微软研究发现:AI越聊越笨,复杂对话可靠性骤降
你是否发现,当我们与AI聊天机器人进行长对话时,它们似乎会变得越来越“笨”?IT之家2月20日消息,如今这种感觉有了科学依据。
Windows Central今日报道称,微软研究院与赛富时联合发布的一项研究证实,即使是目前最先进的大语言模型,在多轮对话中的可靠性也会急剧下降。

研究人员对包括GPT-4.1、Gemini 2.5 Pro、Claude 3.7 Sonnet、o3、DeepSeek R1 和 Llama 4 在内的15款顶尖模型进行了超过20万次模拟对话分析,揭示出一种被称为“迷失会话”的系统性缺陷。
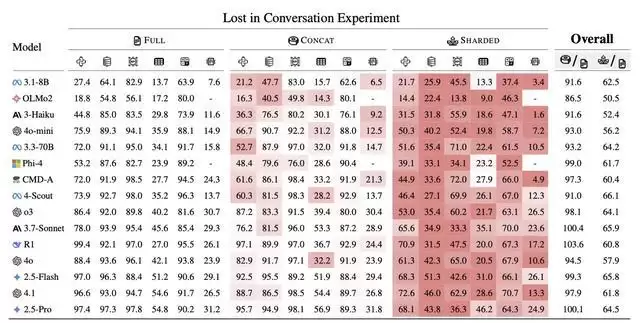
数据显示,这些模型在单次提示任务中的成功率可达90%,但当同样的任务被拆解成多轮自然对话后,成功率骤降至约65%。
研究指出,模型的“智能”本身并未显著下降——其核心能力仅降低约15%——但“不可靠性”却飙升了112%。也就是说,AI大模型仍然具备解决问题的能力,但在多轮对话中变得高度不稳定,难以持续跟踪上下文。
报告指出,当前大多数模型主要在“单轮”基准测试下进行评估,即一次性接收全部指令的理想实验环境。但现实世界中的人类交流通常是渐进式的,信息在多轮互动中逐步补充。研究发现,一旦任务被“拆分”到多个回合中,即使是最先进的模型,也容易出现系统性失误。
研究人员进一步分析了造成性能下降的行为机制。
首先是“过早生成”:模型往往在用户尚未完整说明需求前就尝试给出最终答案。一旦在早期回合中形成错误假设,模型后续便会在该错误的基础上继续推理,而不是随着新信息的加入进行修正,从而导致错误逐步放大。
其次是“答案膨胀”。在多轮对话中,模型的回复长度比单轮对话增加了20%至300%。更长的回答往往包含更多假设与“幻觉”,这些内容随后被纳入对话的持续上下文,从而进一步影响后续推理的准确性。
令人意外的是,即便是配备了额外“思考词元”的新一代推理模型,如OpenAI o3 和 DeepSeek R1,也未能显著改善在多轮对话中的表现。研究还发现,将模型温度参数设置为0——这一常用于确保一致性的技巧——对此类对话衰减几乎没有防护作用。
这一发现对当前AI行业的评估方式提出了质疑。研究人员指出,现有的基准测试主要基于理想的单轮场景,忽略了模型在真实世界中的行为。对于依赖AI构建复杂对话流程或智能体的开发者而言,这一结论意味着严峻挑战。
目前最有效的应对方式反而是减少多轮往返交流,将所有必要数据、约束条件和指令一次性在单个完整提示中提供,以提高输出一致性。
相关攻略

亚马逊按下“重启键”:下一代Alexa能否重夺AI语音王座? 科技圈又有新动静了。就在今天,亚马逊发出了人工智能主题活动的邀请函,时间定在2月26日。多方信源,包括路透社的报道均指向一个焦点:亚马逊计划在此次活动上,正式推出其下一代、基于生成式人工智能的Alexa服务。 话说回来,自2014年面世以

派欧算力云产品介绍 人工智能的浪潮正席卷各行各业,企业和开发者们面临一个共同的挑战:如何快速、经济且高效地获取AI算力,将创意迅速转化为市场产品?面对这一需求,一站式AI云服务平台——派欧算力云,提供了颇具吸引力的答案。本文将带你深入剖析派欧算力云的核心功能、独特优势以及应用路径,看它如何为企业的A

京东开源图像模型JoyAI-Image-Edit,从平面修图升级为三维空间重塑 4月7日,京东探索研究院正式宣布,开源自研的JoyAI-Image-Edit图像模型。这不仅是又一个开源工具,更标志着图像生成编辑技术的一次关键转向:从二维平面迈入了三维空间。 简单来说,这个模型被设计为业内首个将“空间

Anthropic启动Project Glasswing计划,集结科技巨头共筑软件安全防线 近日,人工智能公司Anthropic启动了一项名为“Project Glasswing”的新计划。这项计划的核心目标,是借助其尚未公开发布的Claude Mythos Preview模型,来加强全球关键软件基

就在 OpenAI 都停了 Sora,所有人以为 Seedance 2 0 要一统天下的时候,没想到不知哪里冒出来一匹马。 周二晚间,在知名 AI 评测分析平台 Artificial Analysis 上,一个代号为「HappyHorse-1 0」的神秘视频生成模型空降榜首,引发了 AI 社区热议。
热门专题







热门推荐

钉钉文档官网 在探讨企业级协同办公解决方案时,钉钉文档无疑是备受瞩目的核心工具之一。作为阿里巴巴钉钉官方推出的旗舰级应用套件,它深度融合了在线文档编辑、智能表格、思维导图等多种高效创作工具。其核心优势在于与钉钉平台生态的无缝衔接,能够直接同步企业内部组织架构与通讯录,实现团队成员间的即时协作与信息流

在数字化转型浪潮中,高效、易用的数据分析工具已成为企业提升决策效率的关键。商汤科技推出的“办公小浣熊”智能助手,正是基于自研大语言模型打造的一款创新产品,旨在彻底降低数据分析的技术门槛。用户无需掌握编程知识或复杂操作,即可通过自然对话完成从数据查询、处理到可视化洞察的全流程,让数据价值触手可及。 办

在人工智能技术快速发展的今天,MiniMax作为一家专注于全栈自研的AI公司,正以其独特的技术路径和前瞻性的布局,在业界脱颖而出。公司致力于构建覆盖文本、图像、语音和视频的新一代多模态智能模型矩阵,这不仅体现了对核心底层技术自主权的深度掌控,也展现了对未来人机交互与内容生成形态的前瞻思考。 那么,M

ApolloCreditFund(ACRED)作为连接传统信贷与DeFi的桥梁,其价格受市场情绪、协议基本面及宏观环境影响。其价值逻辑根植于现实世界资产(RWA)的收益捕获与链上流动性释放。短期价格波动难以预测,但长期发展取决于信贷资产质量、协议安全性和市场采用度。投资者需关注其底层资产表现、代币经济模型及整个RWA赛道的发展趋势。

在数字化转型浪潮中,一套能够深度适配业务、彰显品牌特色的智能客服系统,已成为企业提升服务效率与用户体验的关键工具。然而,市场上许多解决方案往往模式固化,难以满足个性化需求。如何让AI客服不仅具备基础的自动化应答能力,更能承载独特的品牌文化与服务哲学?其核心在于系统是否支持深度的自定义与持续的AI训练