IT之家2月13日获悉,英伟达昨日(2月12日)发布官方博文,宣布在AI推理领域的"token经济学"方面取得突破性进展,其Blackwell架构实现了里程碑式的技术跨越。
英伟达在文中强调,通过推行"极致软硬件协同设计"策略,该架构显著提升了硬件处理复杂AI推理任务时的效率,有效化解了因模型参数量激增带来的算力成本压力。数据显示,相较于前代Hopper架构,Blackwell平台将单位Token生成成本大幅降低至十分之一。
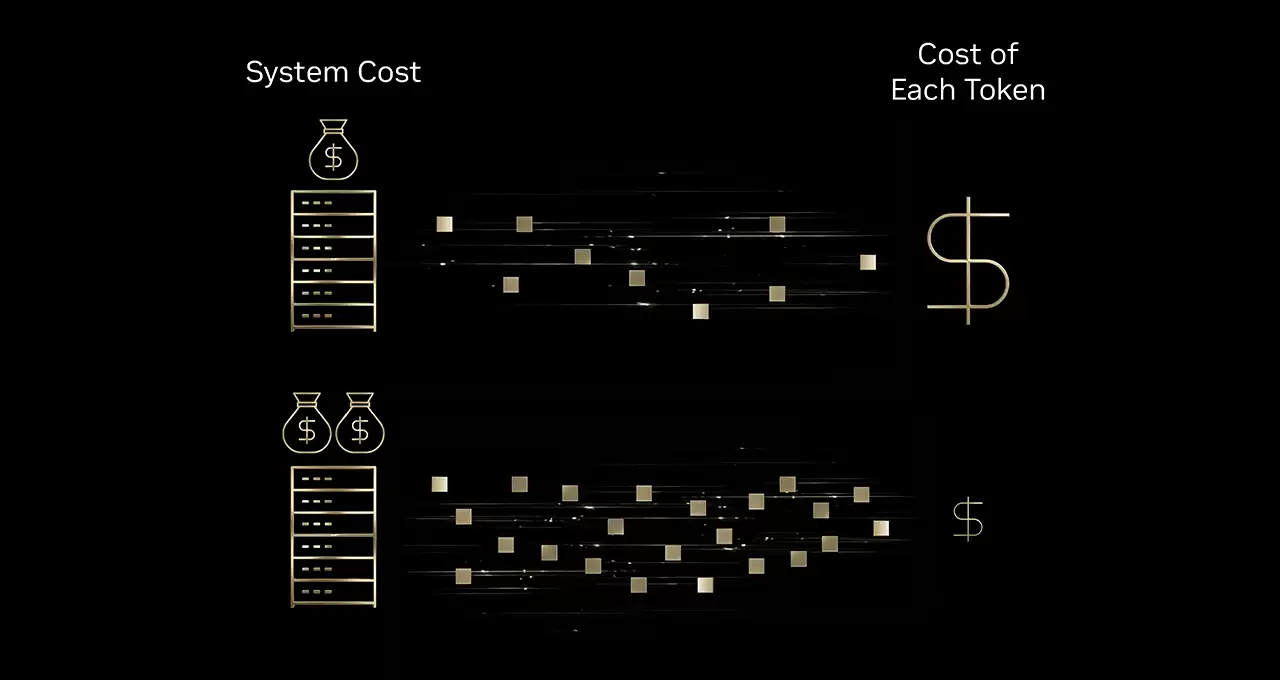
英伟达Blackwell架构实现AI推理成本压缩至十分之一
产业应用层面,包括Baseten、DeepInfra、Fireworks AI及Together AI在内的多家推理服务商已开始利用Blackwell平台托管开源模型。
据IT之家引述博文内容,英伟达指出通过整合前沿开源智能模型、Blackwell的硬件优势以及各厂商自研的优化推理栈,这些企业成功实现了跨行业的成本缩减。
英伟达通过整合开源前沿智能模型助力企业实现跨行业成本缩减
以专注多智能体工作流的Sentient Labs为例,其成本效率相较Hopper时代提升了25%至50%;而游戏领域的Latitude等公司也借此实现了更低延迟和更可靠的响应性能。

Sentient Labs成本效率相比Hopper时代提升25%至50%
Blackwell架构的高效能核心在于其旗舰系统GB200 NVL72。该系统采用72颗芯片互联配置,并配备了高达30TB的高速共享内存。这种设计完美契合当前主流的"混合专家"架构需求,能够将Token批次高效拆分并分散到各个GPU上并行处理。

GB200 NVL72系统采用72颗芯片互联配置
在Blackwell大获成功的同时,英伟达已将目光投向下一代代号为"Vera Rubin"的平台。据悉,Rubin架构计划通过引入针对预填充阶段的CPX等专用机制,进一步推高基础设施的效率天花板。




