清华首创可执行数据闭环!Multi-Agent开源超越GPT-5新突破

免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
新智元报道
编辑:LRST
【新智元导读】清华团队提出EigenData系统,通过可执行数据闭环优化多轮Agent训练,在真实场景中使开源模型表现达到与闭源系统相当水平。关键在于训练数据的稳定性和可验证性,确保模型在交互中能持续学习有效策略,而非依赖不可靠的奖励信号。
过去一年,Agent的「能力竞赛」几乎走到了一个拐点:单轮工具调用、短链路推理的提升还在继续,但一旦进入真实多轮交互,系统开始暴露出完全不同的脆弱性。
工程团队越来越频繁地遇到同一问题:模型在离线评估中表现正常,但一旦进入真实多轮交互,训练信号就开始频繁失真。
一次异常的用户行为、一次工具轨迹跑偏,都会把整段rollout的reward直接归零,最终把强化学习推向错误方向。
越来越多的信号表明Agent训练中:
多轮Tool-Using Agent的上限,越来越取决于训练信号是否可归因、可验证,而不只是模型规模。
在τ²-bench等真实Tool-Using Agent基准中,研究者观察到,多轮Agent在进入强化学习阶段后,成功率并不总是随训练推进而单调提升,反而常伴随明显波动,这些波动并非来自模型能力不足,而更多源于长链路交互中用户行为不稳定与奖励误归因的持续放大。
一项最新研究从系统层面重构了多轮Agent的训练流程:围绕可执行数据生成、用户模型稳定化与verifier-based奖励提出了一套新的训练范式,并在τ²-bench的三个真实工具域上完成验证。

论文链接:https://arxiv.org/abs/2601.22607
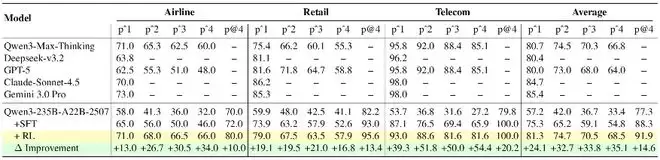
在不引入更大模型规模的前提下,开源Qwen3系列模型在关键场景中实现了显著提升:
Airline中73.0%pass¹,与Gemini 3.0 Pro基本持平,明显高于GPT-5(62.5%)
Telecom中98.3%pass¹,达到当前公开的最佳结果,超过Gemini 3.0 Pro、Claude Sonnet与GPT-5
这些结果表明,借助系统级训练范式的优化,开源模型在真实工具交互任务上的可靠性已经被推至与主流闭源系统同一梯队。
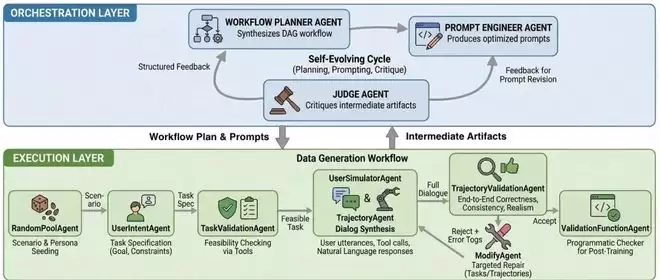
多轮Agent难训
并不是「不会用工具」
如果只停留在单轮工具调用层面,Agent的问题看起来并不复杂。
给定输入、选择工具、执行一次、返回结果,reward也可以直接对应到这一步是否成功。
但一旦把视角拉到真实的多轮交互中,情况就完全变了。
对话被拉长为长链路的trajectory,工具调用不再是孤立事件,而是与用户反馈交错出现;用户状态也不再是静态前提,而是在交互过程中不断暴露、甚至发生漂移。
此时,Agent 面对的已经不是「会不会用工具」,而是能否在一个持续变化的系统中保持决策一致性。
而在现实训练环境中,模型往往表现出明显的不稳定性,模型容易学偏,甚至出现效果随训练波动、难以收敛的问题。
研究结果指明主要原因集中在两点:
1. 缺乏真正「可用」的训练数据
真正可用于多轮Agent训练的数据,必须同时覆盖:
多轮对话+ 多步工具执行 + 用户侧信息逐步透露/改变偏好。
问题在于,这样的数据在现实中几乎不可能通过人工标注规模化获得。而自动合成的数据,看似缓解了数据稀缺的问题,却引入了新的隐患。
在大量样本中,工具调用轨迹在文本层面「看起来合理」,但只要真正执行一遍,就会触发不可完成状态,trajectory 在中途失败。
最终,Agent 学到的并不是稳定、可复现的工具使用能力,而是一种停留在表层的策略模式(surface-level policy),即它看起来像在做事,却无法在真实系统中跑通。
2. 用户模拟的不稳定性会直接污染RL信号
在interactive RL设置中,用户模拟器是驱动对话不可或缺的一环。但我们发现,开源模型充当用户时经常无法稳定遵循指令,甚至会随意调用工具,导致 rollout 提前失败。
在多轮Tool-Using Agent的训练中,reward不再只取决于某一次工具调用是否成功,而是由整段交互trajectory的最终状态统一决定。这意味着,只要链路中任何一个环节出现偏差:一次用户行为异常、一次工具误调用、一次状态提前终止,整段rollout的reward都可能被直接归零。
从结果上看,Agent「失败」了;但从系统内部看,失败并不一定来自agent policy本身,也可能来自于用户模型本身的不稳定性。

在真实训练过程中,user model往往并不能始终稳定地遵循任务设定。它可能偏离指令、误调用工具,甚至在关键步骤提前结束对话。
这些行为本身并非agent决策的结果,却会直接决定最终reward。
于是,情况就变成Agent在局部决策上是正确的,但由于用户行为偏移,最终环境状态失败,reward被统一判为0
从强化学习的视角看,这构成了严重的credit assignment failure。reward无法区分失败究竟源于 agent policy,还是来自user policy的异常行为。在这种条件下,强化学习并不会「修正」问题,而是会不断将噪声反向传播到agent上,最终推动策略朝着错误方向收敛。
从这个角度看,多轮Agent的训练瓶颈,并不完全是算法问题,而是一个系统结构问题。
基于这一判断,论文并没有继续在强化学习算法层面叠加复杂性,而是选择从更底层的训练流程入手,重新拆解agent与user的角色分工。
EigenData不「生成更多数据」
让数据自己进化
在多轮Tool-Using Agent的训练中,数据问题往往被简化为一个数量问题:数据够不够多、覆盖够不够广。
但在真实long-horizon交互场景下,这个假设并不成立。
大量 synthetic data 在文本层面看起来合理,逻辑自洽、对话完整,但一旦真正执行工具调用,就会暴露出根本性问题:工具参数不合法、状态无法到达、任务在中途进入不可完成区域。
这意味着,模型并不是在「失败中学习」,而是在用不可执行的轨迹训练自己。因此原文中EigenData的设计重点关注了如何构建一个可闭环演化的数据生成过程,即:
生成数据 → 发现失败 → 自动修正prompt与workflow → 再生成
EigenData并不是传统意义上的synthetic data pipeline,而是一个能够根据失败反馈持续迭代的多智能体系统,结合自检与自修复机制,逐步构建出高质量的数据集合。
在EigenData的工作流程中,每条训练样本都被要求必须满足一个硬性条件:其对应的工具调用轨迹可以被完整执行,并由verifier在代码层面验证最终环境状态。
如果执行失败,失败信息会被回流,用于自动修正 prompt、workflow 以及生成策略本身。
这使得数据分布并不是一次性生成的结果,而是会随着失败反馈持续向「可执行区域」收敛。通过自动生成多轮对话并执行真实工具调用,每一条数据实例都会配套一个「可执行验证器」,使得 Agent 行为是否成功可以通过代码直接判断,因此能够保证数据质量「越跑越好」。
从系统角度看,通过这一动作,EigenData不断缩小了模型可以学习到的行为空间,使其对齐真实系统的可行解集。这一步保证了模型在RL介入之前,每个reward都可以真正对应到一个已经被系统验证后的结果,使训练信号本身是可执行、可验证、可复现的。
先训用户模型,再训Agent
即便训练数据本身是可执行的,多轮 Agent 的训练仍然可能失败。
原因在于,在interactive agent场景中,用户模型本身就是系统的一部分。
如果user policy存在漂移或不稳定性,即便 agent 的局部决策是正确的,整段 trajectory 仍可能因为用户行为异常而失败,最终 reward 被统一归零。
基于这一认识,研究者们将训练流程拆分为两步:
首先,使用EigenData生成的可执行对话数据,对user model进行SFT微调,使其行为稳定、可控,并与任务设定对齐;
在用户侧不再成为主要噪声源之后,才引入强化学习优化agent policy。
这一拆分并不是额外的工程复杂度,而是一个系统级前置条件。它从根本上减少了 reward 的混杂来源,使强化学习不再频繁惩罚「正确但被用户行为破坏的决策」,训练曲线也因此变得稳定、可预测。
用「可执行结果」替代主观奖励
在强化学习阶段,该方法不再依赖模糊的reward model,而是用任务自带的验证函数(verifier)直接检查最终环境状态,实现「对 / 错」的可执行、可审计奖励信号。
在此基础上,引入GRPO的group-relative advantage:针对同一任务采样多条trajectory,进行组内相对优势学习,以降低long-horizon交互导致的高方差与不稳定性。
同时使用dynamic filtering剔除「全对/全错」的低信息样本,将训练预算集中于具有区分度的任务子集。
在这些设计的共同作用下,RL信号更干净、更稳定,训练过程也更不易出现策略漂移。
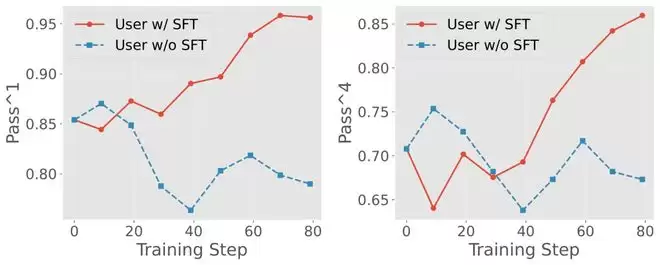
实验结果
开源模型训练至接近封闭模型水准
为了验证这一套系统级训练范式在真实交互场景中的有效性,研究者在τ²-bench的三个真实工具任务(Airline / Retail / Telecom)上进行了系统评估。评估采用pass¹指标,即要求Agent在一次完整多轮交互中成功完成任务,这一指标能够更直接反映 Agent 在 long-horizon 场景下的稳定性与可靠性。
结果显示,性能提升并非偶然,而是在多个场景中稳定出现。
在规则最复杂的Telecom场景中,Qwen3-235B-A22B-2507经SFT + RL训练后,pass¹提升至98.3%,进入当前公开结果的最强梯队;
在Airline场景中,同一模型达到73.0% pass¹,整体表现已与主流闭源系统对齐。
更关键的是,在三域混合训练设置下,一个模型同时学习多个工具环境,最终仍能保持81.3% 的平均 pass¹,表明该方法学到的并非单一场景下的「投机策略」,而是更具通用性的 tool-using 能力。
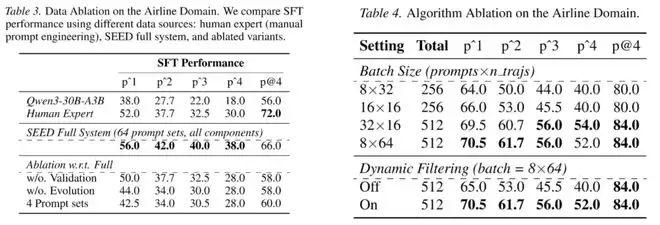
进一步的消融实验揭示了这些提升的来源。
一旦移除validation / verifier或数据自进化机制,SFT 阶段的性能便出现明显下降,说明数据的可执行性与多样性是能力形成的基础;而如果在未对用户模型进行稳定化预训练的情况下直接引入强化学习,整体性能反而会退化。这一结果表明,只有在用户行为被有效控制的前提下,强化学习才能持续带来正向增益。
可执行训练信号并不是一个「锦上添花」的技巧,而是一条明确的系统分界线。
当 Tool-Using Agent 进入真实多轮交互,问题不再只是「强化学习还能不能收敛」,而是训练信号本身是否具备工程意义:它是否可执行、可归因、可验证,是否真正对应到一个可复现的系统结果。这正是EigenData介入的位置。
通过将数据生成、工具执行与verifier校验统一进一个闭环系统,EigenData不只是为RL提供了「更干净的reward」,而是重新定义了什么样的训练信号才值得被强化学习放大。在这一前提下,GRPO、dynamic filtering等优化策略才第一次拥有清晰、稳定的作用对象。
论文给出的判断标准其实非常直接:如果一个多轮Agent的训练流程无法明确回答「reward 到底在奖励谁、失败究竟由谁导致、同一任务下哪条轨迹更好」,那它在工程上仍停留在「看起来能跑」的 workflow,而不是「可以持续优化」的system。
从这个角度看,训练中出现的performance oscillation、reward 被异常用户行为清零、RL 反而带来退化,并不是实现细节上的瑕疵,而是训练信号尚未被系统性构造的必然结果。
这项工作的核心贡献,并不在于提出一种新的RL技巧,而在于通过EigenData将多轮Agent的post-training推向一个新的工程范式:
当训练信号先被构造成可执行、可归因、可验证的系统对象时,强化学习才真正成为一种可控的系统优化;在此之前,再多的 rollout 和更大的模型,也只是在噪声之上叠加计算。
参考资料:
https://arxiv.org/abs/2601.22607
相关攻略

角色与核心任务 你是一位顶级的文章润色专家,擅长将AI生成的文本转化为具有个人风格的专业文章。现在,请对用户提供的文章进行“人性化重写”。 你的核心目标是: 在不改动原文任何事实信息、核心观点、逻辑结构、章节标题和所有图片的前提下,彻底改变原文的AI表达腔调,使其读起来像是一位资深人类专家的作品。

从“动口”到“动手”:OpenClaw如何将AI推入“执行时代”? 文|洞见新研社 3月的最后一周,OpenClaw的GitHub社区上演了一出反转剧。往日里忙着报错的开发者们这次成了观众,主角换成了来自蚂蚁、天融信、360等机构的安全研究员,他们密集披露了数十个涉及远程接管、信息泄露的高风险漏洞。

程序员惊喜,每月100美元!OpenAI上线全新Pro方案:Codex限时10倍额度 北京时间4月10日凌晨,OpenAI终于落下了重度用户期盼已久的那只靴子:正式推出每月100美元的全新订阅方案。 至此,OpenAI的商业化版图已经清晰地划分为四个核心层级: ·免费版(接入广告) ·每月8美元的G

2026 04 14 一个核心趋势是:未来的商业竞争,本质上是用户注意力资源的争夺战。谁能更精准、高效地连接信息与用户需求,谁就能在市场中赢得关键优势。 本文配图深刻揭示了这种高效连接的底层逻辑与完整工作流。它系统展示了从数据采集到价值交付的闭环链路,每个环节都紧密耦合。实践证明,其中任一节点的效率

AI行业迎来关键转折:从“烧钱补贴”迈入“商业化定价”新阶段。被市场誉为“Token第一股”的迅策科技(03317)迎来重大利好。近期,国泰君安国际大幅上调其目标价至245港元 股。多重因素驱动下,迅策有望成为AI领域“千亿市值俱乐部”的有力竞争者。 中国AI实现弯道超车:成本优势构筑核心壁垒 全球
热门专题







热门推荐

2026年4月9日,阿里云旗下的AI开发平台“百炼”正式发布了名为“记忆库”的全新功能。这项功能的核心价值,在于为AI Agent赋予跨会话的长期记忆能力,旨在彻底解决多轮对话中信息丢失与遗忘的行业核心痛点。目前,该功能正处于限时免费公测阶段。官方性能数据显示,其在关键指标上表现突出:记忆检索性能大

今天外汇市场的表现,可以说是在平静中透着一丝韧性。北京时间下午四点半,在岸软妹币对美元汇率官方收盘价定格在6 7946。 这个数字背后有两个值得玩味的对比:一是比起前一个交易日的官方收盘价,小幅上扬了8个基点;二是相较于昨晚夜盘的收盘价,则回升了17个基点。虽然波动幅度不大,但这种日内低开后的企稳回

《遥遥西土》北境区域共有十个墓碑等待收集。首个墓碑位于地图北部悬崖下方,玩家需跳至崖底才能发现,其旁另有一座墓碑作为参照。具体位置与探索方法可参考相关视频攻略。

归环好彩骰”是游戏的核心机制,通过投掷骰子组合牌型获得奖励。它将叙事、战斗与成长深度整合,玩家的选择与骰点结果直接影响剧情走向和战斗效果。机制简单易上手,无时间压力,提供即时强反馈。游戏结合“万相卡”与角色流派,支持多样策略,平衡随机性,提升了内容探索深度与复用价值。

《植物大战僵尸》抽卡重置版已上线,核心玩法融合塔防与抽卡。游戏包含七阶卡池系统,顶级卡牌稀缺。新增超百种原创植物,僵尸行为更复杂,关卡设计多样。随机植物模式增加变数,roguelike元素提升重复可玩性。版本持续更新,社区活跃。