蛇年尾声,阿里更强大的千问模型登场。
2月16日除夕当天,阿里巴巴开源全新一代大模型千问Qwen3.5-Plus。千问3.5在文本和视觉的混合数据上预训练,实现了原生多模态的新突破,在推理、编程、Agent智能体等全方位基准评估中均表现优异,并在视觉理解能力的权威评测中斩获数项性能最佳。

Qwen3.5的核心突破在于从架构层面系统性破解了大型模型的“效率-精度”悖论。通过混合注意力机制,模型实现了对长文本的动态聚焦,告别了全量计算的算力浪费;而极致稀疏MoE架构则以不足5%的激活参数调动3970亿总参数的知识储备,将推理成本降至新低。
在效率跃升的同时,原生多Token预测能力让模型从“逐字蹦”进阶为“多步规划”,响应速度接近翻倍。通义团队斩获NeurIPS最佳论文的注意力门控等系列稳定性优化,则为这些激进创新提供了系统级保障,确保超大规模训练真正“跑得稳”。这四大技术共同指向一个目标:用更少的算力,唤醒更强的智能。
千问APP、PC端已第一时间接入Qwen3.5-Plus模型。开发者可在魔搭社区和HuggingFace下载新模型,或通过阿里云百炼直接获取API服务。
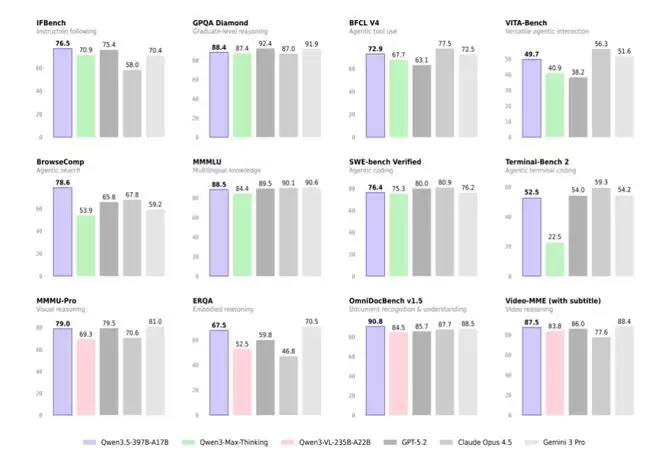
性能媲美Gemini 3 Pro ,且极具性价比
据阿里介绍,阿里巴巴开源全新一代大模型千问Qwen3.5-Plus,性能媲美Gemini 3 Pro,登顶全球最强开源模型。千问3.5实现了底层模型架构的全面革新,此次发布的Qwen3.5-Plus版本总参数为3970亿,激活仅170亿,以小胜大,性能超过万亿参数的Qwen3-Max模型,部署显存占用降低60%,推理效率大幅提升,最大推理吞吐量可提升至19倍。
价格方面,Qwen3.5-Plus的API价格每百万Token低至0.8元,仅为Gemini 3 pro的1/18。
四大技术突破:从架构创新到系统稳定
Qwen3.5的核心技术突破体现在四大创新维度。首先是混合注意力机制,它让模型学会“有详有略地读”。传统大模型处理长文本时,每个token需与所有上下文进行全量注意力计算,文本越长、算力消耗越大,这是制约长上下文能力的核心瓶颈。Qwen3.5通过动态分配注意力资源,对重要信息精读、对次要信息略读,实现了效率与精度的同步提升。
其次是极致稀疏MoE架构。传统稠密模型每次推理需激活全部参数,参数越多、算力成本越高。MoE架构的创新在于根据输入内容仅激活最相关的“专家”子网络,而Qwen3.5将这一思路推向极致——以3970亿总参数、仅激活170亿参数的稀疏架构,实现用不足5%的算力调动全部知识储备,大幅降低推理成本。

第三是原生多Token预测能力。传统模型采用逐token生成方式,推理效率受限。Qwen3.5在训练阶段即学会对后续多个位置进行联合预测,使推理速度接近翻倍。这一“多步规划”能力在长文本生成、代码补全、多轮对话等高频场景中,为用户带来接近“秒回”的响应体验。
最后是系统级训练稳定性优化,确保上述架构创新在超大规模训练中真正“跑得稳”。以通义团队斩获NeurIPS 2025最佳论文奖的注意力门控机制为例,该机制在注意力层输出端加入“智能开关”,像水龙头一样对信息流进行智能调控——既防止有效信息被淹没,也避免无效信息被过度放大,从而提升输出精度与长上下文泛化能力。此外,归一化策略优化、专家路由初始化等深层改进,分别解决不同环节的稳定性问题,共同保障模型在大规模训练中的稳健运行。
从“应答”到“操作”的人机交互新范式
与传统聊天机器人的本质区别在于,Qwen3.5不再满足于应答交互。其搭载的视觉智能体能力,使其能够像人类一样“观看”手机和电脑屏幕,精准理解界面元素的位置与功能,并自主执行操作。最新演示中,用户仅需通过自然语言下达指令,模型即可在移动端跨应用完成任务,或在PC端处理数据整理、多步骤流程自动化等复杂工作,将人机协作推向全新维度。
这一能力的实现,源于其先进的视觉理解技术。Qwen3.5能够精准定位屏幕元素,识别按钮、文本框、图标的坐标与功能属性,进而模拟点击、滑动、输入等操作。通过对屏幕内容的视觉编码与语义解析,AI真正具备了与数字世界交互的“视觉”与“手部”能力。用户可根据需求选择本地或云端部署,在计算效率与数据可控性之间灵活平衡。
跨应用协作则是Qwen3.5的另一突破。演示场景中,模型能够从邮件提取信息、读取表格数据、再通过通讯软件完成发送,这一系列操作打通了传统应用间的数据孤岛,将多步骤流程自动化变为现实。传统应用的隔离机制在AI智能体面前不再是障碍,因为它以“用户代理”的身份合法、高效地协同各应用,为用户创造无缝的数字体验。这种从单一工具向全能数字助手的进化,正为人机协作开辟全新的想象空间。
6分48秒,从一张草图到一段代码:Qwen3.5的“读心术”有多强?
更令人惊叹的是Qwen3.5所展现的视觉编程能力。在一段演示视频中,用户仅用手指了一个网页界面的草图,模型便在6分48秒内将其转化为结构清晰、可直接运行的网页代码,甚至自动匹配了高质量图片素材。这种“从草图到产品”的能力,展示了模型对视觉信息的深度理解,它不仅能识别圆形代表按钮、线条代表布局分隔,还能推断设计意图,理解“这是导航栏”“那是内容区”,并匹配对应的HTML、CSS和JavaScript代码逻辑。
深入技术细节会发现,这种能力源于Qwen3.5的原生多模态架构。与以往通过“视觉编码器+语言模型”简单拼接的方式不同,Qwen3.5在预训练阶段就实现了文本与视觉的深度融合,使模型能同时理解像素级位置信息与语义层面的抽象概念。数据显示,该模型的上下文窗口扩展至100万个token,可直接处理长达两小时的视频内容,这意味着它能够完整地观看一部电影,并将剧情、人物关系、视觉风格整理成文档或代码。这种跨模态的“全景”记忆能力,已经远远超出人类单次处理的信息量。




