腾讯AI科学家姚顺雨入职后首发重要研究成果
IT之家 2 月 3 日消息,腾讯混元正式技术博客(Tencent HY Research)今日(2 月 3 日)上线并发表了一篇名为《从 Context 学习,远比我们想象的要难》的文章,系统介绍了腾讯混元团队联合复旦大学的一项新研究。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
这是姚顺雨加入腾讯担任首席 AI 科学家后带领团队首次发布研究成果,也是腾讯混元技术博客首次公开。这一博客的推出,旨在分享腾讯混元研究员在前沿技术研究和实践中的探索与经验。
博客提到,过去几年,大语言模型的进化速度快得令人惊叹。如今的前沿模型,已经是顶级的“做题家”:它们能解开奥数级别的难题,能推演复杂的编程逻辑,甚至能通过那些人类需要苦读数年才能拿下的专业资格考试。
然而,这些耀眼的成绩单可能掩盖了一个真相:能在考场拿满分的学生,未必能胜任真实世界的工作。
回看我们人类的日常工作:开发者扫过从未见过的工具文档,就能立刻开始调试代码;玩家拿起新游戏的规则书,在实战中边玩边学;科学家从复杂的实验日志中筛选数据,推导出新的结论和定律。我们发现在这些场景中,人类并不只依赖多年前学到的“死知识”,而是在实时地从眼前的 Context 中学习。
然而,今天的语言模型并非如此。它们主要依赖“参数化知识”—— 即在预训练阶段被压缩进模型权重里的静态记忆。在推理时,模型更多是在调用这些封存的内部知识,而不是主动从当前输入的新信息中汲取营养。
这揭示了当前模型的训练范式和在真实场景中应用之间是不匹配的:我们优化出的模型擅长对自己“已知”的事物进行推理,但用户需要的,却是让模型解决那些依赖于杂乱、动态变化的 Context 的任务。
简而言之:我们造出了依赖“过去”的参数推理者,但世界需要的是能吸收“当下”环境的 Context 学习者。要弥合这一差距,我们必须从根本上改变模型的优化方向。
为了衡量现有模型距离真正的“Context Learner”还有多远,姚顺雨团队构建了 CL-bench。这是一个专门评测语言模型能否从 Context 中学习新知识并正确应用的基准。

CL-bench 包含由资深领域专家精心制作的 500 个复杂 Context、1,899 个任务和 31,607 个验证标准。CL-bench 只包含一个简单但苛刻的要求:解决每个任务要求模型必须从 Context 中学习到模型预训练中不存在的新知识,并正确应用。
具体来说,CL-bench 涵盖了四种广泛的现实世界 Context 学习场景:
领域知识推理: Context 提供特定的领域知识(例如,虚构的法律体系、创新的金融工具或小众专业知识)。模型需要利用这些知识来推理并解决具体问题。规则系统应用:Context 提供新定义的正式系统(例如,新的游戏机制、数学形式体系、编程语法或技术标准)。模型必须理解并应用这些规则来执行任务。程序性任务执行:Context 提供复杂的过程系统(例如,工作流、产品手册和操作指南)。模型必须理解并应用这些程序性信息来完成任务。经验发现与模拟: Context 提供复杂系统内的实验数据、观测记录或模拟环境。与前几类涉及演绎推理不同,这一类专注于归纳推理,也是最具挑战性的。模型必须从数据中发现潜在的定律或结论,并应用它们来解决任务。
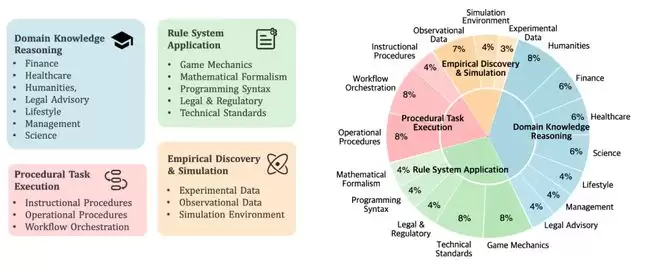
这些类别包含了大部分现实世界工作中常见的演绎推理和归纳推理任务,能充分衡量模型的 Context 学习能力。
为了确保性能真正反映 Context 学习,而不是记忆或数据泄露,CL-bench 采用了无污染(Contamination-free)设计:
虚构创作:专家创作完全虚构的内容,例如为虚构国家设计一套完整的法律体系(包括新颖的判例和法律原则),或创建具有独特语法和语义的新编程语言。现有内容的修改:专家修改现实世界的内容以创建变体,例如更改历史事件、改变科学和数学定义,或修改技术文档和标准。整合小众和新兴内容:专家纳入了在预训练数据集中代表性极低的小众或近期新兴内容,如前沿研究发现、新发布的产品手册或技术文档,以及来自专门领域的特定知识。
在不提供任何 Context 的情况下,最先进的模型 GPT-5.1 (High) 仅能解决不到 1% 的任务。这证明了数据是无污染的,模型若不从 Context 中学习,几乎完全无法解决这些任务。
此外,CL-bench 的设计具有高复杂性和序列依赖性。51.1% 的任务需要序列依赖,意味着后续任务的解决方案取决于早期交互的结果。这种多轮次设计显著增加了任务难度。平均而言,领域专家花费约 20 小时标注每个 Context ,以确保任务构建的质量和深度。
CL-bench 中的每个任务都是完全可验证的。平均而言,每个 Context 关联 63.2 个验证标准,每个任务包含 16.6 个评估标准。每个任务的正确性都从多个角度进行评估,确保了评估的全面性。
该团队在 CL-bench 上评估了十个最先进的语言模型。结果揭示了清晰且一致的差距。
平均而言,模型仅解决了 17.2% 的任务。即便是表现最好的模型 GPT-5.1 (High),也仅达到了 23.7%。换句话说,尽管 Context 中拥有解决每个任务所需的全部信息,模型在绝大多数任务上都失败了。这表明当前的 SOTA 模型几乎不会从 Context 中学习。
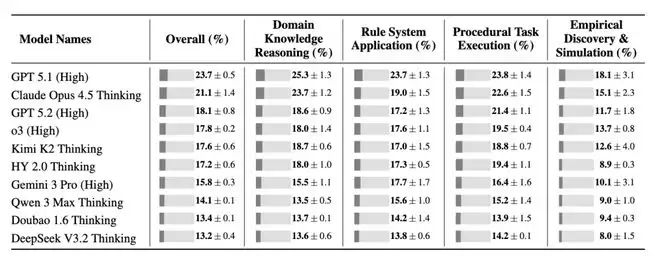
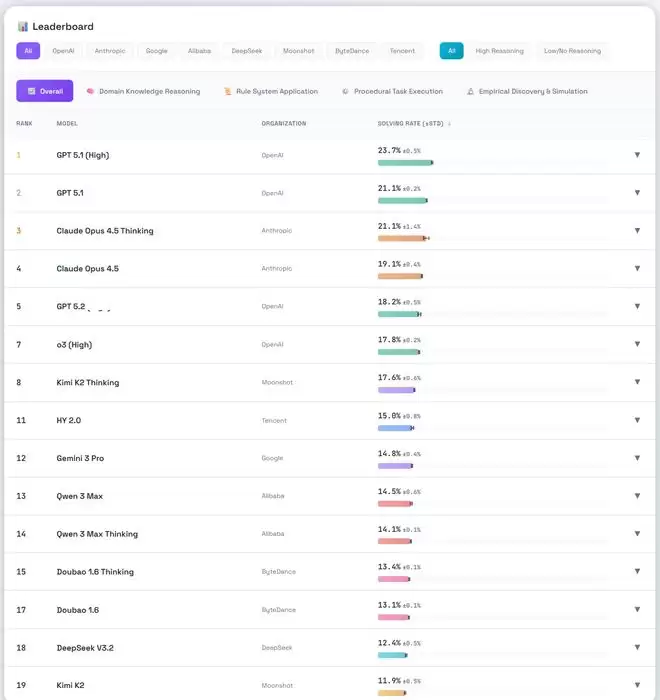
IT之家附项目正式如下:
相关攻略

一个学生忽视了一行代码,结果发现了一件很不对劲的事:在一个多模态医学AI项目中,这行代码原本负责让模型读取图像数据。但因为这次疏忽,模型实际上完全没有看到任何图片。按理说系统应该报错,或者至少拒绝回

雷递网 乐天 3月31日智谱CEO张鹏今日在智谱2025年年报沟通会上表示,智谱曾经历过质疑,经历过挫折,但无数事实反复验证了一个判断——智能上界的提升,是大模型AGI时代唯一的 "第一性 "。张鹏说,

快科技3月31日消息,近日,比利时布鲁塞尔自由大学(VUB)数据分析实验室发布重磅研究成果,证实商用大型语言模型已具备独立生成原创数学证明的能力。OpenAI旗下ChatGPT-5 2(Thinki

这项由谷歌智能范式团队联合芝加哥大学、圣塔菲研究所等多家机构完成的突破性研究发表于2026年3月,研究编号为arXiv:2603 20639v1。有兴趣深入了解的读者可以通过这个编号查询完整论文。这

这项由高通AI研究院领导的突破性研究发表于2026年3月的预印本论文,论文编号为arXiv:2603 08462v1。有兴趣深入了解的读者可以通过该编号查询完整论文。这项研究解决了一个让所有AI研究
热门专题







热门推荐

《无限轮回》新手入门指南:高效开局与核心机制解析 你是否渴望在《无限轮回》中快速成长,成为团队中可靠的伙伴?对于新手而言,正确的开局思路至关重要。切忌盲目拾取未知物品,一个不当操作——例如过早将关键法器“葫芦”交给队友——就可能打乱核心输出的成长节奏,导致团队覆灭。作为团队辅助,你的首要目标并非打出

Fami通最新销量榜出炉:日本实体游戏软件销量数据解读(2026年3月16日-22日) 日本游戏市场每周的风向变幻,总是由那些长青的头部作品与新晋热作共同书写。根据权威媒体《Fami通》最新发布的实体销量估算数据,在2026年3月16日至3月22日这一周,市场格局呈现出清晰的趋势:任天堂Switch

王者荣耀S43赛季射手梯度排行榜单 新赛季的射手格局已基本定型,可以用一句话概括核心趋势:敖隐与蚩妩两位英雄构成双星闪耀的T0阵营,综合强度堪称断层领先。紧随其后的T1梯队中,公孙离、艾琳、孙权、元流之子(射手)等英雄各怀绝技,或凭借极致的灵活拉扯掌控战局,或依赖无解的持续输出主宰团战。而处于T2梯

长生:天机降世怎么玩:从入门到精通的全面攻略 《长生:天机降世》是一款深度策略卡牌手游。其核心玩法在于通过策略性的卡牌组合与角色搭配,在限定回合内,最大化自身伤害输出并在竞技排行榜上取得优势。想要玩好这款游戏,深入理解其底层机制是关键第一步。 《长生:天机降世》新手入门与高阶玩法解析: 一、游戏核心

在本来生活平台下单购物后,及时查询并跟踪物流信息,可以帮助我们准确掌握包裹的预计送达时间,提前做好收货安排。那么,在本来生活应该如何高效地查询快递物流状态呢?下面为您详细介绍几种常用方法。 进行网络购物之后,用户最关心的问题通常是“我的包裹现在运送到哪里了?”实时了解物流进度,不仅能减少等待期间的焦