
视觉世界模型 “VideoWorld 2” 由豆包大模型团队与北京交通大学联合提出。不同于 Sora 2 、Veo 3、Wan 2.2 等主流多模态模型,VideoWorld 系列工作在业界首次实现无需依赖语言模型,即可认知世界。
现有的模型大多依赖语言或标签数据学习知识。然而,语言并不能捕捉真实世界中的所有知识。例如,复杂的动态变化、空间关系以及背后的物理规律等,难以通过语言清晰表达。
正如李飞飞教授所说, “幼儿可以不依靠语言理解真实世界”,VideoWorld 系列 仅通过 “视觉信息”,即浏览视频数据,就能让机器掌握推理、规划和决策等复杂能力。在新作 VideoWorld 2 中,模型进一步扩展到真实场景,能够仅浏览视频,掌握长达 1 分钟的复杂手工制作任务,并已入选顶级会议 CVPR 2026
AI 可以直接从视频中学习真实世界中的复杂技能吗?就像人类可以仅靠浏览视频学习折纸、搭乐高积木等技巧。
豆包大模型团队与北京交通大学联合提出了 VideoWorld 2,一种通用视觉世界模型,旨在不依赖语言模型,仅靠浏览视频,掌握复杂、长时序的真实世界知识。
正如李飞飞教授在其演讲中所言,视觉能力的出现引发了寒武纪生命大爆发,进而推动了智能的飞跃式发展。VideoWorld 2 通过研究使 AI 直接从真实视频中学习复杂任务知识,探索了 AI 智能的边界。
VideoWorld 2 揭示了直接从真实视频中学习的关键在于解耦关键动作和无关视觉细节,并据此提出一种动态增强型潜动态模型,将真实世界视频中的复杂外观与任务核心动作解耦,显著提升复杂长时序任务的学习效率和效果。
仅通过浏览教程视频,VideoWorld 2 即可完成诸如折纸和搭积木等长达一分钟的复杂手工制作任务。这些任务涉及当前 AI 难以掌握的细粒度操作与长程规划能力。VideoWorld 2 的成功率远高于目前最先进的技术(例如 Sora 2、Veo 3 和 Wan 2.2),成功率提升超过 70%,而后者几乎无法完成这样的复杂任务。此外,它还能将这些技能迁移至多种未见场景,并实现跨环境的多任务机器人操控。
团队认为,尽管面向真实世界中的视频知识学习与技能泛化仍存在很大挑战, VideoWorld 2 有潜力从视频数据中学习更多样和复杂的任务技能。
目前,该项目论文被 CVPR 2026 录用,代码与模型已开源,欢迎体验交流。

论文链接:https://arxiv.org/abs/2602.10102项目主页:https://maverickren.github.io/VideoWorld2.github.io/X 链接:https://x.com/XiaojieJin/status/2024469936363991162?s=20
现有 AI 难以从真实世界视频中学习知识
面向本次研究,团队构建了两个实验环境:视频手工制作和视频机器人操控。
其中,手工制作视频包含多种场景下的精细动作与环境变化,如纸张的不规则形变、视角切换与遮挡等。同时,这些视频时长达分钟级别,包含多个连续的操作步骤。相比娱乐向视频,手工制作可以作为一个评估模型复杂知识学习能力的理想测试环境。
同时,团队还选取了机器人任务,以考察模型在理解控制规则和规划任务方面的能力。
在模型训练环节,团队要求模型 “观看” 教程视频数据,以此得到一个可以根据过往观测,预测未来画面的视频生成器。
在测试阶段,团队要求模型在新的环境下,生成训练集中展示的任务技巧,并转换为准确连贯的视频。对于需要具体动作输出的任务,模型可以在浏览大量视频后,额外训练一个轻量的动作预测头,充分发挥从视频中预先学习的知识。
团队首先测试了主流的视频生成模型,如 Sora2,Veo3 和 Wan2.2 等。如下图右侧所示,这些模型虽然善于生成精美的画面,但是全部无法生成完整准确的折纸任务。
团队又测试了系列工作中的初代模型 VideoWorld。 VideoWorld 主要为模拟场景下的视频知识学习设计,如视频围棋和模拟机器人操控,外观与动作均较简单。虽然 VideoWorld 的任务成功率更高,但输出仍包含大量错误的动作。
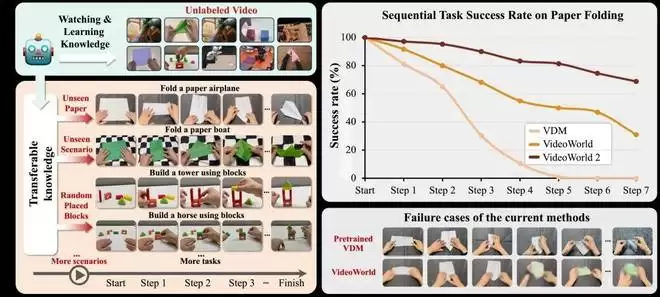
团队将这归因于 —— 模型难以充分解耦嵌入在视觉变化中的任务核心动作,过拟合到了无关细节。例如,相机的抖动,光影变化与无关外观细节。这种过拟合会降低长距离生成的稳定性与准确性。
相反,人类可以轻松地从复杂的外观变化中提取关键的任务动态。
增强视觉动态解耦能力,提升视频学习效果
根据上述观测,团队提出 VideoWorld 2,旨在通过显示的增强对外观与动作信息的解耦,提升知识学习的鲁棒性。
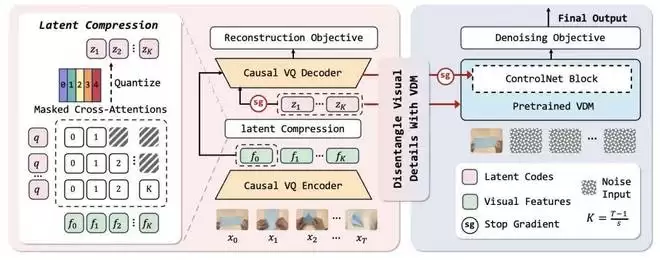
为此,VideoWorld 2 引入了一个动态增强型潜动态模型(dLDM, dynamic-enhanced Latent Dynamic Model), 可提取视频中的任务核心动作并压缩为紧凑的潜在编码,提高模型的知识学习效果。
dLDM 包含一个 MAGVITv2 风格的编码器 - 解码器结构以及一个预训练的视频生成模型(VDM, Video Diffusion Model)。编解码器将未来的视频变化压缩为紧凑的潜在编码,VDM 则负责将潜在编码渲染为视频。
对于一个视频片段,编码器先以因果方式提取每帧特征图,并定义了一组注意力模块和对应可学习向量。每个向量通过注意力机制捕捉第一帧至后续固定帧的动态变化信息,然后通过 FSQ 量化。其中,量化器作为信息筛选器,防止模型简单记忆后续帧原始内容,而非压缩关键动态信息。
接下来,这些潜在编码会作为 VDM 的条件输入,以因果交叉注意力的形式与 VDM 进行交互,基于去噪扩散方式被渲染回视频。
由于 VDM 具有丰富的外观先验知识,潜在编码可以仅关注紧凑的、可泛化的动作信息,而不过拟合至无关外观细节。
初代 VideoWorld 中仅使用编码器 - 解码器结构来压缩视频变化,并重建视频。由于解码器结构不包含外观先验知识,其重建优化目标易为扰潜在编码引入环境噪声,难以充分解耦真实环境下的复杂外观与任务动作信息。
通过将 VDM 作为外观渲染器,VideoWorld 2 实现了紧凑且鲁棒的视觉表示,可以捕捉复杂、长距离视觉序列中的核心动态信息,这对于真实世界中的推理规划任务至关重要。
同时,团队并未完全摒弃原始的解码器结构,仍要求其利用首帧特征图与帧间视觉变化编码来重建后续帧,并阻断了该过程向潜在编码的梯度回传。由于梯度被截断,解码器的重建任务不会干扰潜在编码的学习;同时,其重建的粗粒度视频动态可作为辅助信息输入 VDM,从而稳定训练,使 VDM 能够专注于外观渲染,无需从零开始学习任务动态信息。
下图为 dLDM 的模型架构:
通过引入 dLDM,在无需任何文本描述的情况下,VideoWorld 2 即可以在各种环境下完成长达一分钟以上的连贯折纸、搭积木等手工制作任务,并可以应用至机器人操控场景。
从更多视频中学习,提取通用技能
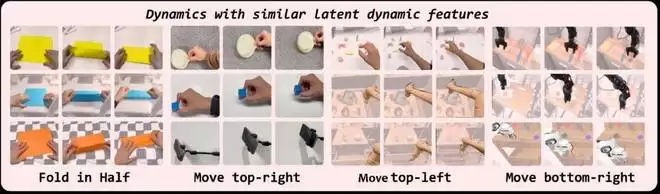
针对 dLDM 视频学习效果的原因,团队进行了以下分析,并发现 dLDM 可以从大量真实世界视频中提取相似的运动模式
下图展示了 dLDM 在大量真实世界视频上训练后,对潜在空间中距离相近编码所属视频片段的可视化结果。
可以看出,这些编码表达了相同的运动模式(如不同方向的位移、折纸中的通用动作等)。尽管它们所处的环境和实体各不相同,但在潜在空间中具有相似的表达,这极大程度上有助于模型学习可泛化的策略。
进一步地,团队对潜在编码进行了 UMAP 可视化(见下图),其中每个数据点代表一个潜在编码。
UMAP 作为一种主流的降维算法,能够将高维数据映射至低维空间,从而直观展示模型的特征表征能力。图中点的物理距离越近,表明其在原始高维空间中的相似度越高。
团队可视化了在 CALVIN 和 BRIDGE 两个环境中学习到的潜在编码。尽管这两个环境外观差异显著(前者为仿真环境,后者为真实世界视频),但它们具有相似的动作空间(如机械臂的定向位移)。
如下图所示,左侧为 VideoWorld 2 提取的潜在编码,右侧为前作 VideoWorld 的结果。对比可见,对于跨环境的相似机械臂运动,VideoWorld 2 在潜在空间中呈现出更显著的聚类趋势,其表现明显优于 VideoWorld。这表明模型能够更好地提取跨场景的共性,掌握更具泛化性的策略知识。

团队认为,视觉能力是自然界中生物智能实现跨越式演化的重要推动力。对于 AI 而言,从视觉中学习和理解真实世界知识,或许是迈向更高阶智能的重要途径。
未来,团队将致力于从视觉中学习和理解真实世界的复杂知识结构,构建能够自主感知、推理与行动的更强大的通用智能体。
作者介绍:

任中伟:VideoWorld 项目核心成员,北京交通大学计算机学院博士生。目前在字节跳动大模型团队实习,期间在 CVPR 顶级会议上发表多篇论文,并受邀担任了 CVPR,ICCV 等多个顶级会议审稿人。研究方向包括多模态感知与推理、世界模型、视频生成等。

靳潇杰:VideoWorld 系列项目负责人,现任北京交通大学计算机学院教授 / 博导,国家高层次青年人才,曾任字节跳动美国研究院创始成员和技术负责人。研究方向为多模态智能、世界模型、高效深度学习等。