编辑 | 王凤枝
OpenAI又毫无征兆地发布了新模型。
距离GPT-5.3 Instant上线仅仅过去两天,GPT-5.4便被正式推出。它在API层面首次获得了原生电脑操作能力,让AI能够像人类一样自主控制键鼠,跨越各类应用软件执行具体任务。
不仅如此,ChatGPT也正式与Excel和Google Sheets等生产力工具实现了深度绑定。你可以在电子表格中直接调用它,将数据更新和财务分析全盘交由它来处理。
对于每天周旋于表格与文档之间的职场人来说,这个模型的现实意义极其明确:AI不再仅仅是个聊天工具,它已经正式下场替你干活了。
虽然有早期测试者吐槽它的前端交互体验依然略逊于核心竞品,但在这种极具统治力的自动化执行力面前,这点UI层面的短板已经显得无足轻重。
01两个版本,覆盖不同需求
GPT-5.4这次分两个版本上线。
GPT-5.4 Thinking面向付费订阅用户,ChatGPT Plus(20美元/月)、Team和Pro用户现在就能用。它会在回答问题前先展示思考计划,用户可以中途打断、调整方向,不用从头再来。对于复杂问题,它能思考更长时间,同时保持上下文理解不跑偏。
GPT-5.4 Pro则留给需求更硬的用户,包括ChatGPT Pro(200美元/月)和Enterprise企业版。OpenAI的说法是,这是为最复杂任务准备的,追求性能上限。免费用户也有机会体验它,但只有系统觉得必要时才会自动路由过去。
在API端,GPT-5.4支持100万token上下文窗口,是OpenAI目前给到的最大容量。整本代码库、整份长合同可以一次性扔进去。
但有个细节要注意:输入一旦超过27.2万token,超出的部分按两倍费率计费。
02原生电脑操控,AI开始像人一样用电脑
这次最核心的升级,是GPT-5.4在API和Codex里第一次内置了原生电脑操作能力。
以前AI只能生成文本、代码让你自己拿去用。现在它可以自己调用Playwright这类库写代码操控电脑,也可以直接看屏幕截图,发出鼠标和键盘指令。开发者还能配置自定义确认策略,针对不同风险场景调整它的行为。
OpenAI表示,这是他们首个具备这种能力的通用模型,对于开发智能体的开发者来说,这是目前可用的最佳选择。
几个基准测试最能说明问题:
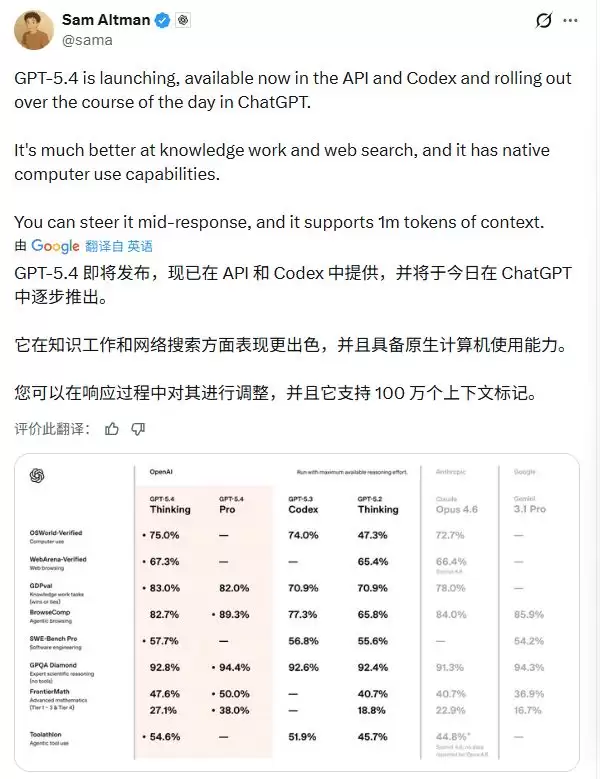
在测试桌面导航能力的OSWorld-Verified上,GPT-5.4的成功率达到75.0%,不仅远超GPT-5.2的47.3%,还超过了72.4%的人类基准水平。这个测试衡量的是模型通过屏幕截图加键盘鼠标操作在桌面环境里导航的能力。
在浏览器操控测试WebArena-Verified上,同时用DOM和截图驱动交互时,它做到了67.3%的成功率,GPT-5.2是65.4%。而在Online-Mind2Web上,只靠截图观察,它的成功率达到了92.8%,远高于ChatGPT Atlas智能体模式的70.9%。
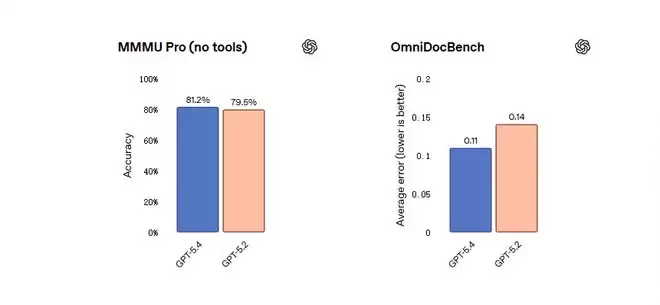
计算机使用能力的提升,跟视觉感知能力的改进分不开。在测试模型视觉理解和推理的MMMU-Pro上,GPT-5.4在不使用工具的情况下达到81.2%的成功率,高于GPT-5.2的79.5%。在文档解析测试OmniDocBench上,GPT-5.4的平均误差是0.109,优于GPT-5.2的0.140,而且这是在没开推理努力的情况下跑出来的,反映的是低成本、低延迟状态下的性能。
高分辨率图像的理解也有升级。从GPT-5.4开始,OpenAI引入了一个原始图像输入细节级别,支持最高1024万总像素或6000像素最大维度的全保真感知。高细节级别现在也支持到256万总像素或2048像素最大维度。早期测试里,使用原始或高细节时,定位能力、图像理解、点击准确性都有明显提升。
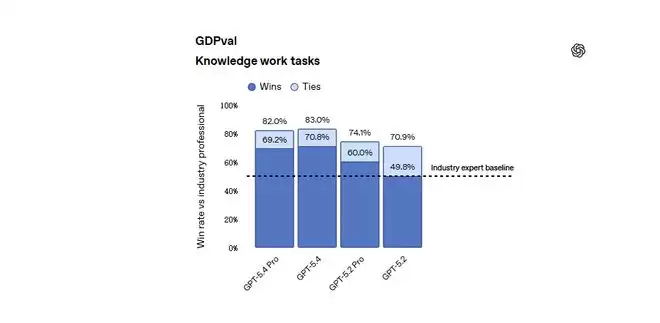
在GDPval这个测试覆盖44个职业的知识工作任务中,GPT-5.4在83.0%的比较里达到或超过行业专业人士水平,其中69.2%是胜出,13.8%是打平。GPT-5.2是70.9%(49.8%胜,21.1%平)。GPT-5.4 Pro的胜率为82.0%,GPT-5.2 Pro是74.1%。测试里包含的行业覆盖了美国GDP贡献前9大行业。
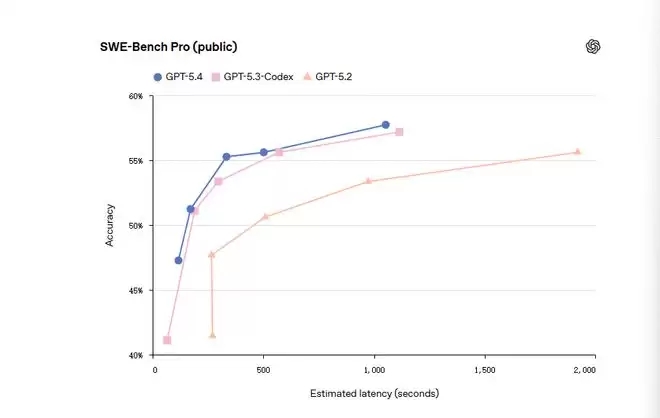
在SWE-Bench Pro编码测试里,GPT-5.4得分57.7%,GPT-5.3 Codex是56.8%,GPT-5.2是55.6%。更重要的是延迟表现:在达到相似或更高准确率的情况下,GPT-5.4的估计延迟在500至800秒左右,而GPT-5.3 Codex是1800秒以上。延迟估计考虑了工具调用时间、采样token和输入token。
OpenAI拿用户之前标记过事实错误的去标识化提示词跑了一遍。GPT-5.4的单项陈述错误率比GPT-5.2低了33%,完整回应里出现任意错误的概率低了18%。OpenAI说这是他们迄今最具事实准确性的模型。
GitHub首席产品官马里奥·罗德里格斯(Mario Rodriguez)的评价是,GPT-5.4在逻辑推理和执行复杂多步骤工具依赖工作流方面表现突出,是企业第一天就该采用的模型。
房地产科技公司Mainstay的CEO多德·弗雷泽(Dod Fraser)透露,在覆盖约3万个房产税门户的测试中,GPT-5.4首次尝试成功率95%,三次内成功率100%,而之前的计算机操控模型只有73%到79%。GPT-5.4的完成速度快了大概3倍,token消耗少了约70%。

AI招聘与专家训练平台Mercor的联合创始人兼CEO布伦丹·富迪(Brendan Foody)也给了评价,APEX-Agents最新测试显示,GPT-5.4平均得分首次突破50%,三个月飙升15.7%。而一年前,顶尖模型连Excel都改不好,得分不足5%。AI能力正以超预期速度逼近顶级专业机构水平。

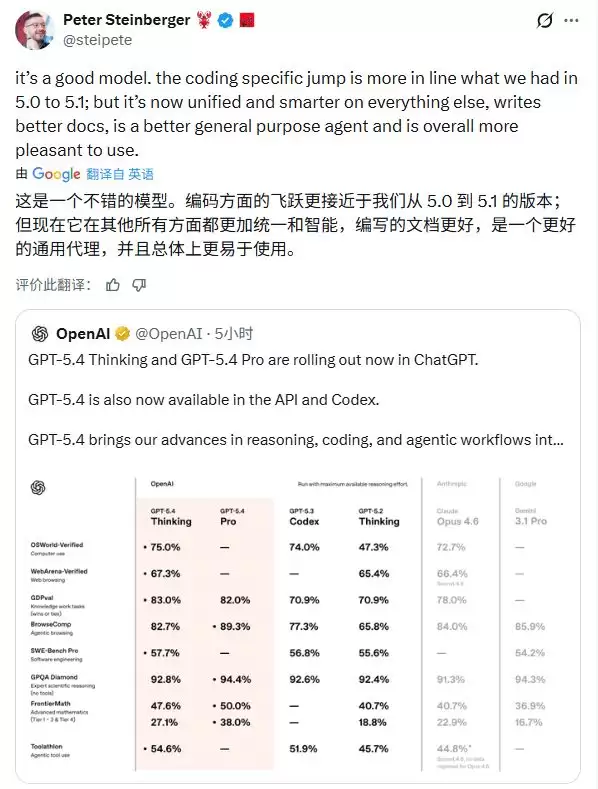
OpenClaw创始人彼得·斯坦伯格(Peter Steinberger)的看法更偏务实,GPT-5.4在延续编码优势的基础上,实现了全方位的均衡提升,文档编写更专业,通用代理能力更强,整体体验也更友好。
Cursor的开发者教育副总裁李·罗宾逊(Lee Robinson)说,GPT-5.4在他们内部基准测试里处于领先地位。“我们的工程师发现它比以前模型更自然、更果断。它会处理模糊的问题而不自我怀疑,会主动并行化工作保持进展。”
03工具搜索,把token尽量省下来
在工具调用方面,以前有个痛点:模型每次请求都得把所有工具定义塞进提示词里。如果系统里工具多,一次请求可能多花几千甚至几万token,成本高、速度慢、还把上下文塞得满满的。
GPT-5.4在API里引入了工具搜索(Tool Search)机制,彻底改变了这套玩法。
现在模型只接收一个轻量级的工具列表,配一个搜索功能。真需要使用时,它再去检索完整定义,按需拉取。这对那些可能包含几万token工具定义的MCP服务器来说,效率提升很明显。
OpenAI给出的数据显示,在Scale的MCP Atlas基准测试里跑了250个任务,启用全部36个MCP服务器。工具搜索模式跟把所有MCP功能直接暴露在上下文里的模式相比,准确率一样,但总token用量少了47%。
具体数字是这样的:不用工具搜索的情况下,平均总token消耗为123139,用了之后降到65320。
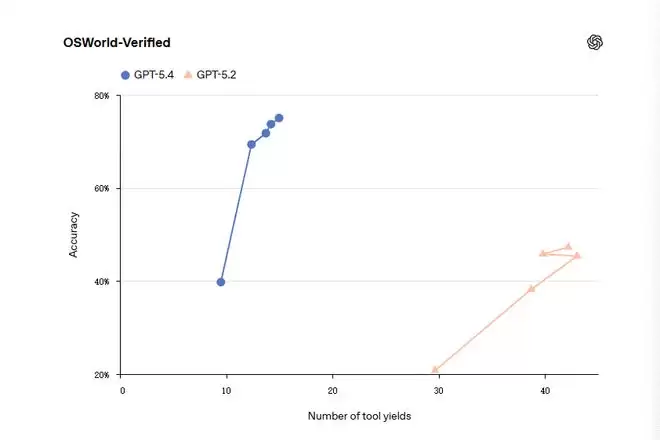
工具调用的准确率和效率也有提升。在Toolathlon测试里,它测的是AI智能体用真实世界工具和API完成多步骤任务的能力,比如读邮件、提取附件、上传、评分、记到表格里等,GPT-5.4用更少的工具让步(Tool Yields)达到了更高的准确率。
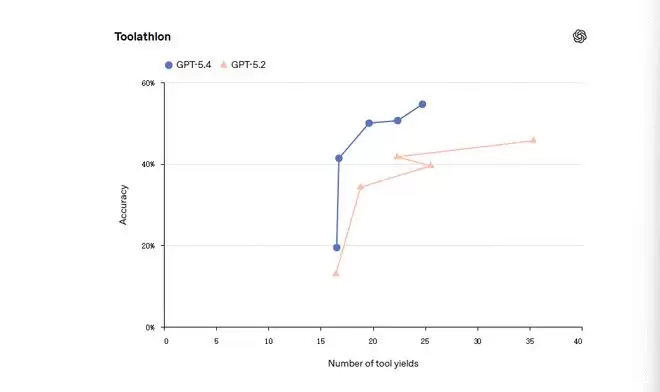
所谓工具让步,是指当AI在等待工具响应时会让出控制权,这叫一次让步。如果并行调用3个工具,再并行调用3个,让步次数是2。它比工具调用次数更能反映延迟,因为体现了并行化的好处。在Toolathlon上,GPT-5.4在约10次让步时准确率55%左右,GPT-5.2只有46%左右。
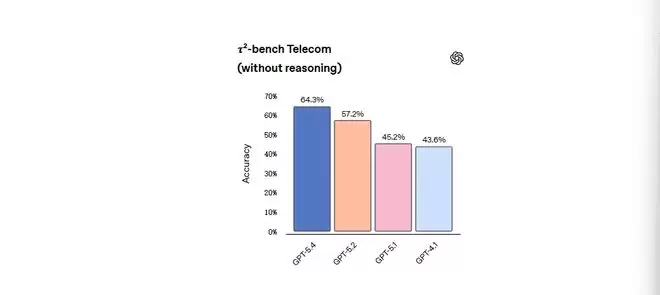
对于延迟敏感、不想开推理的场景,GPT-5.4也有提升。在τ²-bench电信测试里,模型要用工具完成客户服务任务,不开推理的情况下,GPT-5.4准确率64.3%,GPT-5.2是57.2%,GPT-5.1是45.2%,GPT-4.1是43.6%。
自动化软件服务公司Zapier的CEO韦德·福斯特(Wade Foster)说,GPT-5.4在他们跨几百个真实工作流的工具使用基准测试里表现很好。“GPT-5.4 xhigh是多步骤工具使用的新标杆,它完成了之前模型放弃的任务,是迄今为止最持久的模型。”
04 Excel深度集成,金融场景先落地
跟GPT-5.4同步上线的,还有一套面向企业和金融机构的OpenAI金融服务套件。
核心产品是ChatGPT for Excel和Google Sheets测试版。ChatGPT直接嵌进电子表格的单元格里,你可以让它帮你搭财务模型、做分析、更新数据。OpenAI表示,这是用团队已经依赖的公式和结构来工作。
套件还整合了FactSet、MSCI、Third Bridge、Moody's这些数据源,推出一套可复用的Skills功能,覆盖盈利预览、可比公司分析、DCF估值分析、投资备忘录撰写这些高频场景。
OpenAI特别专注于改进GPT-5.4创建和编辑电子表格、演示文稿和文档的能力。
OpenAI自己有个内部投行基准测试。GPT-5 Thinking在这个测试里的得分是43.7%,而GPT-5.4 Thinking直接干到了88.0%。
在另一个模拟初级投行分析师电子表格建模任务的测试里,GPT-5.4平均得分87.3%,GPT-5.2是68.4%。
投资公司Walleye Capital的AI解决方案主管丹尼尔·斯威基(Daniel Swiecki)称,在他们内部的财务和Excel评估里,GPT-5.4准确率提高了30个百分点。他把这归因于模型更新和情景分析的扩展自动化。
法律AI平台Harvey的应用研究主管尼科·格鲁彭(Niko Grupen)也评论道:GPT-5.4在他们BigLaw Bench评估里得分91%,“在结构化复杂交易分析、跨长篇合同保持准确性、提供法律从业者需要的高细节方面,目前比别的模型都好”。

05网络搜索能力大幅提升
GPT-5.4在智能体网络搜索方面也做了改进。
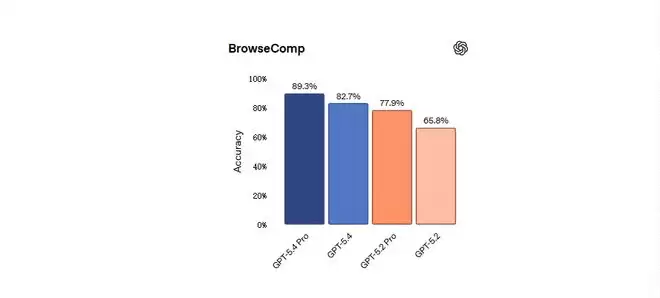
在BrowseComp测试里,衡量AI智能体能多持久地浏览网络,找到那些难找的信息时,GPT-5.4比GPT-5.2提升了17个百分点,GPT-5.4 Pro以89.3%的成绩创下该基准测试的新高。
OpenAI解释说,在BrowseComp里他们用了搜索阻止列表,排除了包含基准答案的 ,防止污染。GPT-5.4测试时间比GPT-5.2晚,分数变化反映了模型、搜索系统和互联网状态的变化。GPT-5.4用的是更长、更新的阻止列表。
落实到实际体验上,这意味着GPT-5.4 Thinking在回答那些需要从网上多个来源汇集信息的问题时更靠谱。它能更持久地跨多轮搜索,找到最相关的来源,特别是对那些大海捞针式的问题,然后把它们综合成清晰的答案。
06可引导性,能中途打断调整方向
ChatGPT里的GPT-5.4 Thinking多了个新功能:对于较长、较复杂的查询,它会先给一个工作概要,你可以看到它打算怎么干。
更重要的是,你可以在它响应过程中添加指令或调整方向,不用从头开始,也不用多轮对话。OpenAI说这能让模型输出更贴近你想要的结果。
这个功能现在在网页版和Android应用上能用,iOS即将上线。
模型在困难任务上也能思考更长时间,同时对对话早期步骤保持更强的意识。这意味着它能处理更长的工作流和更复杂的提示,同时保持答案的连贯性和相关性。
07反馈与体验:早期用户的真实感受
AI写作助手公司HyperWrite的CEO马特·舒默(Matt Shumer)提前试了GPT-5.4一周。他提到了一个有意思的细节:自己以前一直是Pro系列的重度用户,因为Pro几乎能完美应对所有任务。但这次,GPT-5.4标准版打破了这个习惯。

“即使在标准模式下,GPT-5.4也比之前的Pro版好,不可思议。”他说编码能力强得离谱,在Codex里可靠性惊人。“编码问题基本上解决了。”Pro版近乎完美,能解决其他模型解决不了的问题,但对日常使用来说性能有点过剩。
他也提到几个问题:前端界面体验不如Claude Opus 4.6和Gemini 3.1 Pro;会忽略一些显而易见的现实背景,比如规划旅行行程时选了春假期间人挤人的地点;在OpenClaw里测试时,程序经常在任务完成前突然停住。
但他最后给的结论是:整体上领先太多,那些吹毛求疵的小问题都显得无关紧要了。
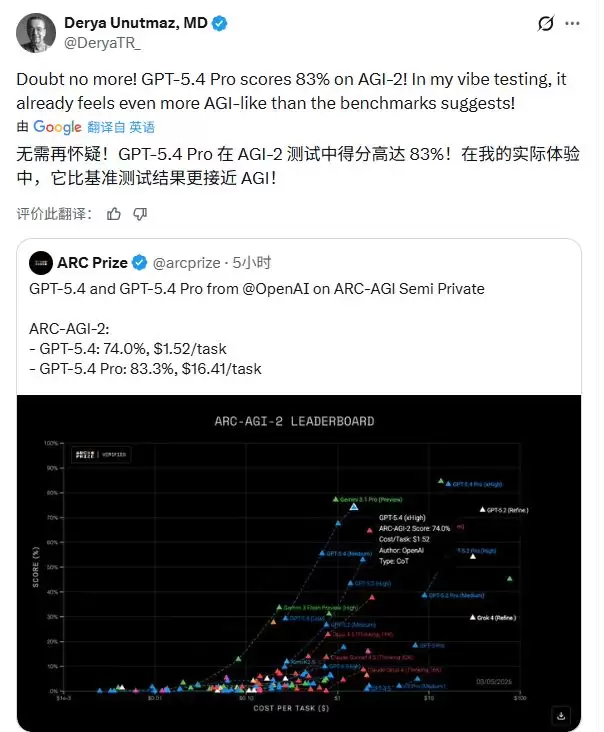
世界顶尖免疫学专家德里亚·乌努特马兹(Derya Unutmaz)也试了Pro版,用了几天。“它展现出了相对更高的创造力、洞察力和抽象智能,比5.2 Pro模型更频繁地提出问题。”他在AGI-2测试里给GPT-5.4 Pro打了83%的得分。
08定价:比以前贵,但值得
API定价上,GPT-5.4比GPT-5.2贵了一些。
GPT-5.4标准版每百万输入token为2.5美元、输出15美元;Pro版输入30美元、输出180美元。与之相比,GPT-5.2是输入1.75美元、输出14美元;GPT-5.2 Pro是输入21美元、输出168美元。
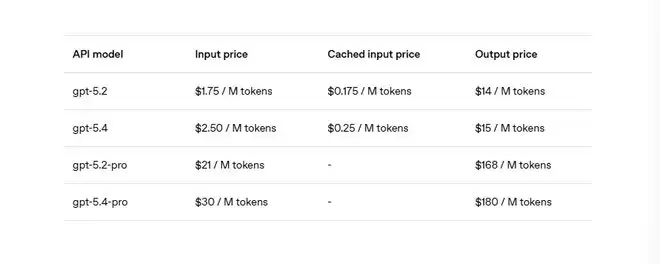
其中,输入超过27.2万token的部分,按两倍费率算。Codex里默认压缩上限就是27.2万token,开发者可以手动往上调,超出部分才触发高计费。
OpenAI发言人对此给出了三条理由:一是复杂任务能力更强,包括编码、电脑操控、深度研究、高级文档生成、工具调用;二是研究路线图上有重大技术进步;三是更高效的推理机制在相同任务上消耗更少推理token,能抵消一部分单价上涨。发言人说,即便提价,GPT-5.4的定价还是低于同等能力的竞品前沿模型。
在ChatGPT端,GPT-5.4 Thinking从3月5日起向Plus、Team及Pro用户开放,取代此前的GPT-5.2 Thinking。GPT-5.2 Thinking将在三个月后于2026年6月5日正式退役,期间可以在模型选择器的传统模型里找到。
GPT-5.4 Pro只对Pro和Enterprise计划用户开放,企业和教育版用户可通过管理员设置提前开启访问权限。
在安全方面,OpenAI把GPT-5.4定位为高网络能力模型,沿用了GPT-5.3 Codex的类似保护措施,包括监控系统、受信任访问控制,对零数据保留(ZDR)表面的高风险请求做异步阻断。
他们也在持续研究思维链(CoT)的可监控性。新开源的评估叫CoT可控性,测的是模型能不能故意混淆推理来逃避监控。结论是GPT-5.4 Thinking控制CoT的能力较低,这对安全来说是好事,说明CoT监控仍然有效。
写在最后
当你再次打开ChatGPT时,你面对的已经不再是一个仅仅擅长咬文嚼字的聊天机器人。
回看这两年的轨迹:从陪人聊天的对话框,到辅助敲代码的副手,再到今天直接接管鼠标键盘、接手复杂表格的数字员工。这次的GPT-5.4或许没有创造出全新的理论基座,但它把纸面上的潜能彻底变成了桌上的生产力。
技术革命往往不是伴随着巨响到来的,而是潜移默化地渗透进每一次版本更新里。等到我们真正察觉时,那个曾经只会回答问题的AI,其实已经悄无声息地坐上了你的工位。




