OpenClaw进化拼图开源:AReaL v1.0实现智能体强化学习一键集成

机器之心编辑部
2026 开年已两个月,Agent 依然是全球最引人注目的 AI 赛道之一。OpenClaw(原 Clawbot)掀起的那波 Agent 热潮至今仍在发酵,甚至让「一人公司」概念第一次真正有了落地的可能性。
就在近日,OpenClaw 超越了 React、Linux,成为 GitHub 上 Star 量最多的非资源/教程类开源软件项目。
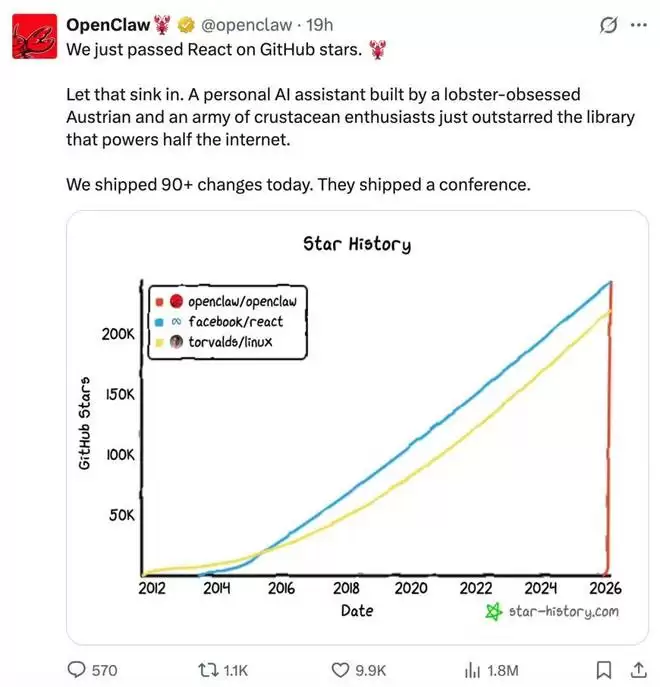
从 Browser Agent 到 Coding Agent,从个人到企业级工作流 Agent,最直观的感受是:Agent 能做的事越来越多了。
与此同时,包括 LangChain、Claude Code、OpenClaw 等在内,各类运行时框架不断拓宽智能体的能力边界,使它们胜任更复杂的任务。虽然这些框架赋予了 Agent 更加广阔的应用潜力,但如何让它们在真实环境中持续提升并形成自我进化能力,仍缺乏成熟的体系支撑。
尤其是被寄予厚望、用于支撑 Agent 在复杂、多轮、长程任务中进化的强化学习(RL)训练,在工程落地上面临多重阻力,限制了当前 Agent 的能力天花板。
AReaL v1.0 的发布为行业带来了积极的信号:一个开箱即用的 Agentic RL 训练底座已经成形。
由蚂蚁和清华大学联合打造的开源强化学习框架 AReaL,经过近一年的迭代打磨,迎来了里程碑式的稳定版本。作为一整套面向 Agent 的开源全异步强化学习训练框架,此次最受瞩目的进展在于让「Agent 一键接入 RL 训练」成为现实,重新定义了智能体强化学习的范式。
GitHub 仓库:https://github.com/inclusionAI/AReaL论文:https://arxiv.org/abs/2505.24298
在 Agentic RL 算法系统协同创新的加持下,AReaL v1.0 可以兼容任意 Agent 框架,仅需修改一个接口地址即可无缝接入 RL 训练,包括最近火热的 OpenClaw,极大降低了强化学习的训练门槛。不仅如此,AReaL v1.0 还引入了系统化的 AI 辅助开发体系,并基于深度定制开发的 PyTorch 原生训练引擎 Archon 实现了千亿 MoE 模型的端到端训练,引领了下一代 AI Infra 工程范式的革新。
零代码接入 OpenClaw 训练
传统的 Agent 强化学习训练,往往需要开发者深入理解底层训练框架、修改 Agent 运行时代码、甚至重构整个数据流水线。而 AReaL v1.0 彻底打破了这一壁垒 ——你的 Agent 框架不需要改动一行代码
视频链接:https://mp.weixin.qq.com/s/w3JxlHsI1B4n3OqthaSQ6Q
让我们用一个实际例子来看看这有多简单。
完整案例:https://github.com/inclusionAI/AReaL/tree/main/examples/openclaw
第一步:启动 RL 训练服务
uv run python3 examples/openclaw/train.py --config examples/openclaw/config.yaml
启动后,你会看到类似这样的输出:
(AReaL) Proxy gateway available at https://x.x.x.x:xx
记下这个网关地址,它就是连接你的 Agent 与 RL 训练的桥梁。
第二步:配置你的 Agent
我们以 ZeroClaw 为例,它是 OpenClaw 的一个变体。只需要修改一个配置文件,将 API 地址指向 AReaL 网关:
# ~/.zeroclaw/config.tomldefault_provider = "localhost"api_key = "sk-sess-xxxxxxxxxxxx" # 从AReaL获取
[model_providers.localhost]base_url = "https://
" # AReaL代理网关地址
就这样,配置完成。你的 ZeroClaw Agent 现在每一次 LLM 调用都会自动被记录,用于强化学习训练。
第三步:正常使用你的 Agent
启动智能体,像往常一样交互:
zeroclaw channel start # 启动Discord/Slack/CLI等任意交互渠道
你可以让 Agent 写代码、查资料、执行任务 ——一切照常。在后台,AReaL 悄悄记录着每一次对话轮次中用于强化学习训练的数据。
第四步:打分反馈,让 Agent 进化
当一个任务完成后,给 Agent 的表现打个分:
python set_reward.py https://
--api-key sk-sess-xxx --reward 1.0
就这么简单。AReaL 会自动将这次交互轨迹与奖励信号打包,送入训练流水线。
当收集到足够的交互轨迹后(由配置中的 batch_size 控制),系统会自动触发一次训练迭代,更新模型权重。更神奇的是:更新后的权重会无缝应用到后续的推理请求中。
你的 Agent 仍在训练过程中运行,不需要重启,不需要重新加载模型 —— 它会在你不知不觉间变得更聪明
架构破局:用「异步训练」与「代理网关」打通 Agent 自我进化
AReaL 是怎么做到让 OpenClaw 自我进化的?这里涉及到两个核心的架构设计:「全异步训练」和「代理网关」。
AReaL 的核心架构创新之一在于强化学习中的训练、推理完全解耦。推理引擎流式生成轨迹,训练引擎持续消费样本,两者在独立 GPU 上同时运行。
通过精心设计的 PPO 算法修正和陈旧度控制机制,AReaL 在保证训练稳定性的同时,实现了 2 倍以上的吞吐提升
这种设计在智能体训练场景中有更大的优势 —— 训练引擎异步更新参数,不会阻塞智能体的推理,让你的 OpenClaw 一边学习一边全力工作
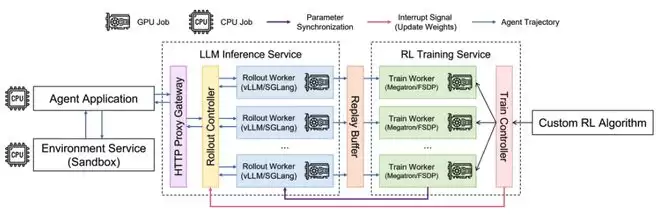
AReaL 的代理网关和全异步强化学习架构
为了适配任何智能体框架,AReaL 选择将「协议」作为统一标准,设计了一个代理网关(Proxy Gateway)。这个网关提供了 OpenAI/Anthropic API 协议的推理服务,会将所有输入的请求重定向到本地的推理引擎上(如 SGLang、vLLM)进行推理计算,用起来就像一个普通的推理服务。
但是,这个代理网关不止有路由的功能 —— 它会在进行推理的同时,捕获每一次 LLM 交互中输入输出的 Token 级信息。在这条轨迹结束后,AReaL 会将后一步的奖励值进行反向传播,为每一轮的输入输出赋予奖励值;最终,将它们导出为独立的训练样本。这样,早期的决策也能获得合理的奖励分配,让模型学会「为长远目标做出正确的早期选择」。
传统方案中,推理时的文本需要在训练时重新 tokenize,可能因 tokenizer 配置差异导致 token 序列不一致。AReaL 的独立导出方案从根本上避免了这个问题:推理时产生的 token IDs 直接被缓存,训练时原样使用。发送给训练引擎进行梯度计算的 tokens 就是推理引擎生成的 tokens,100% 一致。
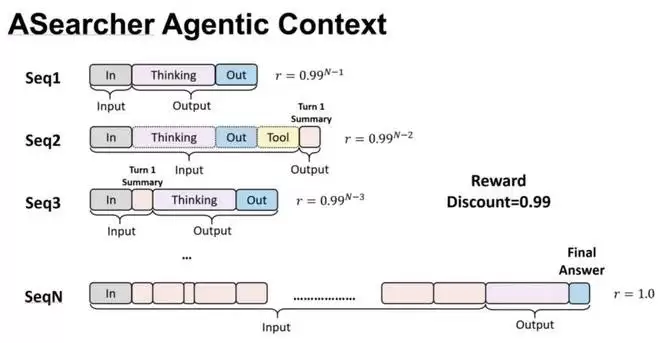
AReaL 中具体的多轮交互应用案例
基于以上的架构设计,AReaL 能够支持任意 Agent 框架的训练 —— 无论是 OpenClaw 还是你自己搭建的 Agent,只需要将 API 地址指向 AReaL 的代理网关,就能自动接入强化学习训练。
开发者不用改动原有 Agent 代码或业务逻辑,即可开启 RL 训练流程。这意味着,原本碎片化的 Agent 接口被收敛成了一层标准化的协议级 RL 入口,让「任意 Agent 可训」第一次在工程上真正可行
然而,同一个 prompt 可能产生多条不同轨迹(如多次采样),并且每条轨迹也会被 AReaL 打散成为多条独立的输入输出。一个批次的数据之间往往存在大量共享前缀。传统训练方式对每条轨迹独立计算,造成大量冗余计算。
AReaL 为了解决这个问题,引入了基于 Trie(前缀树)的序列打包方案:
构建 Trie 结构:将共享前缀的序列压缩到同一个树结构中树状注意力计算:AReaL-DTA 方法实现了完整的树状注意力 forward-backward 方案,让共享前缀仅计算一次
树状注意力带来了显著的性能提升:单 Worker 训练吞吐最高提升 8.31x,集群整体吞吐最高提升 6.20x,相比于基线方案减少超过 50% 的 GPU 显存占用
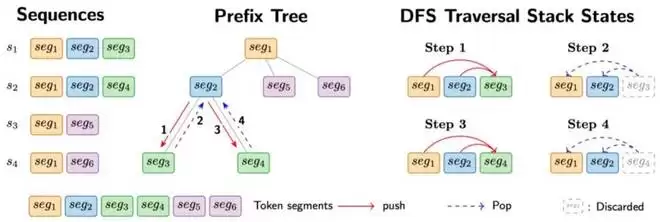
针对 Agentic RL 训练的树状注意力实现图示,详细参考论文:https://arxiv.org/pdf/2602.00482
用 AI 实现引擎重构:AI Infra 的工程范式革新
除了降低 Agent RL 训练的门槛,AReaL v1.0 的发布还带来了训练引擎的重磅更新
在大规模 RL 训练领域,Megatron-LM 是业界标杆。然而,它的依赖安装需要 Docker 环境和繁琐的 C++ 编译,代码层层嵌套,难以调试和扩展。团队一直在思考:能否用 PyTorch 原生 API 实现同等能力的分布式训练引擎
答案是 AReaL 团队基于 torchtitan 深度定制的训练引擎 Archon ——一个支持完整 5D 并行(DP、TP、PP、CP、EP)的 PyTorch 原生训练引擎
数据并行 (DP):基于 FSDP2 fully_shard,相比 Megatron 默认的数据并行进一步拆分了模型参数流水线并行 (PP):基于 torch.distributed.pipelining,支持ZeroBublePipeline、 1F1B 、 Interleaved1F1B 等调度方式张量并行 (TP):基于 DTensor,使用 ColwiseParallel / RowwiseParallel 切分权重上下文并行 (CP):基于 Ulysses Sequence Parallelism,通过 all-to-all 分布式处理长序列专家并行 (EP):基于 all-to-all + grouped_mm,支持 EP + ETP 2D 分片
令人惊讶的是,这样一个复杂的分布式系统,从零开始实现到验证正确性,仅用了 1 人・月的工作量——32 天内通过累计 72 万行代码修改完整实现了 Archon 引擎,并验证了它能训练千亿参数 MoE 模型。
创造这一效率奇迹的秘诀在于 AreaL 集成的一整套 AI 辅助开发体系,实现了复杂工程开发的高度自动化。
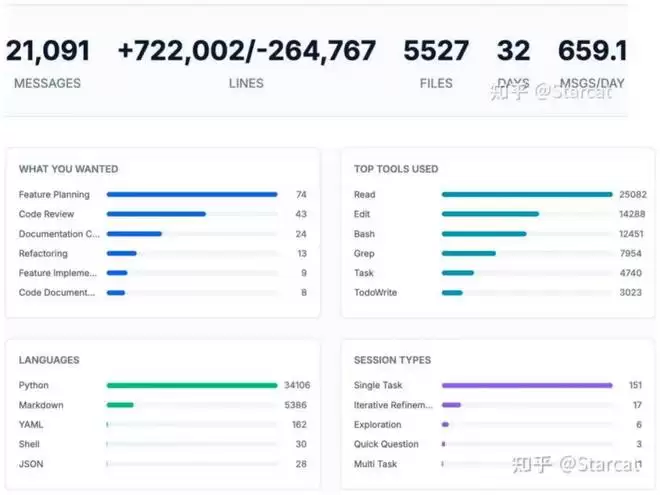
基于 AI 编程的 archon 引擎代码修改统计,来源 https://zhuanlan.zhihu.com/p/2003269671630165191
这些驾驭 AI coding 的「武功秘籍」完全开源,让每位开发者都能借助「专业团队」,在 AReaL 中加速自己的 Agent RL 应用开发:
一是为 AReaL 各核心模块配置领域专家 Agents,让它们具备模块级架构认知,并在代码修改时提供上下文相关的精准指导。
二是引入以命令驱动的引导式工作流,通过一系列预设的一句话指令将常见开发任务流程化、标准化,让开发范式从「手写实现」转向「声明需求」,由 AI 自动完成软件工程中最常见、最耗时的运维任务。
三是在真实开发场景中,AReaL 提供的特定 Agent 全程自动化完成任务规划、代码生成、自动校验到 PR 创建。
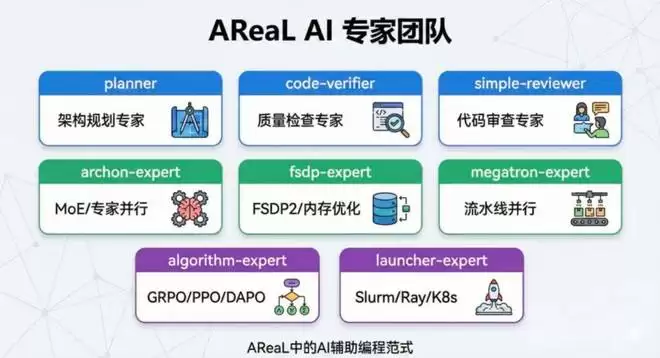
AReaL AI Coding Sub-Agents(图片由 AI 辅助生成)
这套 AI 辅助开发体系在加速 Archon 引擎落地之外,也释放出一个清晰的信号:AI 辅助编程不仅仅是效率工具,同样具备了深度参与复杂系统开发的真实生产力。这一「用 AI 造训 AI 工具」的工程实践,重新定义了效率边界。
相应地,软件工程的角色分工出现深刻重构,人类开发者可以不用将大量精力耗费在具体实现和重复性细节上,更多地转向「明确需求、设计系统」等决策工作。AI 更多地承担流程固定、规则明确的工程落地任务。
在这样的范式变革下,原来重工程、重经验的 Agentic RL 有望随着开发门槛的系统性降低,走向更广泛的开发者群体。
结语
如果说过去一两年,行业主要精力放在了教 Agent「怎么做事」上,即通过更好的工具调用、更复杂的工作流编排和更精细的 prompt 工程,让 Agent 一步步跑通任务。那么下一阶段,「如何让 Agent 自我进化」成为重中之重。
正因为如此,以 RL 为代表的系统化训练从过去的加分项,逐渐成为决定 Agent 能力上限的关键变量。
在这个重要的转折点,AReaL v1.0 为行业贡献了一个兼具易用性、可靠性和强扩展性的开源 Agentic RL 范本:应用层保持开放和兼容,轻松接入不同 Agent 框架;引擎层深度优化,极致压榨训练效率和资源利用率。
未来,AReaL 团队将继续在系统组件可用性、Archon 引擎生产效率、AI 辅助开发能力和 VLM/Omni 模型 Agent 训练等四个方向发力,最终打造成为 Agentic AI 时代的高性能 RL 运行时底座。
当训练框架变得足够简单,当 Agent 的接入方式足够统一,当 AI 能够深度辅助底层系统的开发工作,Agentic RL 的大规模落地必将跨越少数顶尖团队的门槛,成为更加普及的大众开发者利器。这正是「技术民主化」的核心要旨。
随着这类高性能底座的日益成熟,Agent 有望加速跨越跑通 Demo 的初级阶段,真正开启持续、自主、规模化进化的新阶段。
相关攻略

Matrix 是一种开放且去中心化的即时通讯协议,允许用户自主部署私有服务器并接入全球 Matrix 联邦网络。OpenClaw 网关通过集成 Matrix 的 Client-Server API,实现与这一分布式通信生态的无缝对接。 前置准备 在配置 OpenClaw 连接 Matrix 之前,请

周二晚间,AI领域迎来了一则重磅消息。在权威AI评测平台Artificial Analysis的榜单上,一个名为「HappyHorse-1 0」的神秘模型异军突起,一举登顶视频生成能力排行榜,引发了业界的广泛关注与热议。 这一成绩极具含金量。无论是文本生成视频,还是图像生成视频,HappyHorse

当AI开始学会“脑补”物理世界的运行规律,并尝试模拟一个动态变化的真实环境时,我们距离那个传说中的通用人工智能(AGI)究竟还有多远? 进入2026年以来,“世界模型”毫无悬念地成为了科技圈最炙手可热的核心议题。它标志着一个关键的范式转变:人工智能正从被动地“感知当下”,迈向主动地对时空与动态变化进

上周三关于“世界模型”的线上沙龙反响空前热烈,这充分表明,从被动感知迈向主动推演,这条被视为实现通用人工智能(AGI)的核心技术路径,正深度吸引着整个AI行业的关注。鉴于持续高涨的讨论热度,我们决定加开一场深度分享会。 那么,这条充满潜力却又极具挑战性的前沿赛道,目前进展到了何种阶段?顶尖的研究者们

数字逻辑与物质建构的深度对话 ——评许哲诚“境域·生成”计算性设计展演 □ 丁雅力(江苏省美术馆策展人) 当代设计与造物的核心范式,正经历着由计算性设计带来的深刻变革。2026年3月20日,南京艺术学院教师许哲诚于南京莫玄空间呈现的“境域·生成”个人专场展演,正是这一前沿趋势的集中体现。本次展览超越
热门专题







热门推荐

《极限竞速:地平线6》于5月19日发布,全面支持DLSS4 5超分辨率与多帧生成技术,显著提升画面与流畅度。同期,《月之深渊》确认集成DLSS超分辨率,《红色沙漠》则升级支持专为RTX50系列优化的DLSS4 5动态多帧生成6倍模式。这些技术为玩家带来了更极致的视觉体验与性能提升。

《地牢猎手6》将于6月17日全平台公测,作为系列正统续作,以4K画质和动态光影重现暗黑风格。游戏提供四大职业,技能自由搭配,支持单人探索与多人联机。预约达20万可解锁全服奖励,含SSR坐骑、英雄等资源,iOS、安卓及PC模拟器数据互通且永久保留。

网格交易中,止损是风险管理的关键环节。有效的止损参考应结合市场波动率、网格层级与资金占比、技术支撑阻力位以及交易策略的宏观周期。通过量化指标与动态调整,可以在捕捉市场波动的同时,将潜在亏损控制在可接受范围内,实现策略的长期稳健运行。

下载《猜拳大师》安卓版主要有两种可靠途径。一是通过游戏门户或专区搜索游戏,在详情页选择高速或普通下载。二是前往手机官方应用商店直接搜索并下载,安全便捷。两种方法均能获取正版安装包,助你快速体验游戏。

止损是交易中控制风险的关键操作。在币安App中设置止损时,需重点关注触发价格、订单类型与市价滑点的关系,以及仓位大小与止损比例的匹配。理解这些核心要素,并结合市场波动性进行动态调整,才能构建有效的风险管理策略,避免情绪化决策带来的损失。