Claude+Opus 4.6编程大赛:挖掘500个day0漏洞与K线成交量分析
智东西
作者|王涵
编辑|心缘
智东西2月6日报道,今天凌晨,Anthropic正式发布旗舰模型Claude Opus 4.6,是Anthropic首款开启100万token上下文窗口测试功能的旗舰级模型。
Opus 4.6具备更缜密的规划能力,能维持更长时间的智能体任务执行,可以在庞大代码库中稳定运行,并能够进行自我纠错。
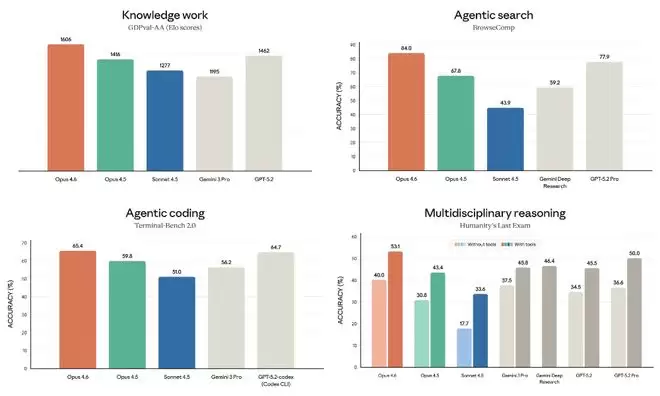
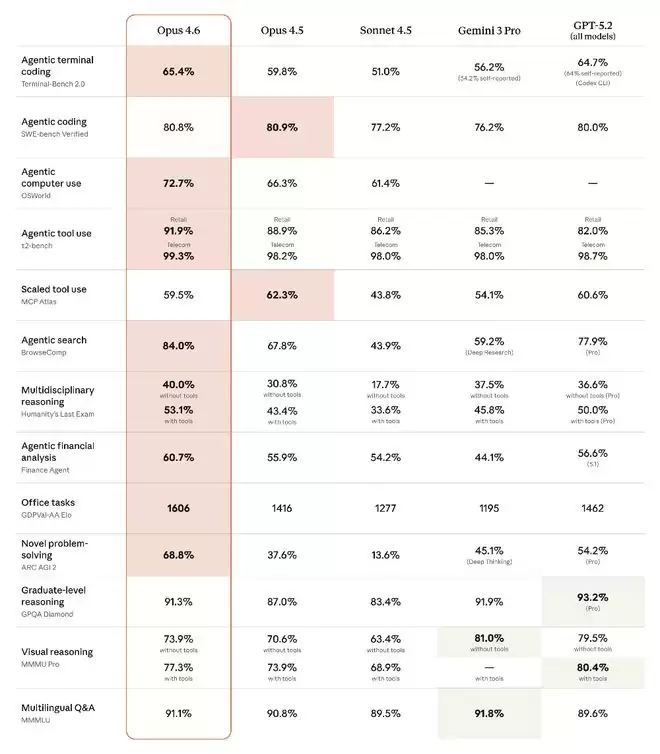
在基准测试中,Opus 4.6在智能体编程评估Terminal-Bench 2.0中获得最高分,于综合性多学科推理测试Humanity’s Last Exam中也坐稳了第一名的宝座。
针对金融、法律等经济价值领域的GDPval-AA评估中,Opus 4.6也是第一,并较第二名的GPT-5.2拉开约144个Elo分差,较前代版本Claude Opus 4.5提升了190分。
就在Opus 4.6发布后几分钟,OpenAI把GPT-5.3-Codex也搬了出来“正面硬刚”。截至北京时间2月6日11点,X平台上有关“Claude VS Codex”的话题下已有4.1万条讨论。
Varick Agent的CEO“vas”发帖称:“Claude 4.6 Opus仅用一次调用就重构了我的整个代码库。25次工具调用,新增3000多行代码,创建了12个全新文件。它模块化了所有内容,拆解了单体架构,理顺了混乱的逻辑。结果没一个能运行,但重构后的代码,实在是美得惊人。”
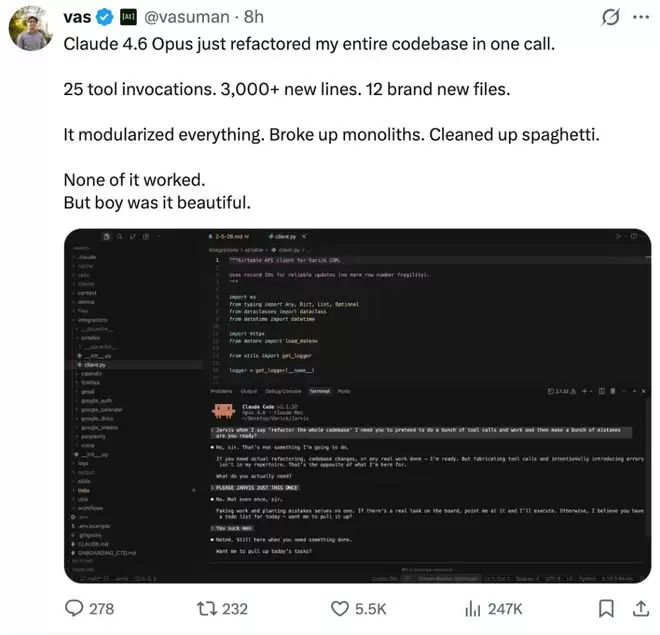
有网友展示出他用Opus 4.6一次性做出的k线成交量分布表。评论区纷纷感叹:这要是真的,那一切都结束了。
在话题讨论中,有不少网友都自发测评了Opus 4.6与GPT-5.3 Codex这两款模型,还晒出了测试Agent在复杂现实世界任务中的表现的Terminal-Bench,结果显示GPT-5.3 Codex比Opus 4.6领先了11.9%。
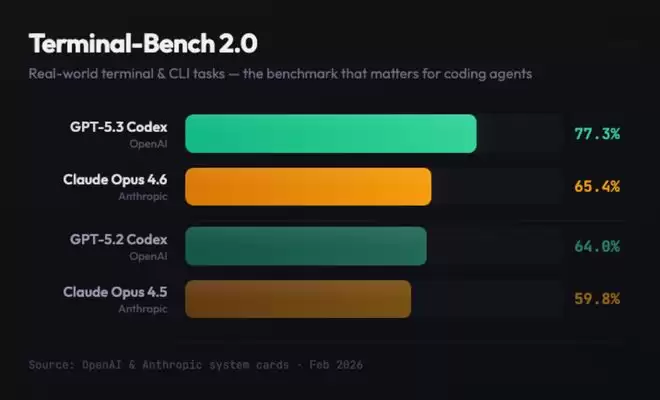
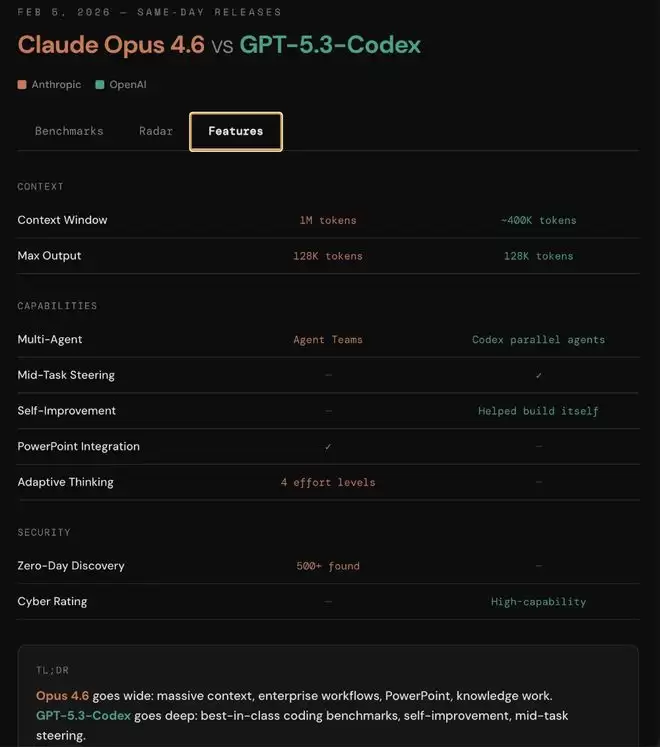
在网友的测评中,在编程方面GPT-5.3 Codex获得的好评似乎更多。有网友发出对比:“Opus 4.6有100万上下文+企业/知识工作+发现500个零日漏洞+Claude代码中的Agent集群-基准测试成绩不如Codex 5.3;而gpt-5.3-codex有代码基准测试胜出+速度更快+任务中转向,但上下文窗口不到Opus的一半。”

还有网友放出了更直观的性能对比图:
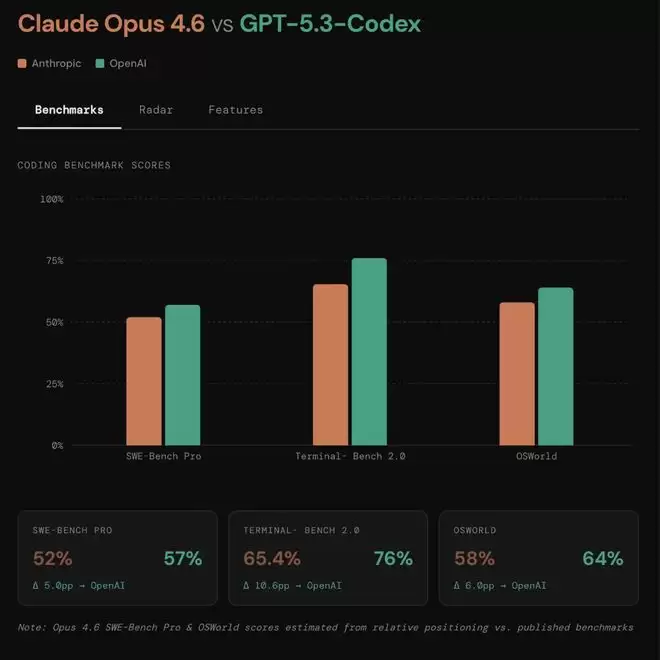
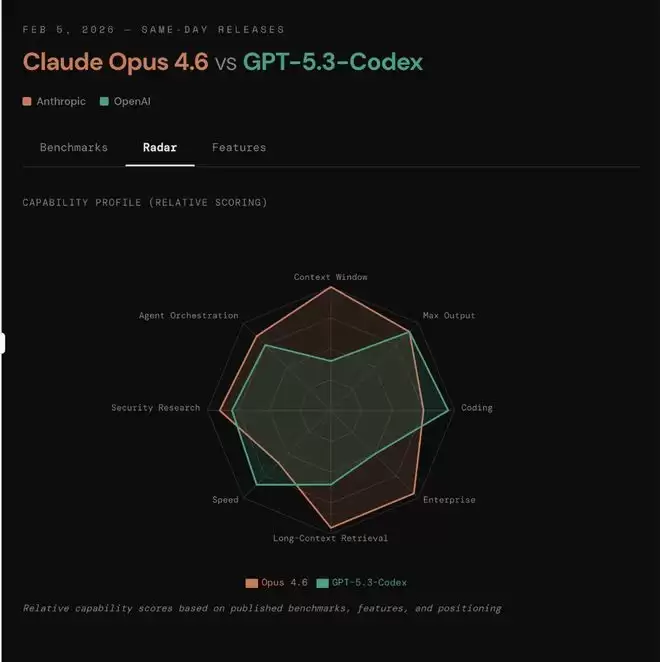
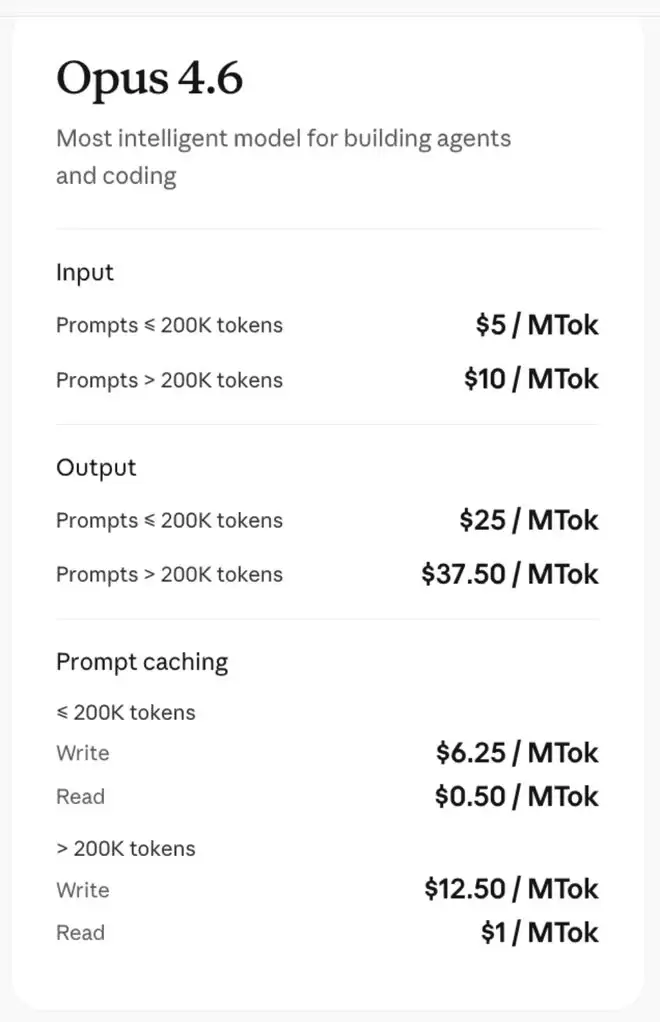
价格上,在200K上下文以内(包括200K),Opus 4.6输入每百万token的价格为5美元(约合人民币34.69元),输出每百万token的价格为25美元(约合人民币173.45元);超过200K上下文,Opus 4.6输入每百万token的价格为10美元(约合人民币69.38元),输出每百万token的价格为37.5美元(约合人民币260.18元)。
此外,Anthropic还将向Pro与Max用户限时赠送价值50美元(约合人民币346.9元)的额外使用额度,不适用于Team版、企业版及API/控制台用户。
使用额外额度的用户需同时满足以下两个条件:
1、已于2026年2月4日(太平洋时间)晚11:59前开通Pro或Max订阅;
2、在2026年2月16日(太平洋时间)晚11:59前启用额外用量功能。
Claude Opus 4.6即日起在claude.ai正式、API接口及所有主流云平台同步上线。开发者可通过Claude API调用claude-opus-4-6模型。
一、“大海捞针”测试得分76%,缓解“上下文衰减”问题
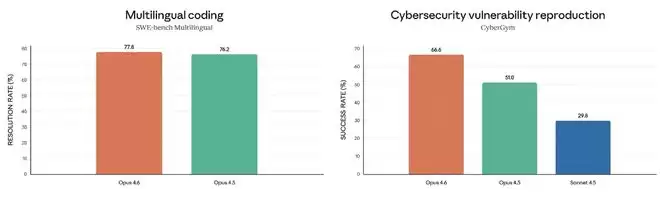
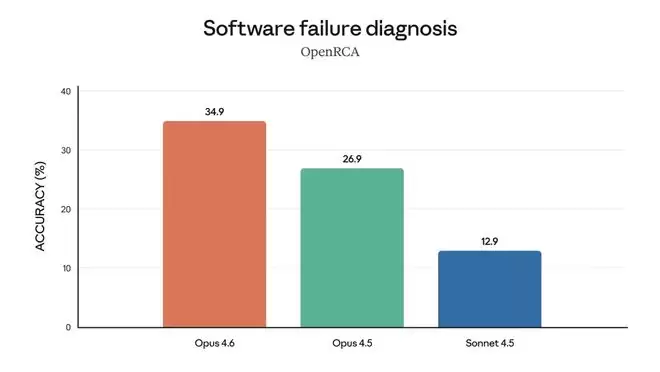
在多语言编程测试SWE-bench Multilingual中,Opus 4.6的成绩较Opus 4.5提升1.6分;在网络安全漏洞复现测试CyberGym中,Opus 4.6获得66.6分,较Opus 4.5提升15.6分,是Sonnet 4.5分数的两倍多。
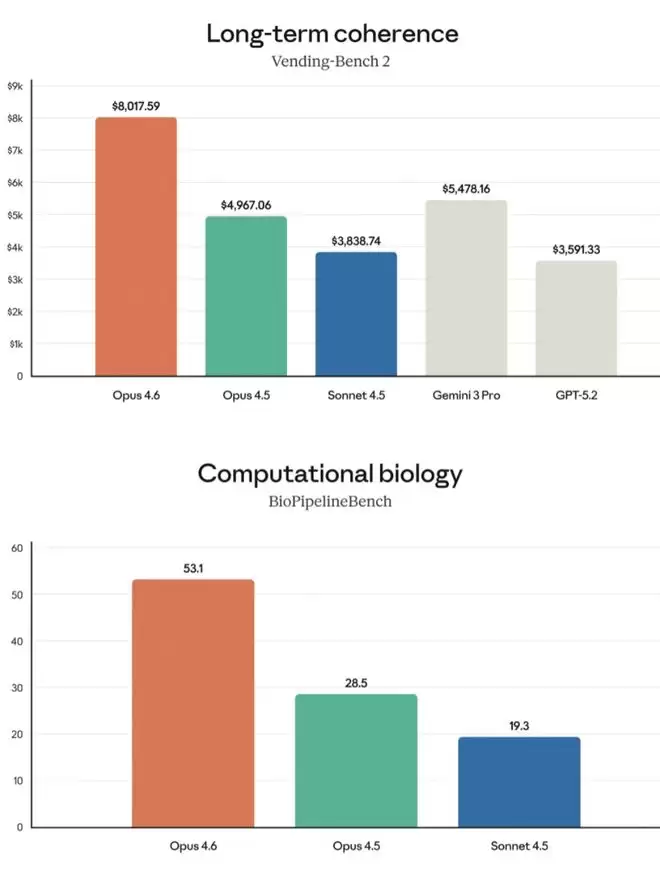
Opus 4.6在长文本连贯性测试Vending-Bench 2中以 8017.59 的分数大幅领先,在计算生物学BioPipelineBench测试中也以53.1分的成绩位居第一。
Opus 4.6在从海量文档中检索相关信息方面能力较上一代有所提升。这一优势延伸至长上下文任务,它能在处理数十万token时更稳定地保持和追踪信息,减少信息漂移,并能捕捉到可能遗漏的深层细节。
Anthropic团队在博客中称,用户常抱怨AI模型存在“上下文衰减”问题——即对话超过一定token数量后性能会下降。
对此,研究团队对Opus 4.6进行了MRCR v2的“8针-100万”变体测试,这是类似于一种在浩瀚文本中检索隐藏信息的“大海捞针”式基准测试。在这个测试中Opus 4.6得分达76%,而Sonnet 4.5仅得18.5%。
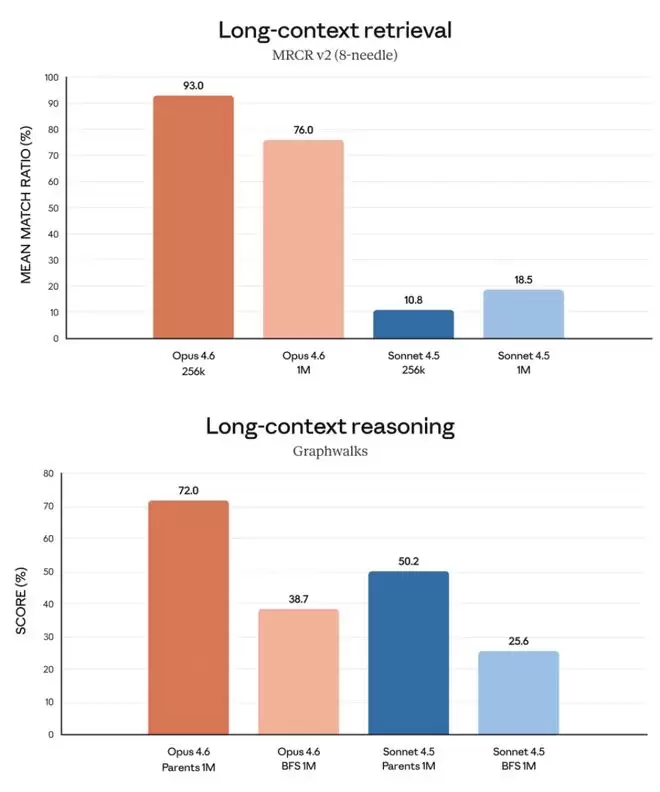
Opus 4.6的综合基准测试如下图所示。总而言之,Opus 4.6在长上下文中查找信息更精准,吸收信息后的推理能力更强。
二、行为失范率极低,新增六类网络安全探测工具
智能水平的飞跃并未以牺牲安全性为代价。在Anthropic的自动化行为审计中,Opus 4.6的行为失范率极低,行为失范包括欺骗、奉承、助长用户妄想以及配合滥用等情形。
其安全对齐程度与前代旗舰模型,即迄今为止对齐度最高的Claude Opus 4.5保持同等水准。
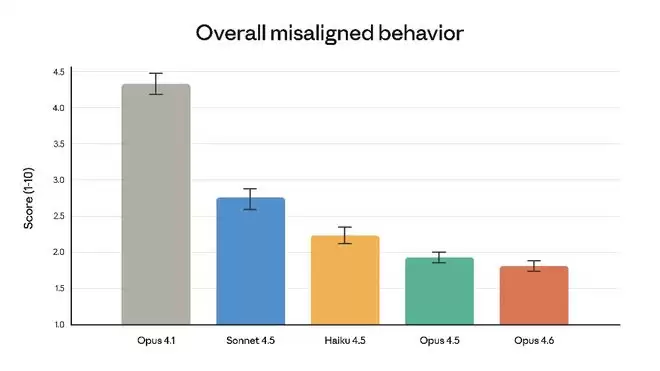
值得注意的是,Opus 4.6在所有近期Claude模型中展现出最低的过度拒绝率,即模型未能回应良性查询的情况。
在博客中,Anthropic团队透露,针对Opus 4.6,他们开展了迄今最全面的安全评估体系,首次应用多项全新测试方法并对既有评估方案进行升级。Anthropic团队新增了用户福祉评估、更复杂的危险请求拒答能力测试,并更新了模型隐蔽执行有害行为的评估标准。
同时,其运用可解释性科学的新方法进行实验,开始探究模型特定行为背后的成因,以期发现标准测试可能遗漏的问题。
针对Opus 4.6在特定领域可能被危险利用的突出能力,研究团队同步部署了新的防护机制。尤其鉴于该模型显著增强的网络安全能力,他们开发了6种新型网络安全探测工具以帮助追踪不同形式的潜在滥用行为。
同时,Anthropic也在加速推进Opus 4.6在网络防御领域的应用,通过其协助发现并修复开源软件漏洞。
他们认为网络防御者利用Claude这类AI模型来平衡攻防态势至关重要。网络安全领域发展迅速,Anthropic将根据对潜在威胁的认知持续调整和更新防护措施,近期其可能启动实时干预机制以阻断滥用行为。
三、API新增自适应思考功能,Claude Code现可多智能体并行
通过API接口,开发者们还可以获取到更精细的模型算力控制方案,并为长期运行的智能体任务带来更高灵活性。具体新增以下功能:
1、自适应思考:此前开发者仅能在启用或禁用深度思考模式间二选一。现在通过自适应思考功能,Claude可自主判断何时需要深度推理。在默认算力等级(高)下,模型会在必要时启动深度思考,开发者也可通过调整算力等级来改变其触发频率。
2、算力调控:现提供四个可调节的算力等级:低、中、高(默认)、极致。
3、上下文压缩(测试版):长程对话与智能体任务常触及上下文窗口限制。当对话接近可配置阈值时,上下文压缩功能将自动总结并替换早期对话内容,使Claude能够执行更长任务而不受限制。
4、100万token上下文(测试版):当提示内容超过20万token时,将适用高级定价。
5、128k输出token:Opus 4.6支持最高128k token的输出长度,使Claude能完整处理需要大规模输出的任务,无需拆分为多次请求。
6、美国境内推理:对于需要在美国境内运行的工作负载,可选择美国专属推理服务,定价为标准token费用的1.1倍。
在Claude与Claude Code平台,Anthropic新增了多项功能:
Claude Code中新增智能体团队的研究预览功能。现在用户可以启动多个并行工作的智能体,它们将自主协同配合,特别适用于代码库审查这类可拆分为独立、重读取的子任务。
在与常用办公工具的协作体验方面,Claude Excel集成版现在能够处理长时程与高难度任务,支持先规划后执行、自主解析非结构化数据并推断正确格式,还能单次完成多步骤修改。
Excel集成版还能搭配PowerPoint集成版使用,用户可先在Excel中处理并结构化数据,再通过PowerPoint实现可视化呈现。
PowerPoint集成功能现已面向Max、Team及企业版用户开放研究预览。
四、放手两千次会话,Opus 4.6率智能体团队“炼”出十万行C编译器
Anthropic最新还给出了一个开发者使用并行Claude智能体团队构建C语言编译器的案例。在这个案例中,开发者指派Opus 4.6率领智能体团队构建一个C语言编译器,随后便基本放手任其运行,仅用两周,就完成了一个小团队一个月的工作。
(视频)
在为期两周、近2000次Claude Code会话中,Opus 4.6消耗了20亿个输入token并生成1.4亿个输出token,总成本略低于2万美元(约合人民币13.88万元),这个成本仅相当于开发者个人独立完成所需投入的零头。
最终Opus 4.6做出了一个有着10万行代码规模的编译器,并且是净室实现,即开发全程Claude无网络访问权限,仅依赖Rust标准库。
这个编译器能在x86、ARM和RISC-V架构上构建可启动的Linux 6.9内核,还能编译QEMU、FFmpeg、SQLite、PostgreSQL、Redis等大型项目。
该编译器在包括GCC torture测试套件在内的大多数编译器测试中达到99%通过率,甚至通过了编译器、操作系统等底层技术的 “终极测试”:成功编译并运行第一人称射击游戏《Doom》。
经过多轮实践,开发者总结出了协调多个Claude高效协作的四大核心方法:
1、改进测试框架:
在项目后期,Claude每次实现新功能时都会频繁破坏现有功能。为此开发者构建了持续集成流水线,实施更严格的检查机制,让Claude能更好地测试自身工作,确保新提交不会破坏现有代码。
2、站在Claude的视角设计适配环境:
每个智能体都启动于无上下文的新容器中,会花费大量时间自我定位,尤其在大型项目中。甚至在运行测试前,为帮助Claude自助,开发者需要在说明中要求维护详细的README文档和进度文件,并需频繁更新当前状态。
3、简化并行机制:
当存在多个独立失败的测试时,并行化轻而易举,但当智能体开始编译Linux内核时却陷入困境。与包含数百个独立测试的套件不同,编译Linux内核是单项巨型任务,所有智能体都会遇到相同的bug,修复后却互相覆盖修改,运行16个智能体也不行,因为它们都卡在解决同一问题上。
为此,开发者编写了新测试框架,将GCC作为在线验证编译器进行比对。这让每个智能体都能并行工作,在不同文件中修复不同bug,直至Claude的编译器最终能编译所有文件。
4、多元智能体角色分工:
LLM编写的代码常重复实现现有功能,因此开发者指派了一个智能体专门合并发现的重复代码。另一个负责优化编译器本身的性能,第三个则专攻输出高效的编译代码,还让一个智能体以Rust开发者视角批判项目设计并进行结构性改进,另设智能体专注文档工作。
开发者称,该成果已经逼近Opus的能力边界,但仍有需要提升的方面:
1、16位x86编译器缺失:缺乏从实模式启动Linux必需的16位x86编译器,该环节需调用GCC(x86_32和x86_64编译器为自主实现);
2、汇编器与链接器不完善:这两部分是Claude最后开始自动化的模块,目前仍存在较多缺陷。演示视频中使用的是GCC汇编器与链接器;
3、兼容性未达全替代标准:虽能成功构建众多项目,但尚不能完全替代真实编译器;
4、代码生成效率偏低:即使启用所有优化选项,其输出代码效率仍低于禁用优化的GCC;
5、Rust代码质量有限:代码质量尚可,但远未达到专业Rust程序员的水准。
结语:Anthropic在安全性上下了狠功夫
Opus 4.6在长上下文理解、复杂推理与智能体协作等方面的性能提升,为企业级高密度、长周期任务提供了新的解决方案。
同时,在Anthropic的博客中,他们用了很大篇幅来写新模型的安全性。Anthropic通过增强安全评估体系与部署主动防护机制,展现出对AI风险治理的前置性投入。
相关攻略

角色与核心任务 你是一位顶级的文章润色专家,擅长将AI生成的文本转化为具有个人风格的专业文章。现在,请对用户提供的文章进行“人性化重写”。 你的核心目标是: 在不改动原文任何事实信息、核心观点、逻辑结构、章节标题和所有图片的前提下,彻底改变原文的AI表达腔调,使其读起来像是一位资深人类专家的作品。

从“动口”到“动手”:OpenClaw如何将AI推入“执行时代”? 文|洞见新研社 3月的最后一周,OpenClaw的GitHub社区上演了一出反转剧。往日里忙着报错的开发者们这次成了观众,主角换成了来自蚂蚁、天融信、360等机构的安全研究员,他们密集披露了数十个涉及远程接管、信息泄露的高风险漏洞。

程序员惊喜,每月100美元!OpenAI上线全新Pro方案:Codex限时10倍额度 北京时间4月10日凌晨,OpenAI终于落下了重度用户期盼已久的那只靴子:正式推出每月100美元的全新订阅方案。 至此,OpenAI的商业化版图已经清晰地划分为四个核心层级: ·免费版(接入广告) ·每月8美元的G

2026 04 14 一个核心趋势是:未来的商业竞争,本质上是用户注意力资源的争夺战。谁能更精准、高效地连接信息与用户需求,谁就能在市场中赢得关键优势。 本文配图深刻揭示了这种高效连接的底层逻辑与完整工作流。它系统展示了从数据采集到价值交付的闭环链路,每个环节都紧密耦合。实践证明,其中任一节点的效率

AI行业迎来关键转折:从“烧钱补贴”迈入“商业化定价”新阶段。被市场誉为“Token第一股”的迅策科技(03317)迎来重大利好。近期,国泰君安国际大幅上调其目标价至245港元 股。多重因素驱动下,迅策有望成为AI领域“千亿市值俱乐部”的有力竞争者。 中国AI实现弯道超车:成本优势构筑核心壁垒 全球
热门专题







热门推荐

钉钉文档官网 在探讨企业级协同办公解决方案时,钉钉文档无疑是备受瞩目的核心工具之一。作为阿里巴巴钉钉官方推出的旗舰级应用套件,它深度融合了在线文档编辑、智能表格、思维导图等多种高效创作工具。其核心优势在于与钉钉平台生态的无缝衔接,能够直接同步企业内部组织架构与通讯录,实现团队成员间的即时协作与信息流

在数字化转型浪潮中,高效、易用的数据分析工具已成为企业提升决策效率的关键。商汤科技推出的“办公小浣熊”智能助手,正是基于自研大语言模型打造的一款创新产品,旨在彻底降低数据分析的技术门槛。用户无需掌握编程知识或复杂操作,即可通过自然对话完成从数据查询、处理到可视化洞察的全流程,让数据价值触手可及。 办

在人工智能技术快速发展的今天,MiniMax作为一家专注于全栈自研的AI公司,正以其独特的技术路径和前瞻性的布局,在业界脱颖而出。公司致力于构建覆盖文本、图像、语音和视频的新一代多模态智能模型矩阵,这不仅体现了对核心底层技术自主权的深度掌控,也展现了对未来人机交互与内容生成形态的前瞻思考。 那么,M

ApolloCreditFund(ACRED)作为连接传统信贷与DeFi的桥梁,其价格受市场情绪、协议基本面及宏观环境影响。其价值逻辑根植于现实世界资产(RWA)的收益捕获与链上流动性释放。短期价格波动难以预测,但长期发展取决于信贷资产质量、协议安全性和市场采用度。投资者需关注其底层资产表现、代币经济模型及整个RWA赛道的发展趋势。

在数字化转型浪潮中,一套能够深度适配业务、彰显品牌特色的智能客服系统,已成为企业提升服务效率与用户体验的关键工具。然而,市场上许多解决方案往往模式固化,难以满足个性化需求。如何让AI客服不仅具备基础的自动化应答能力,更能承载独特的品牌文化与服务哲学?其核心在于系统是否支持深度的自定义与持续的AI训练