清华新高熵驱动技术:多奖励强化学习效率跃升

新智元报道
编辑:LRST
【新智元导读】面对流模型强化学习中奖励信号稀疏、归因模糊的核心痛点,清华大学团队提出熵感知的E-GRPO框架,通过合并低熵步骤、聚焦高熵探索,在单奖励与多奖励场景下均实现性能突破,相比主流方法HPS指标提升10.8%,ImageReward指标最高提升32.4%,为视觉生成的人类偏好对齐提供了更高效的解决方案。
近年来,扩散模型与流匹配模型等生成式 AI 技术在视觉内容创作领域取得突破性进展,从艺术设计到医疗成像,应用场景不断拓展。而强化学习从人类反馈(RLHF)技术的引入,更是让生成模型能够精准对齐人类偏好,大幅提升内容质量。
然而,当前基于分组相对策略优化(GRPO)的流模型强化学习方法,在多步去噪过程中面临严重的奖励信号稀疏与归因模糊问题,低熵步骤的探索价值有限,却占用大量计算资源,导致模型优化效率低下、偏好对齐效果不佳。
近日,清华大学团队提出熵感知分组相对策略优化(E-GRPO)框架,通过深入分析去噪步骤的熵特性,创新性地将连续低熵步骤合并为高熵有效步骤,同时保留确定性ODE采样的稳定性,成功解决了奖励归因模糊难题,实现了更高效的探索与更精准的偏好对齐。

论文地址:https://arxiv.org/abs/2601.00423v1
代码地址:https://github.com/shengjun-zhang/VisualGRPO
模型地址:https://huggingface.co/studyOverflow/E-GRPO
E-GRPO研究背景
主流GRPO-based方法在流模型训练中,会对所有去噪时间步进行均匀优化,但清华大学团队通过实验发现,不同去噪步骤的探索价值存在显著差异:
高熵步骤具有更大的探索空间,能够生成多样性丰富、奖励差异明显的样本,是模型优化的核心驱动力;
低熵步骤的样本差异极小,奖励信号区分度低,类似给最终图像添加10%随机噪声的效果,不仅难以引导有效优化,还会因累积随机性导致奖励归因模糊 —— 某一步的有效探索可能被后续轨迹偏差「惩罚」,使模型优化方向跑偏。
实验数据显示,仅优化前8个高熵步骤的模型性能,显著优于优化全部16个步骤的模型,证实了低熵步骤的「无效性」。如何充分利用高熵步骤的探索价值,同时避免低熵步骤带来的干扰,成为提升流模型强化学习效率的关键。
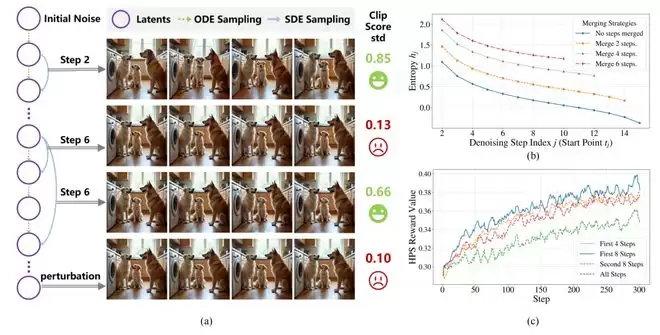
熵对采样步骤的影响
E-GRPO框架通过熵驱动的步骤合并策略与多步分组归一化优势估计两大核心创新。
1. 熵驱动自适应步骤合并:低熵「打包」,高熵聚焦
团队设计了自适应熵阈值,将所有去噪步骤划分为高熵组与低熵组。对于连续的低熵步骤,通过合并形成单一高熵有效步骤,在保留总扩散效果的前提下,将多个低熵 SDE 步骤转化为一个高熵 SDE 步骤,其余步骤则采用确定性 ODE 采样。
这种合并策略不仅大幅减少了无效计算,还通过扩大单一步骤的探索范围提升了熵值,同时避免了多步 SDE 采样带来的累积随机性,让奖励信号能够精准归因到有价值的探索步骤上。
2. 多步分组归一化优势:奖励信号更密集、更可靠
针对合并后的高熵步骤,E-GRPO引入多步分组归一化优势估计方法。在每个合并步骤对应的样本组内,直接计算组内相对优势,确保奖励信号能够一致归因到合并步骤,避免了跨步骤的奖励混淆。这种设计让模型获得了更密集、更可靠的反馈信号,能够快速锁定优化方向,提升训练效率与稳定性。
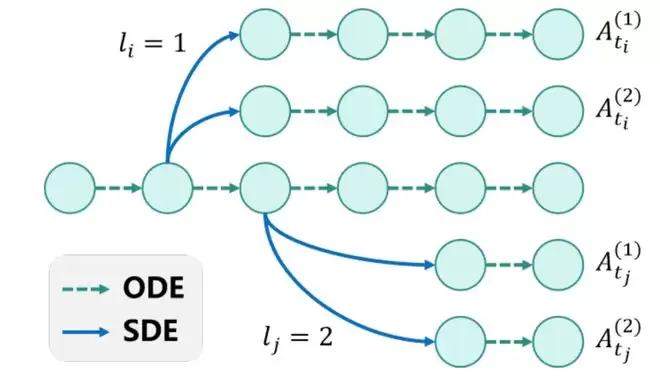
E-GRPO采样策略
性能亮点
在HPD数据集上,以FLUX.1-dev为骨干模型,在单奖励和多奖励两种设置下,对E-GRPO进行了全面评估,结果显示其性能超越现有主流方法。
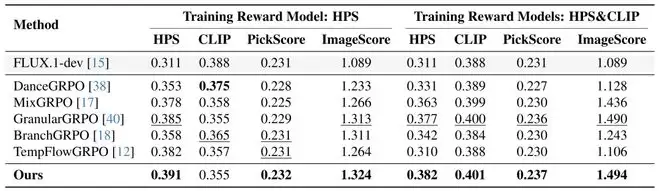
E-GRPO数值结果测评
单奖励设置下,E-GRPO的HPS指标达到0.391,相比DanceGRPO提升10.8%,ImageScore指标达到1.324,稳居同类方法第一;多奖励设置下(有效避免奖励作弊),E-GRPO不仅保持HPS指标领先,还在跨域指标上实现突破:ImageReward提升32.4%,PickScore提升4.4%,展现出更强的泛化能力。
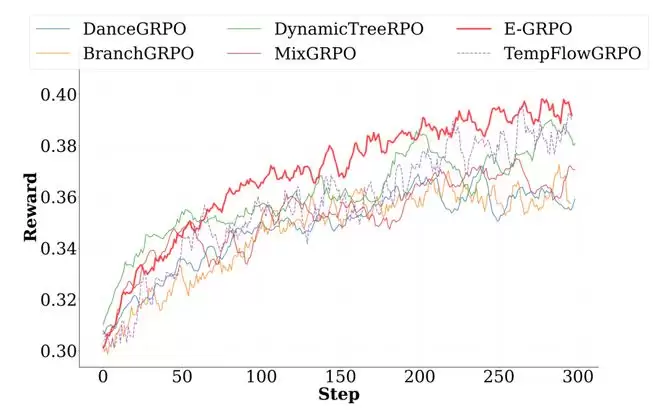
训练奖励曲线
E-GRPO的训练奖励曲线呈现更快的早期增长与更平滑的收敛趋势,相比基线方法能够更快达到稳定性能,同时因减少了无效步骤的计算,降低了训练成本。

可视化结果
在定性对比中,E-GRPO生成的内容更精准贴合文本提示,兼具语义一致性与细节丰富度:
对于「装扮成水手的木瓜」提示,E-GRPO成功将木瓜结构与人形服饰自然融合,而基线方法或生成「手持木瓜的人」,或出现视觉逻辑混乱;对于「带眼睛和微笑的勺子」提示,E-GRPO在保留勺子金属质感的同时,生成了表情生动、视觉协调的拟人化效果,其他方法则存在面部融合不自然或材质失真问题。
总结与展望
E-GRPO通过深入挖掘去噪步骤的熵特性,创新性地提出步骤合并与分组优势估计方法,成功解决了流模型强化学习中奖励稀疏与归因模糊的核心痛点,为视觉生成模型的人类偏好对齐提供了更高效、更稳定的解决方案。
未来研究将聚焦于更鲁棒的奖励模型设计。当前奖励模型仍存在「奖励作弊」风险,模型可能通过奖励函数漏洞获取高分,而非真正满足人类偏好。开发能够精准捕捉审美、语义一致性、上下文适配性等复杂人类偏好的奖励模型,将是视觉生成强化学习的重要发展方向。
E-GRPO的提出,不仅为流模型的优化提供了新范式,也为其他生成模型的强化学习训练提供了重要启发:基于熵等物理特性引导探索,或许是提升AI模型效率的关键路径。
参考资料:
https://arxiv.org/abs/2601.00423v1

热门专题







热门推荐

在追求极致效率的现代软件开发中,一款名为Cursor的AI代码编辑器正引领着开发范式的变革。它被定义为“面向未来的IDE”,其核心理念清晰而有力:将人工智能深度无缝地集成到编码工作流的每一个步骤,为开发者创造一种前所未有的“AI结对编程”体验。 Cursor sh应用场景 那么,这款AI驱动的编辑器

在众多AI图像生成工具中,WHEE凭借其精准的产品定位与持续的功能迭代,正成为越来越多设计师和内容创作者的首选工具。它专注于打造高品质的AI视觉素材生成器,核心使命就是帮助用户快速、高效地获得可直接使用的优质图片素材。 那么,这款AI绘图工具究竟有哪些核心优势?下面我们从其关键特性与功能设计进行深入

在AI绘画工具不断涌现的当下,一款名为NightCafe Creator的应用以其全面的AI艺术生成能力脱颖而出。它不仅是一个简单的图片处理工具,更是一个融合了多种前沿人工智能技术的创意平台,帮助用户轻松实现从构思到成品的艺术创作。 NightCafe Creator是什么? NightCafe C

近期加密货币市场受到宏观经济不确定性及流动性紧缩影响,比特币(BTC)、以太坊(ETH)以及多种山寨币出现明显下行走势,市场情绪趋于谨慎。 比特币近期走势分析 比特币的价格近期表现如何?简单来说,它跌破了几个市场公认的关键支撑位,而且伴随交易量的放大。这种放量下跌的信号,往往意味着多空分歧加剧。无论

蔡司宣布将于6月2日发布一款新镜头,并称其为镜头技术的重大突破,标志着全新纪元的开启。官方仅公布了产品剪影,但措辞暗示其可能带来根本性的技术升级,例如全新光学结构、先进镀膜或对焦系统改进。具体细节需待发布日揭晓。