车载芯片告别高算力低智能,理想汽车如何破解困局

免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
当所有人都在卷算力的时候,理想汽车开始卷「数学定律」了。
作者|周永亮
编辑|郑玄
2026 年,智能辅助驾驶领域最大的谎言可能正在被戳破——「算力越大,车就一定越聪明」。
过去几年,车企们的军备竞赛逻辑一直很粗暴,谁的芯片算力高,谁的模型参数多,好像谁就站在食物链顶端。

但理想汽车最近放出的一篇论文,指向了一个完全不同的方向:不是比谁的算力大,而是比谁把算力用得狠,能把有限的大脑容量用得更聪明、更高效,这才是未来竞争的关键。
这篇与国创决策智能技术研究所联合发表的论文,提出了一个叫「软硬协同设计定律」的数学框架。名字听起来很学术,但它要解决的问题极其现实:在车上那块功耗有限、散热有限、成本有限的芯片里,怎么把大模型的智能榨到极致?
这不仅仅是一个工程优化技巧,也是理想为自研芯片「马赫 100」打下的理论基础。
01
解密「软硬协同设计定律」
聊技术之前,我们得先看清当下的行业困境。
当下,辅助驾驶的技术路线正在从规则驱动,全面转向以大语言模型为核心的 VLA(视觉-语言-行动)系统。简单说,你的车需要在本地跑一个「小型 GPT」,让它能看懂路况、理解场景、做出决策。
问题来了:云端大模型可以拿成千上万张 GPU 堆,但车上的芯片受功耗、散热和成本的约束,算力天花板是死的。
更麻烦的是,芯片团队和算法团队的节奏天然对不上。芯片那边按摩尔定律走,追求算力线性增长;算法这边按 Scaling Law 的信仰走,恨不得参数指数级膨胀。
这两条线各跑各的,导致了一个尴尬的现状:芯片的峰值性能 ≠ 实际系统效能。精心设计的模型跑在芯片上,经常无法充分发挥理论算力。为了适配硬件做的妥协,又反过来把模型变「笨」了。
这不是理想一家的痛。英伟达、苹果、谷歌全都在啃这块硬骨头。但理想的特殊之处在于,它是在 Orin 和 Thor 芯片上真刀真枪部署 VLA 大模型的过程中,被这个问题反复「毒打」过的玩家。
也许只有足够的痛,才能下定决心从根上解决。
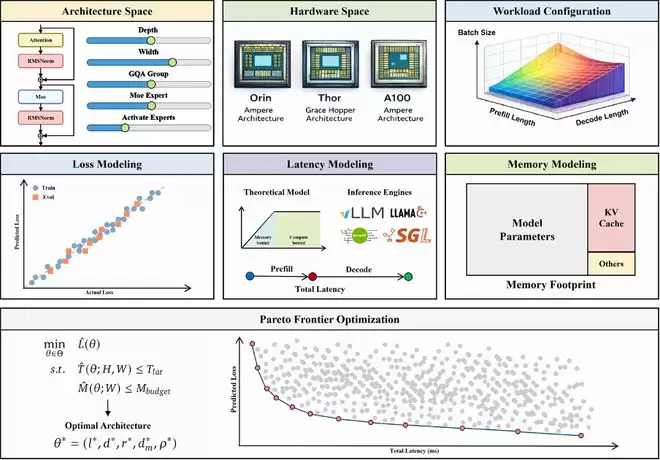
理想和国创决策智能技术研究所给出的解法,分三步走。
他们先做了一件有点「笨」但很扎实的事:训练了 170 个不同架构的模型,评估了近 2000 个候选配置。
这意味着什么?以前解决这个问题靠「试错」。算法团队要花几周甚至几个月训练模型、上车测试,不行再推倒重来。这是一个巨大的「黑箱」。现在,给定模型超参数,不用训练就能预测最终精度。这就从「黑箱试错」变成了「白盒预测」。
但光预测精度还不够。车载大模型在运行时会产生大量临时数据,像同时打开几十个浏览器标签页一样疯狂吞噬内存。于是他们祭出了第二个武器,将经典的 Roofline 性能模型进行了「车载化革新」。
传统 Roofline 模型只考虑计算和内存带宽的平衡,但大模型跑在车载 SoC 上,还有 KV 缓存、MoE 路由、注意力机制等一堆特殊负载在抢内存资源。研究团队首次系统性地把这些因素全部纳入建模,并在英伟达 Jetson Orin 和 Thor 平台上完成了实测验证。这相当于不仅看到了发动机的极限,还算清楚了油管、进气道对速度的制约。
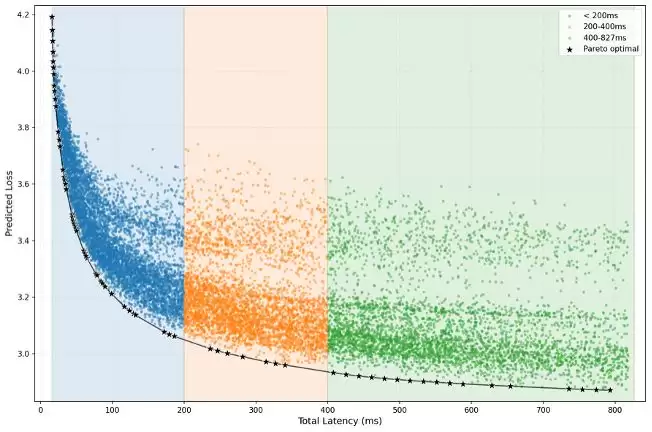
在两个模型的基础上,理想开发了 PLAS(帕累托最优 LLM 架构搜索)框架。你可以把它理解为一个「自动选配师」。给它输入芯片的硬件参数(算力、带宽、缓存层次)和工程约束(延迟、功耗、内存),它就能自动吐出最优的模型架构方案。
如果说,以前换一款芯片,算法团队要花几个月重新设计和调优模型。那现在,理论上一周就能搞定。
效果呢?也非常不错。优化后的模型在跟 Qwen2.5-0.5B 保持完全相同延迟的前提下,精度提升了 19.42%。同样的芯片,同样的速度,聪明了将近五分之一。
02
六个反直觉的发现
比这个数学定律更有冲击力的,是他们总结出了六个大的发现,都在挑战现有的芯片和模型设计常识。
其中最有冲击的一条是,决定车载 AI 实际表现的,往往不是芯片的峰值算力,而是它的内存带宽和缓存效率。
打个比方,算力像厨师的刀工,而内存带宽像传菜的速度;厨师刀工再快,菜送不上来,整个厨房照样瘫痪。这也意味着,很多发布会上被大书特书的「XXX TOPS」算力数字,可能真没大家以为的那么关键。
与此同时,另一个重磅发现同样值得芯片行业警醒:稀疏计算将成为车载 AI 的标配。理想发现,在车载这种「一次只处理一个请求」的典型场景下,一种叫 MoE(混合专家)的稀疏架构以 100% 的概率碾压了所有密集架构。
通俗地说,这就像一个拥有 16 位专科医生的医院,每次看诊只需要 1-2 位专家上场就行,而不是 16 个人一起围着你转,这既省资源又更高效。这意味着未来的车载芯片必须「天生」就懂得稀疏计算和动态调度,而不是傻乎乎地把所有计算单元一起点亮。

除此之外,三个工程层面的「坑」,同样值得关注:AI 推理分为「理解输入」和「逐字输出」两个阶段(Prefill 与 Decode),两者对硬件资源的需求截然不同。未来芯片不能是一条固定流水线,而要能根据阶段动态切换「工作模式」。
同时,传统 Transformer 模型里一个叫 FFN 的关键模块,长期沿用 4 倍扩展比,但理想的实验证明这个「祖传参数」在车上是低效的,芯片内部的计算单元配比需要重新设计。
再有,理论上把计算精度从高降到低(INT8 量化)应该快 2 倍,实际却只快了 1.3~1.6 倍。差距来自各种精度转换的「隐形税」,只有芯片从底层指令集就原生支持混合精度,才能把这笔「税」省回来。想靠压缩「白嫖」性能,没那么容易。
前五条发现,表面上各说各的,但把它们摞在一起看,指向的是同一个结论:没有万能芯片,只有最适合特定场景的芯片。这意味着,只有自己最懂自己的算法需要什么,才能造出最高效的芯片。
这也是理想自己做芯片的底层逻辑。
03
为马赫 100 铺路
说到这儿,这篇论文的战略意图就很清楚了。它是理想的战略拼图之一,自研芯片马赫 100。
根据披露的信息,马赫 100 是一颗 5 纳米制程的车规级芯片,预计 2026 年量产,首搭于全新一代理想 L9。其 Livis 版本搭载 2 颗马赫 100 芯片,芯片有效算力达 2560TOPS,是英伟达 Thor U 的 3 倍。
但「3 倍」这个数字本身不是重点。更重要的是,马赫 100 是一颗「算法原生芯片」。它的微架构、内存子系统、计算单元配比,不是芯片团队拍脑袋定的,而是由软硬协同设计定律「算」出来的。
打个比方,传统芯片像是先盖好房子再让住户适应户型;马赫 100 是先问清楚住户的所有需求,再定制每一面墙的位置。
落到辅助驾驶体验上,这意味着同样的功耗和散热条件下,马赫 100 能跑更大、更聪明的模型。你的车在复杂路口的犹豫会更少,对异形障碍物的识别会更快,智能辅助驾驶的体验会从「能用」更进一步迈向「好用」。
如果只把这篇论文看作理想秀一下「肌肉」,那就看浅了。
往深一层想,这篇论文真正在做的事,是重新定义车载 AI 芯片的评价体系。过去,行业评判芯片好不好,看 TOPS 算力、看制程、看参数规格,这些规则都是芯片厂商定的。但这次理想本质上在说,这些指标不够用了,真正决定系统性能的是算法和硬件之间的匹配效率。
再拉远一点看,过去十年,汽车行业的智能化经历了三个阶段:先是买芯片、跑别人的算法;然后是买芯片、跑自己的算法;现在,头部玩家开始走向第三步,自研算法+自研算力,软硬一体。
这条路,苹果在手机上走过,谷歌在云端走过,特斯拉在 FSD 芯片上走过。它们的共同经验指向同一个结论:软硬一体,才能带来极致的体验。
理想这篇论文的意义,不在于它提出了多漂亮的数学公式,而在于它用一套可验证的方法论证明了,算法和芯片必须长在一起,才能把智能的上限真正打开。这道门槛,才是下一轮淘汰赛真正的分水岭。
论文标题:《Hardware Co-Design Scaling Laws via Roofline Modelling for On-Device LLMs》(可点击文章最后阅读原文查看)
*头图来源:理想汽车
相关攻略

据外媒报道,近期发生了一件可能是最离谱的“捡漏”故事,不过这种运气可不是人人都有。 最近在Reddit上,一位用户的经历让整个硬件圈都直呼“离谱”。他在一家本地的清仓店里,只花了6 99美元,就成功拿下了一套64GB的DDR5笔记本内存(2×32GB)。 价格错误的“捡漏”故事之前也听过不少,比如半

日本DDR5内存价格“跳水”,但市场迷雾仍未散 最近,日本PC硬件市场传来一个值得玩味的消息:多款DDR5内存套装价格在4月中旬出现了显著松动,部分型号的降幅甚至超过了20%。这波降价,是市场回归理性的信号,还是又一次短暂的波动? 主流规格领跌,高频型号跟进 先看具体数据。根据市场监测,32GB(1

内存危机引发硬件涨价潮,Meta官宣Quest系列调价 一场由内存(RAM)供应紧张引发的连锁反应,正在消费电子市场掀起波澜。继索尼、微软之后,Meta也正式加入了涨价行列。公司今日宣布,自4月19日起,将对旗下Quest系列虚拟现实头显的售价进行全面上调。 具体来看,这次调价覆盖了多个产品线: M

采购价近乎翻倍:消息称苹果砸重金狂买三星12GB内存,只为首款折叠手机iPhone Fold 行业风向标终于有了新动向。来自韩媒The Bell的最新报道显示,苹果的首款折叠屏手机iPhone Fold,已经进入了量产备货的冲刺阶段。这不,为了保障核心零部件的供应,苹果已经开始向三星大量订购12GB

认识Android开发的“隐形杀手”:Handler内存泄漏 在Android开发中,内存泄漏问题比比皆是,但有一个“隐形杀手”尤为棘手,那就是Handler内存泄漏。它就像建筑结构里的微小裂缝,平时不易察觉,日积月累却足以导致整个系统稳定性坍塌。别担心,掌握其原理和应对策略,就能化险为夷。 Han
热门专题







热门推荐

5月12日,马来西亚吉隆坡成功举办了一场具有前瞻性的行业盛会——中国-马来西亚电动汽车、电池技术与新能源人才创新发展论坛。来自两国政府部门、领军企业、顶尖高校及国际组织的代表共聚一堂,深入交流了在未来产业协同、清洁能源技术创新及高端人才培养等核心领域的合作路径与机遇。 马来西亚第一副总理兼乡村及区域

具身智能要迈过的第一道硬门槛,从来都是量产。 过去几年,全球人形机器人行业反复印证了这一点:舞台演示可以很快,工程验证可以很快,视频传播也可以很快。但当一台机器人要从实验室走向产线,再走向客户现场,问题的复杂度会呈指数级上升。 特斯拉的Optimus就是一个典型的参照系。马斯克多次表达过对Optim

向朋友问路时,如果对方清楚路线,通常会立刻回答“直走然后左转”。但如果对方并不确定,往往会先停顿一下,犹豫地说“呃……好像是……往那边?”。这个开口前的短暂迟疑,往往比最终给出的答案更能说明问题——对方是否真的知道答案。 近期,美国天普大学计算机与信息科学系的一项研究,正是捕捉到了AI回答问题时类似

这项由浙江大学、华南理工大学、南京大学和北京大学联合开展的前沿研究,于2026年4月正式发布,其论文预印本编号为arXiv:2604 24575。 图像分割技术听起来或许有些专业,但它早已深度融入我们的日常生活。无论是智能手机拍摄的背景虚化人像、AI系统在CT影像中精准勾勒病灶轮廓,还是自动驾驶汽车

“大唐”预售热潮尚未平息,“大汉”已蓄势待发,比亚迪王朝系列正以前所未有的攻势,叩响高端市场的大门。 在北京车展引发轰动的比亚迪大唐,预售订单已迅速突破10万台大关,彰显了市场对比亚迪高端产品的强烈期待。而最新信息显示,汉家族即将迎来一位重磅新成员——“大汉”,这款定位D级旗舰的轿车,目标直指20-