据IT之家2月4日消息,阿里旗下千问团队正式发布Qwen3-Coder-Next模型。这是一款专为代码辅助与本地开发场景设计的开源大型语言模型,拥有开放的模型权重。
该模型基于Qwen3-Next-80B-A3B-Base架构构建,创新性地采用了混合注意力机制与MoE(专家混合)相结合的全新架构。通过对大规模可执行任务合成、环境交互反馈与强化学习进行系统的智能体训练,在显著降低推理成本的同时,获得了强大的编程与智能体任务执行能力。
以下是IT之家整理的最新详细介绍:
拓展智能体训练
Qwen3-Coder-Next并不依赖于简单的参数规模扩展,而是将重点聚焦于扩展智能体训练信号。研发团队利用大规模可验证的编程任务与可执行环境进行训练,使模型能够直接从环境反馈中持续学习与进化。整个训练过程主要包含以下环节:
在以代码与智能体为中心的优质数据上进行持续预训练。在包含高质量智能体执行轨迹的数据上进行监督微调。通过领域专精的专家训练(涵盖软件工程、质量保证、Web/用户体验等),将专家能力蒸馏至一个统一的、可部署的模型之中。
这一方案特别强调长程推理、工具调用以及从执行失败中恢复与学习的能力,这些对于现实世界中的编程智能体至关重要。
在编程智能体基准上的表现
下图汇总了模型在多个广泛使用的编程智能体基准上的表现,包括SWE-Bench(Verified、Multilingual、Pro)、TerminalBench 2.0以及Aider。
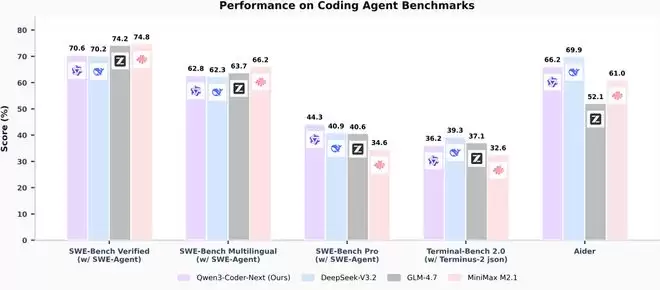
图中数据显示:
在使用SWE-Agent框架时,Qwen3-Coder-Next在SWE-Bench Verified基准上的通过率超过70%。在多语言设置以及更具挑战性的SWE-Bench-Pro基准上,其表现依然保持竞争力。尽管激活参数量较小,该模型在多项智能体测评中仍能匹敌甚至超越若干规模更大的开源模型。效率与性能的平衡
下图直观展示了Qwen3-Coder-Next如何在推理效率与任务性能之间取得更优的帕累托平衡。

这一对比清晰体现了其在效率上的优势:
Qwen3-Coder-Next(3B激活参数)在SWE-Bench-Pro上的表现,足以与激活参数量高10到20倍的模型相媲美。尽管专用的全注意力模型在绝对性能上仍保持领先,但Qwen3-Coder-Next在面向低成本智能体部署方面,处于极具优势的帕累托前沿。总结与未来工作
Qwen3-Coder-Next在编程智能体基准上展现出良好前景,在实用场景中具备了不错的速度与推理能力。尽管其表现可与部分更大的开源模型竞争,但仍有广阔的改进空间。
展望未来,我们认为强大的智能体能力——例如自主使用工具、应对复杂难题、管理多步骤任务——是打造更优秀编程智能体的关键。接下来,团队计划持续提升模型的推理与决策能力、支持更多复杂任务类型,并根据实际使用反馈进行快速迭代与更新。
开源地址
ModelScope:
Hugging Face:




