DeepSeek视觉推理首创因果流,性能超越Gemini再夺第一

新智元报道
编辑:定慧 好困
【新智元导读】DeepSeek开源DeepSeek-OCR2,引入了全新的DeepEncoder V2视觉编码器。该架构打破了传统模型按固定顺序(从左上到右下)扫描图像的限制,转而模仿人类视觉的「因果流(Causal Flow)」逻辑。
DeepSeek又双叒叕更新了!
这次是DeepSeek-OCR模型的重磅升级:DeepSeek-OCR2。

还记得上一代DeepSeek-OCR吗?那个用视觉方式压缩一切的模型。
这一次,DeepSeek更进一步,对视觉编码器下手了,提出了一种全新的DeepEncoder V2架构,实现了视觉编码从「固定扫描」向「语义推理」的范式转变!
DeepSeek-OCR2不仅能像人类一样按逻辑顺序阅读复杂文档,还在多项基准测试中刷新了SOTA。
当然,按照DeepSeek的惯例,Paper、Code、Model全开源!
项目地址:
https://github.com/deepseek-ai/DeepSeek-OCR-2
模型下载:
https://huggingface.co/deepseek-ai/DeepSeek-OCR-2
论文地址:
https://github.com/deepseek-ai/DeepSeek-OCR-2/blob/main/DeepSeek_OCR2_paper.pdf
DeepSeek-OCR2的核心创新在于通过DeepEncoder V2,赋予了模型因果推理能力(Causal Reasoning)。
这就像是给机器装上了「人类的阅读逻辑」,让AI不再只是死板地从左上到右下扫描图像,而是能根据内容语义灵活调整阅读顺序。
DeepSeek-OCR2
视觉因果流
DeepSeek在论文中指出,传统的视觉语言模型(VLM)通常采用光栅扫描(Raster-Scan)顺序处理图像,即固定地从左到右、从上到下。
这种方式强行将2D图像拍扁成1D序列,忽略了图像内部的语义结构。
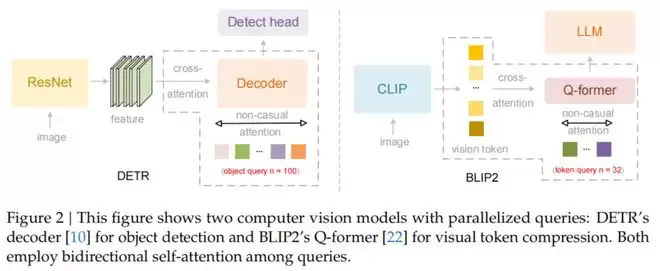
这显然与人类的视觉习惯背道而驰。
人类在看图或阅读文档时,目光是随着逻辑流动的:先看标题,再看正文,遇到表格会按列或按行扫视,遇到分栏会自动跳跃。
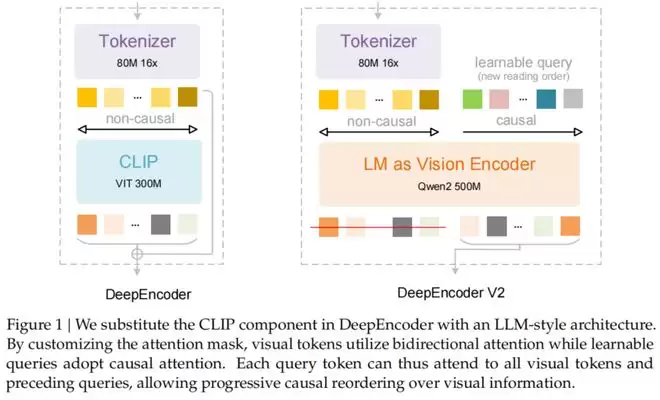
为了解决这个问题,DeepSeek-OCR2引入了DeepEncoder V2。
它最大的特点是用一个轻量级的大语言模型(Qwen2-0.5B)替换了原本的CLIP编码器,并设计了一种独特的「因果流查询」(Causal Flow Query)机制。
DeepEncoder V2架构详解
DeepEncoder V2主要由两部分组成:
1. 视觉分词器(Vision Tokenizer)
沿用了SAM-base(80M参数)加卷积层的设计,将图像转换为视觉Token。
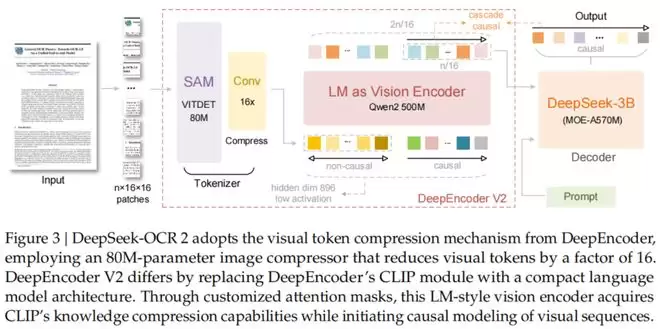
2. 作为视觉编码器的LLM
这里DeepSeek使用了一个Qwen2-0.5B模型。
它不仅处理视觉Token,还引入了一组可学习的「查询Token」(Query Tokens)。

关键的创新点在于注意力掩码(Attention Mask)的设计:
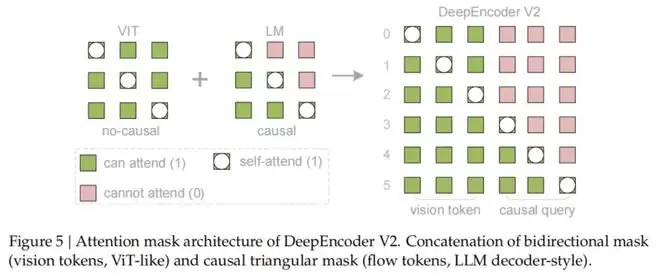
视觉Token之间采用双向注意力(Bidirectional Attention),保持全局感知能力,类似于ViT。
而查询Token则采用因果注意力(Causal Attention),每一个查询Token只能看到它之前的Token。
通过这种设计,DeepEncoder V2实现了两级级联的因果推理:
编码器通过可学习的查询对视觉Token进行语义重排,随后的LLM解码器则在这个有序序列上进行自回归推理。
这意味着,DeepSeek-OCR2在编码阶段就已经把图像里的信息「理顺」了,而不是一股脑地扔给解码器。
Token更少,精度更高
实验数据显示,DeepSeek-OCR2在保持极高压缩率的同时,性能显著提升。
在OmniDocBench v1.5基准测试中,DeepSeek-OCR2在使用最少视觉Token(仅256-1120个)的情况下,综合得分高达91.09%,相比前代提升了3.73%。
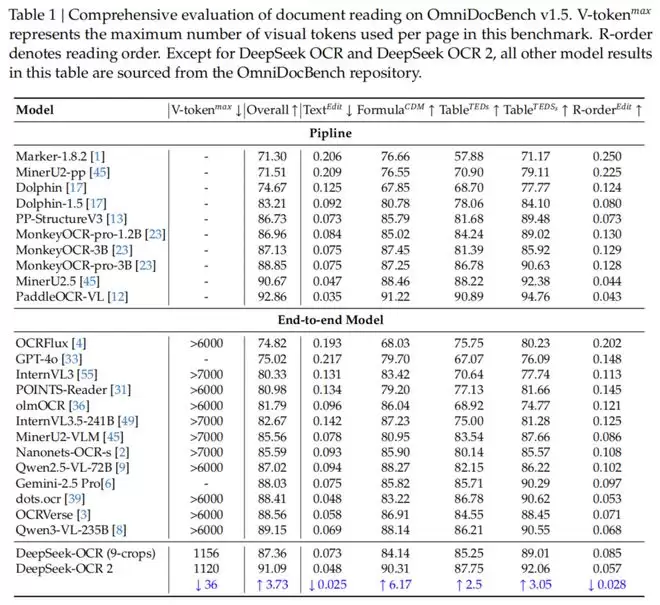
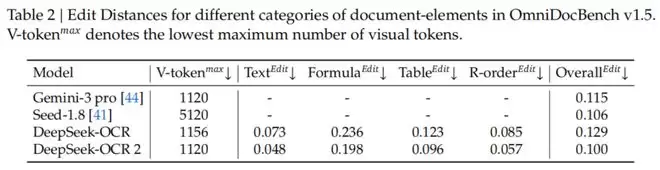
特别值得一提的是,在阅读顺序(R-order)的编辑距离(Edit Distance)指标上,DeepSeek-OCR2从前代的0.085显著降低到了0.057。
这直接证明了新模型在处理复杂版面时,逻辑性更强,更懂「阅读顺序」。
在和Gemini-3 Pro等闭源强模型的对比中,DeepSeek-OCR2也丝毫不落下风。
在均使用约1120个视觉Token的情况下,DeepSeek-OCR2的文档解析编辑距离(0.100)优于Gemini-3 Pro(0.115)。
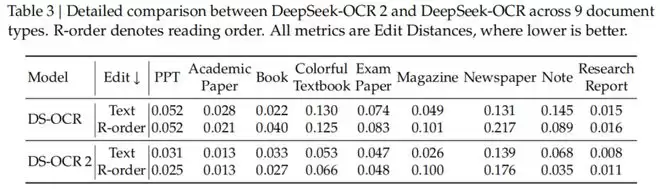
不仅是刷榜,DeepSeek-OCR2在实际生产环境中也非常能打。
DeepSeek披露,在处理在线用户日志图像时,OCR结果的重复率从6.25%降到了4.17%;在PDF数据生产场景中,重复率从3.69%降到了2.88%。

这意味着模型生成的文本更加干净、准确,对于作为LLM训练数据的清洗流水线来说,价值巨大。
迈向真正的多模态统一
DeepSeek在论文最后提到,DeepSeek-OCR2通过DeepEncoder V2验证了「LLM作为视觉编码器」的可行性。
这不仅是一个OCR模型的升级,更是迈向原生多模态(Native Multimodality)的重要一步。
未来,同一个编码器只要配备不同的模态查询嵌入(Query Embeddings),就能处理文本、图片、音频等多种模态的数据,真正实现万物皆可Token,万物皆可因果推理。
DeepSeek表示,虽然目前光学文本识别(OCR)是LLM时代最实用的视觉任务之一,但这只是视觉理解宏大图景的一小部分。
DeepSeek将继续探索,向着更通用的多模态智能进发。
参考资料:
https://huggingface.co/deepseek-ai/DeepSeek-OCR-2

相关攻略

头图由智象未来AI大模型生成智东西作者 王涵编辑 漠影在演唱会、各大晚会的舞台上,机器人伴舞团以整齐划一、精准卡点的舞姿惊艳全场。这种整齐划一不仅是硬件的胜利,更是“训练有素”的结果。具身智

智东西编译 陈佳编辑 程茜智东西4月3日消息,今日谷歌DeepMind开源发布Gemma 4系列模型,根据最新博客,这是谷歌迄今为止最智能的开放模型,专为高级推理和智能体工作流而设计,实现了单位参数

带着 Seedance 2 0 和 ArkClaw 两件新武器,火山引擎开始席卷 MaaS 市场。作者|郑玄两年前,火山引擎说要 All in Token 的时候,很多人觉得这是一句正确但空洞的口号

一个学生忽视了一行代码,结果发现了一件很不对劲的事:在一个多模态医学AI项目中,这行代码原本负责让模型读取图像数据。但因为这次疏忽,模型实际上完全没有看到任何图片。按理说系统应该报错,或者至少拒绝回

智通财经APP获悉,中信证券发布研报称,2026年以来,国产大模型厂商聚焦Agent及代码能力升级,竞相发布新模型。即将发布的DeepSeek下一代新模型有望延续高性价比开源模型路线,在能力上实现更
热门专题







热门推荐

在麒麟操作系统上配置SSH公钥登录,不仅能免去每次输入密码的繁琐,更能显著增强远程连接的安全性。整个过程并不复杂,核心步骤围绕密钥生成、公钥部署和服务端配置展开。本文将详细介绍几种主流方法,涵盖从自动化部署到手动配置,助你轻松完成麒麟系统SSH密钥登录设置。 一、使用ssh-keygen与ssh-c

登录循环闪退应先删 Xauthority和 ICEauthority文件、修复 tmp权限为1777、重置ukui mate dconf配置、清理磁盘空间、重装lightdm并重新配置。 在银河麒麟操作系统中输入密码后,屏幕一闪又回到登录界面,这种“登录循环”问题确实令人困扰。这通常并非硬件故障,而

GUSD是一种与美元1:1锚定的合规稳定币,由Gemini交易所发行并受纽约州金融服务部监管。其核心价值在于为加密世界提供透明、受监管的美元等价物,主要应用于交易、支付和价值存储。投资者需关注其中心化托管风险、监管政策变化及智能合约潜在漏洞,理解其作为传统金融与加密市场桥梁的定位与局限。

在Windows 11系统中,确保系统音频稳定输出到指定设备(如已连接的耳机或已配对的蓝牙音箱),核心在于正确配置默认音频输出设备。您可以通过任务栏快速设置、系统设置应用、控制面板声音对话框、音量混合器下拉菜单或Win+Ctrl+V快捷键这五种主流方案,实现即时切换或永久性配置,彻底解决声音输出错乱

宏胜集团近期发生重要人事与业务调整。总裁办主任叶雅琼、销售总经理吴汀燕、法务部部长周卓盈及生产管理科科长吴潘潘等多位高管已离职,该消息已获接近集团人士证实。与此同时,集团启动了部分非生产业务的外包运作,显示出其正在优化内部结构与运营模式。这一系列变动可能意味着公司正处于战略调整期,旨在聚焦核心业务并