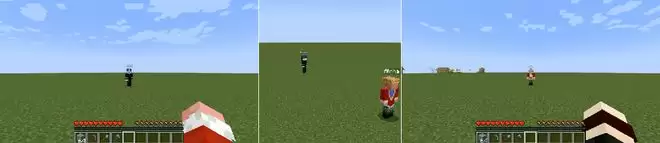
第三是一致性:测试协同可见区域在两名玩家视角中是否渲染一致。两名靠近的智能体同时转向同一个随机方向;VLM 会检查两名玩家看到的场景是否相同。

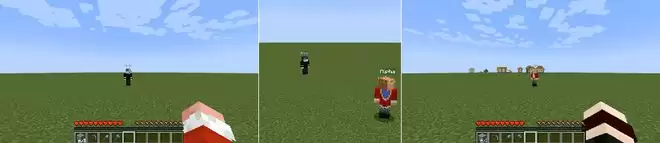
第四是记忆能力:测试模型是否能够跨越时间记住环境和其他智能体。两名智能体同时背对彼此转身,停顿,然后转回原始朝向。VLM(视觉语言模型)会检查两名智能体在转回后是否能重新看到对方。
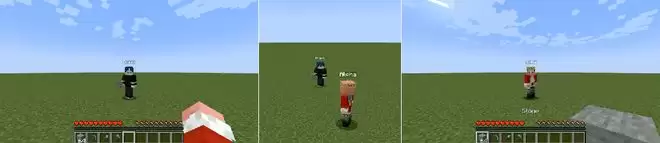
第五是建造能力:测试模型反映由智能体动作引起的环境变化的能力。一个机器人构建预定义的形状(正方形、水平长条或垂直长条),另一个机器人在旁观察。建造完成后,建筑机器人移动到观察者身边,使完整的结构同时出现在两者的视野中。VLM(视觉语言模型)会评估观察者是否看到了完整的结构。
实验结果
研究团队将本研究的架构实现与 Multiverse 的「帧拼接(frame concatenation)」方法进行了对比,后者是本工作之前唯一现存的多人世界模型。此外,我们还通过对比「无单人模型初始化」的变体,测试了单人阶段预训练的必要性。
我们的方法在视觉效果和所有评估类别的定量指标上均表现更优。在基于运动轨迹的动作执行方面,所有架构变体均表现强劲,并在对应类别的 VLM 评估中获得高分(见表)。但在涉及建筑、场景一致性和玩家视觉对齐等困难场景时,我们的方法展现出了卓越的性能,这体现在这些类别中更高的 VLM 评分上。尽管「帧拼接法」在我们的「移动(Movement)」评估中表现更好,但定性分析发现,该方法在面临「无操作(no-op)」动作时会出现动作幻觉。
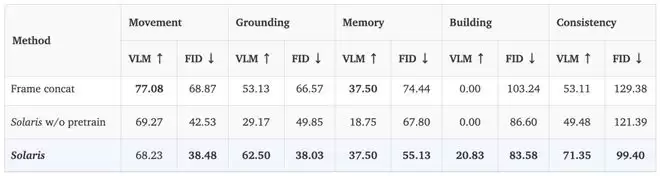
跨任务的定量比较。本文的方法与 Multiverse 沿通道维度连接玩家观察结果的方法进行比较。
更多信息,请参阅原始论文。