2月11日,智谱正式发布新一代大模型GLM-5。摩尔线程基于SGLang推理框架,在旗舰级AI训推一体全功能GPU MTT S5000上,Day-0完成了全流程适配与验证。
凭借MUSA架构广泛的算子覆盖与强大的生态兼容能力,摩尔线程成功打通了模型推理全链路,并深度释放MTT S5000的原生FP8加速能力,在确保模型精度的同时显著降低了显存占用,实现了GLM-5的高性能推理。此次快速适配,不仅印证了MUSA软件栈的成熟度,更充分展现了国产全功能GPU对最新大模型即时、高效的支持能力。

GLM-5与MTT S5000的国产双强联合,将为开发者带来可对标国际顶尖模型的极致编程体验。无论是在函数补全、漏洞检测还是Debug场景中,该组合均表现卓越,以显著增强的逻辑规划能力,从容应对各类复杂的长程任务挑战。
GLM-5核心特性:
定义Agentic Engineering新高度
作为GLM系列的最新里程碑版本,GLM-5定位为当下顶尖的Coding模型,整体性能较上一代提升20%。其核心突破在于Agentic Engineering(代理工程)能力——不仅具备深厚的代码功底,更拥有处理复杂系统工程与长程Agent任务的实力,能够实现从需求到应用的端到端开发。
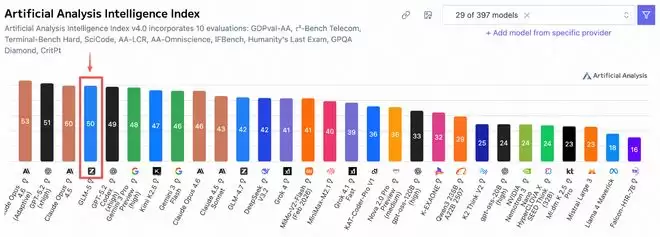
在全球权威的Artificial Analysis榜单中,GLM-5位居全球第四、开源第一。
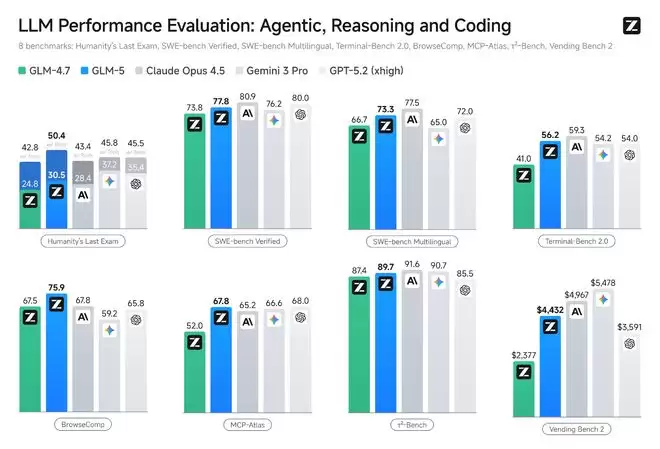
GLM-5在编程能力上实现了对齐Claude Opus 4.5,在业内公认的主流基准测试中取得开源模型SOTA。在SWE-bench-Verified和Terminal Bench 2.0中分别获得77.8和56.2的开源模型最高分数,性能超过 Gemini 3 Pro。

在内部Claude Code评估集合中,GLM-5在前端、后端、长程任务等编程开发任务上显著超越上一代的GLM-4.7(平均增幅超过20%),能够以极少的人工干预,自主完成Agentic长程规划与执行、后端重构和深度调试等系统工程任务,使用体感逼近Opus 4.5。
摩尔线程核心优势:软硬协同的全栈算力底座
MTT S5000是专为大模型训练、推理及高性能计算而设计的全功能GPU智算卡,基于第四代MUSA架构“平湖”打造。其单卡AI算力最高可达1000 TFLOPS,配备80GB显存,显存带宽达到1.6TB/s,卡间互联带宽为784GB/s,完整支持从FP8到FP64的全精度计算。
依托MUSA全栈平台,MTT S5000原生适配PyTorch、Megatron-LM、vLLM及SGLang等主流框架,助力用户实现“零成本”代码迁移。无论是构建万卡级大规模训练集群,还是部署高并发、低延迟的在线推理服务,MTT S5000均展现出对标国际主流旗舰产品的卓越性能与稳定性,旨在为行业筑牢坚实、易用的国产算力底座。
MTT S5000正式地址:
https://www.mthreads.com/product/S5000
此次实现对GLM-5模型的快速支持,正是摩尔线程基于MTT S5000构建的软硬协同技术能力的集中体现:
底层架构与生态兼容:天生适配,极速迁移
针对GLM-5的长序列推理场景,MTT S5000凭借充沛的算力储备与高计算密度,结合对稀疏Attention的架构级支持,在大规模上下文处理中依然保持高吞吐与低延迟。同时,MUSA软件栈的敏捷性是实现Day-0适配的关键。基于MUSA架构的TileLang原生算子单元测试覆盖率已超过80%,使得绝大多数通用算子可直接复用,显著降低移植成本,并能快速跟进前沿模型结构与新特性演进。
原生FP8加速:SGLang 框架深度优化
基于高性能的SGLang-MUSA推理引擎及MTT S5000的硬件原生FP8计算单元,摩尔线程实现了推理效率的跃升。与传统BF16相比,原生FP8在保持GLM-5卓越的代码生成与逻辑推理能力(精度无损)的同时,大幅降低了显存占用,并显著提升了推理吞吐量,为大规模部署提供了更高性价比的方案。
独创ACE引擎:通信计算并行,释放极致吞吐
针对大模型分布式推理中的通信痛点,MTT S5000利用独创的异步通信引擎(ACE),将复杂的通信任务从计算核心中卸载,实现了物理级的“通信计算重叠”。这一机制有效释放15%的通信被占算力,配合首创的细粒度重计算技术(将开销降至原有的1/4),全方位提升计算效率与系统吞吐量。
超长上下文支持:专为AI Coding打造
通过高效算子融合及框架极致优化,MTT S5000在确保代码生成质量的同时显著降低了响应延迟。无论是处理复杂的代码库分析,还是运行长周期的智能体(Agent)任务,均能保持首字延迟(TTFT)低、生成速度快的流畅体验。MTT S5000与GLM-5的软硬双强组合,在函数补全、漏洞检测等核心场景的表现超越同级,充分释放模型的规划能力和Debug能力,是执行长程开发任务的理想选择。
从GLM-4.6、GLM-4.7到GLM-5,摩尔线程已将“发布即适配”化为常态,这种对主流软件栈的无缝兼容与敏捷响应,充分证明了国产全功能GPU及MUSA软件栈的成熟度与稳定性,确保开发者能第一时间触达最新模型能力,从而携手共建蓬勃发展的国产AI生态。




