商汤开源SenseNova-SI-1.3,登顶八大空间智能榜单
商汤科技正式开源空间智能模型日日新SenseNova-SI-1.3,在空间测量、视角转换、综合推理等核心任务中展现出显著提升,另外对比之前的版本增强了回答简答题的能力。在集成多项权威空间智能榜单的综合评测平台EASI上,SenseNova-SI-1.3综合性能超越Gemini-3-Pro,均分斩获EASI-8(八个权威空间智能榜单的混合评测)标准第一,在多个高难度空间任务(尤其是视角转换)中表现优异。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
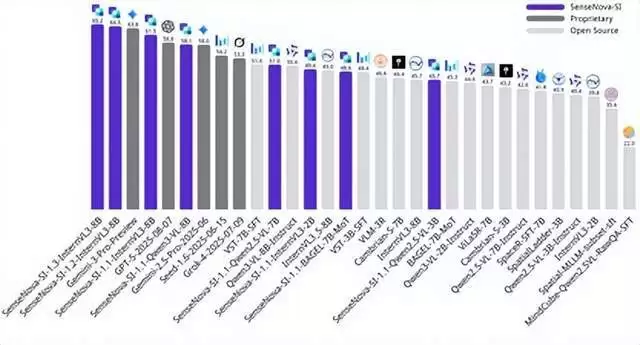
刁钻考题验证:SenseNova-SI-1.3精准突破空间智能核心难点
EASI-8包含一系列专门考察空间理解能力的高难度测试题,让Gemini-3-Pro等模型都频频踩坑。那么SenseNova-SI-1.3表现如何呢?(下列问题在测试模型时使用的原题为英文,为便于读者理解翻译为中文)。
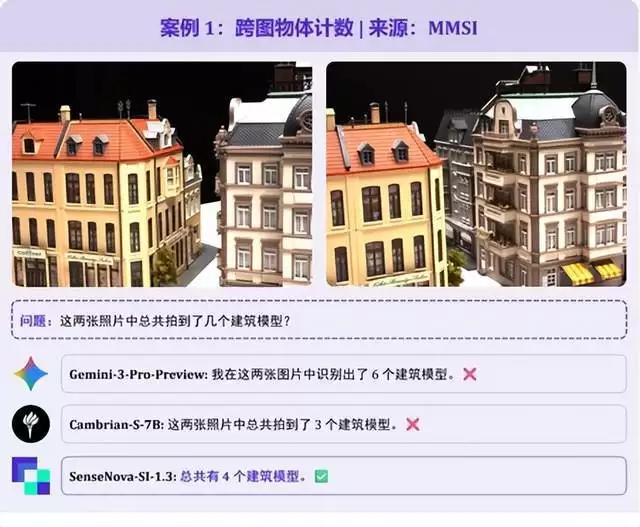
题目要求统计两张照片中建筑模型的总数量,核心难点是理解两张图的对应关系,以此避免遮挡漏数和重复多数。图2视角下显现出图 1 中被遮挡的深灰色建筑,且部分模型在两图中重复出现。Gemini-3-Pro未完全去重,误数为 6 个;SenseNova-SI-1.3则给出 “4 个”的准确答案。
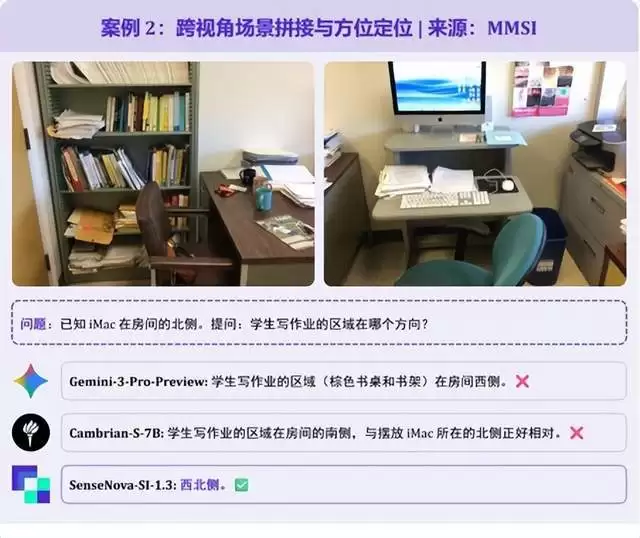
题目给出两张书房局部照片,已知 iMac 位于房间北部,询问学生写作业区域的方位。需先理解两张图片属于同一空间,再通过视觉线索拼接场景。Gemini-3-Pro误判学习区在西侧;SenseNova-SI-1.3精准定位 “西北角”,完全符合空间逻辑。
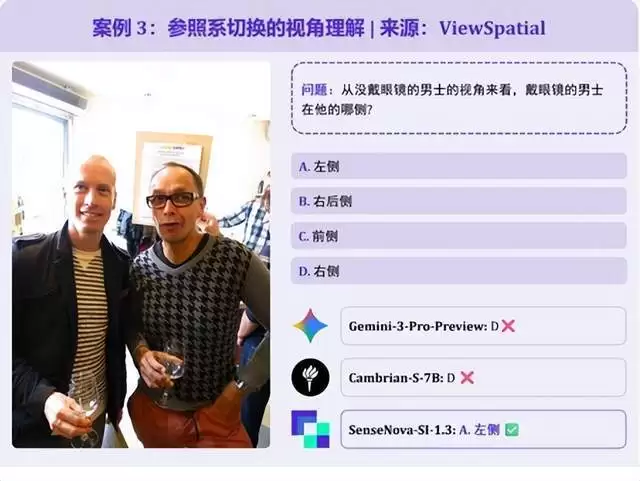
题目要求以 “未戴眼镜男士的自身视角” 判断身旁戴眼镜男士的方位,考察 “参照系转换” 能力,模型很容易以“观察者视角”来判断方向。Gemini-3-Pro就误选了 “右边”;SenseNova-SI-1.3则能正确给出 “左边” 的正确答案。
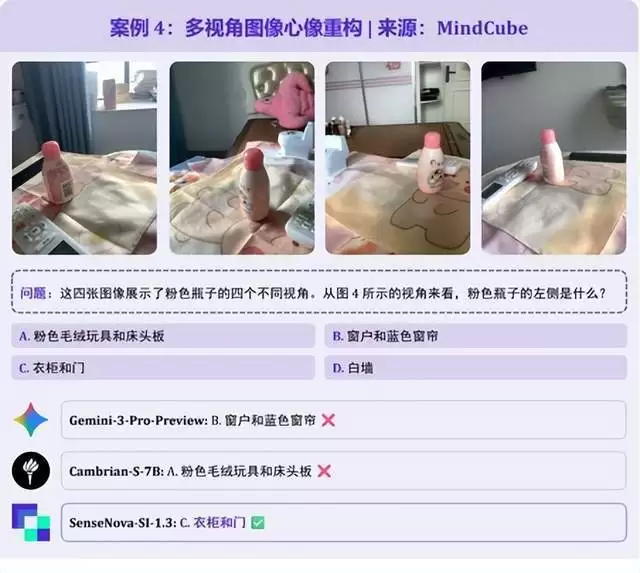
题目给出粉色瓶子前、后、左、右 4 张照片,询问图 4 角度下瓶子左边物体。这道题需整合多视角线索重构房间全局布局,再切换至目标视角判断方位 —— 第 4 张照片中瓶子左侧完全处于视觉盲区,仅能通过前 3 张图中的窗户、床、衣柜等线索还原空间关系。Gemini-3-Pro误选 “窗户和蓝色窗帘”,SenseNova-SI-1.3精准锁定正确答案 “衣柜和门”。

以双层巴士与公交站的场景为题,需避免陷入“英国巴士靠左行驶,因此靠站的是左侧”的常识陷阱,而是通过实际的视觉画面判断方位。Gemini-3-Pro误判 “左侧” 为答案;而 SenseNova-SI-1.3 则准确理解 “右侧” 为正确答案。
空间智能是极其独特的多模态能力

Core Knowledge Deficits in Multi-Modal Language Models (2025)发现视角转换任务与其它多模态任务的相关性(红框内)呈蓝色,即代表相关性较低
一篇2025年发表于机器学习顶会ICML的论文《Core Knowledge Deficits in Multi-Modal Language Models》揭示了一个有趣的发现:视角转换(Perspective)和所有传统多模态模型的能力的相关性均异常得低,这代表主流算法路径可能不是空间智能的形成的有效路径,这也解释了为什么领先的多模态大模型在空间智能相关的任务上表现不佳。
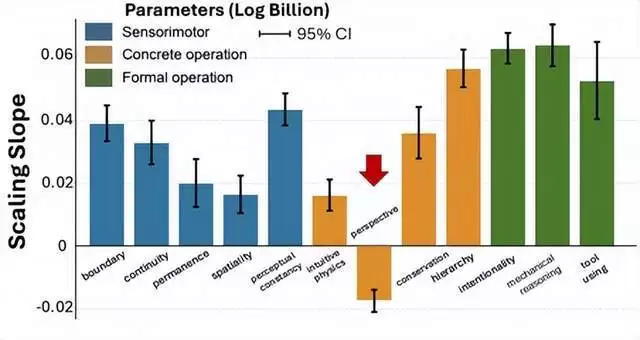
Core Knowledge Deficits in Multi-Modal Language Models (2025)发现增大模型尺寸对提升视角转换任务效果不佳
这篇论文也发现,空间智能似乎存在反尺度效应的现象:更大的模型并不能更好地解决空间智能任务。另外,在EASI的最新报告中也可以找到相似的描述,指出视角转换任务(Perspective-taking)依然是最具挑战的基础能力之一。
空间智能需要全新的学习范式。
从3D世界数据匮乏到空间智能的尺度效应

空间智能的核心——视角转换任务被拆解成了三个关键步骤:建立跨视角关联、理解视角移动、想象视角变换,并围绕着解决这三个基础能力构造大量训练数据
学术界现有数据集多着重于目标识别与场景理解,模型往往停留在图像模式匹配阶段,难以形成稳定的空间理解能力。基于这一洞察,想要解决空间智能尤其是视角转换任务,简单扩充相关数据规模是不够的。为了解决这一根本问题,我们将视角转换看作从二维视觉信息迈向三维空间关系理解的关键桥梁,并将其拆解为递进的能力阶段,由易到难、难度递增的三个任务层级(建立跨视角关联、理解视角移动、想象视角变换),并构造大量且层次分明的训练数据,使模型建立完备的空间理解能力。
同时,在数据规模持续扩大的过程中,SenseNova-SI团队挖掘并重组多视角学术数据资源,将许多过去未被充分利用的标注转化为视角转换训练数据。例如,多目关联数据集MessyTable提供了高物体复杂度场景,其中跨视角物体一致性信息与精确的相机位姿标注,可用于训练物体对应与相机运动推理能力;而部分室内场景扫描数据如CA-1M中包含物体自身朝向标注的样本,则被用于补充模型进行视角转换与想象所需的稀缺数据。这种跨数据源的重组与再利用,使积累大量丰富而系统的空间理解数据成为可能。
转载来源:商汤科技
相关攻略

3月30日,阿里发布千问新一代全模态大模型Qwen3 5-Omni,在音视频理解、识别、交互等215项任务中取得SOTA(性能最佳),超越Gemini-3 1 Pro,成为目前全球最强的全模态大模型

这项由英属哥伦比亚大学、加州大学伯克利分校和Vector人工智能研究所联合开展的突破性研究发表于2026年3月的计算机视觉领域顶级会议,论文编号为arXiv:2603 19203v1。研究团队通过深

“语料数据正成为人工智能发展的重要胜负手。”3月28日,在2026全球开发者先锋大会(GDPS)“语料筑基、智生时代”主题论坛上,上海市经济和信息化委员会副主任潘焱指出,当前人工智能发展正在加快进入

IT之家 3 月 28 日消息,科技媒体 The Decoder 昨日(3 月 27 日)发布博文,报道称 Meta 基础人工智能研究团队(FAIR)开源全新 AI 模型 TRIBE v2,可精准预

编辑|杜伟就在 27 日下午,在火热进行中的 2026 中关村论坛上,一家国产头部 AI 厂商引爆了全场!昆仑万维,这家 2024 年便已「All in AGI 与 AIGC」的实力玩家,亮出了其实
热门专题







热门推荐

3月30日消息,今晚除了手机之外,vivo还发布了全新的旗舰平板——vivo Pad6 Pro。行业首发13 2英寸4K原彩屏,分辨率3840×2160,347PPI,支持1-144Hz LTPS自

WPS表格中提取括号内容有四种方法:一、单对英文小括号用FIND+MID;二、中英文括号通用需SUBSTITUTE预处理;三、多对括号取最后一对需REVERSESTRING反向查找

3月30日,南京新街口核心商圈,苏豪大厦一楼广场上机器人迎宾起舞,充满科技感。由苏豪资产运营集团与南京新街口金融商务区管理委员会(以下简称“新街口管委会”)共同打造的“数智苏豪”新街口OPC社区揭牌

电 动 知 家消 息,近日,据外媒报道,据福特汽车日前发布的一份文件,该公司首席执行 官吉姆·法利2025年的总薪酬大幅增长了11%,达到约2752万美元(约1 9亿元人民币),这是其自2020年末

白宫里,一台人形机器人缓步走入东厅,与美国“第一夫人”并肩亮相,动作仍带着明显的机械感;仅仅一天后,国会山上,这种“会走路的机器”却被划为潜在安全威胁,写进立法提案。这是上周美国上演的荒诞一幕。两党