OpenAI Codex架构解析:8亿用户实战反制Claude

新智元报道
编辑:定慧 元宇
【新智元导读】AI编程霸主之争升级!Claude Code刚刷屏,OpenAI连甩两张王:不仅首度揭秘Codex背后的大脑「Agent Loop」,还自曝惊人基建:仅用1个PostgreSQL主库,竟抗住了全球8亿用户洪峰!
最近,Anthropic的Claude Code引爆了AI编程圈!
那个能在终端里自己读代码、改代码、跑测试的AI助手,让不少开发者直呼「这才是未来」。
一时间,社交媒体上全是「Claude Code吊打Cursor、Codex、Antigravity」之类的评论。
就在大家以为OpenAI还在憋GPT-5.3大招的时候,今天其官博和奥特曼突然在X平台甩出了两张王炸:
1.Agent Loop架构揭秘:首次公开Codex的「大脑」是怎么运转的
2.PostgreSQL极限架构:1个主库扛起8亿用户的疯狂操作
这一波组合拳打得太漂亮了。
今天咱们就来拆解一下,OpenAI到底憋了什么大招。
Agent Loop
Codex的「大脑 」 是怎么运转的
什么是Agent Loop?
如果你用过Codex CLI、Claude Code等等CLI终端工具,你可能会好奇:
这玩意儿到底是怎么知道我想干啥的?怎么就能自己读文件、写代码、跑命令?
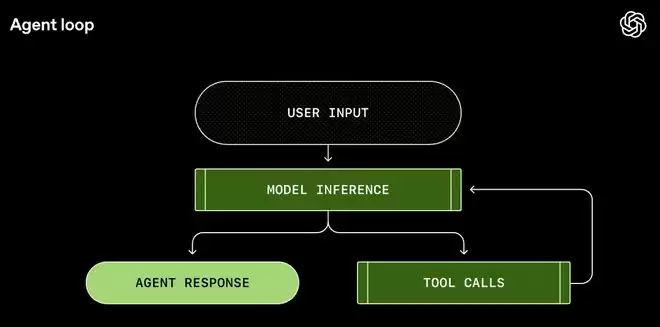
答案就藏在一个叫Agent Loop(智能体循环)的东西里。

简单来说,Agent Loop就像一个「总指挥」,它负责把「用户意图」「模型大脑」和「执行工具」串成一个完美的闭环。
这不是普通的「你问我答」,而是一个包含了「观察-思考-行动-反馈」的能干活的系统。
下面,把这个黑盒拆开,看看一个真正的AI Agent是如何跑起来的。
一个完整的Agent Loop是怎么跑起来的
用一个具体的例子来说明。
假设在终端里输入:给项目的README.md加一个架构图。
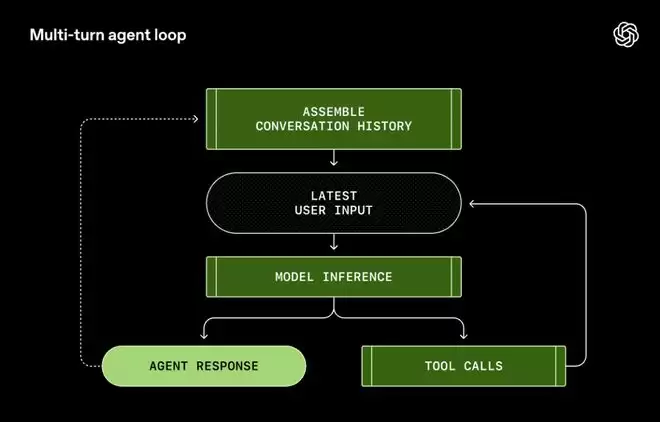
第一步:构建Prompt
这好比给大脑发工单。
Codex不会直接把你的话丢给模型,它会先构建一个精心设计的「Prompt」:
我是谁:(System):告诉模型它是谁、能干什么
我有什么工具(Tools):有哪些工具可以调用(比如shell命令、文件操作)
环境上下文(Context):当前在哪个目录、用的什么shell
用户指令:给README.md加一个架构图。
这就像给模型发一封详细的工作邮件,而不是只发一句「帮我干活」。
第二步:模型推理(Inference)
这一步,大脑开始转动。
Codex把这个Prompt发给ResponsesAPI,模型开始思考:
「用户想加架构图,我得先看看现在的README是什么样的……」
然后模型做出决定:调用shell工具,执行catREADME.md。
第三步:工具调用(ToolCall)
Codex收到模型的请求,在本地执行命令,把README.md的内容读出来。
这就像手脚开始动起来。
第四步:结果反馈
这一步,终端把README.md的内容吐了出来。
这时候流程没有结束。Codex把命令的输出追加到Prompt里,再发给模型。
第五步:循环
模型看到了README的内容,再次进行推理:
可能是生成一个Mermaid图,可能是直接写一段ASCII图形……然后再调用工具写入文件。
这个循环一直持续,直到模型认为任务完成了,输出一条「我搞定了」的消息。
它不是在回答问题,它是在解决问题。
为什么这很重要?
也许你可能会说:「这不就是多调了几次API吗?」
但绝非这么简单。
传统的LLM应用是「一问一答」式的:你问,它答,完事儿。
但Agent Loop让AI变成了一个能独立干活的员工。
它会自己规划路径(Chain of Thought)。
它会自己检查错误(Self-Correction)。
它会自己验证结果(Feedback Loop)。
这才是真正的「AI Agent」。
而Agent Loop,就是那个可以让AI实现从「陪伴聊天」迈向「独立干活」飞跃的桥梁。
性能优化
两个关键技术
OpenAI在文章里分享了两个硬核优化,解决了Agent开发的两大痛点:
痛点一:成本爆炸
Agent Loop每跑一圈,都要把之前的对话历史(包括那些冗长的报错信息、文件内容)重新发给模型。
对话越长,成本越高。如果不优化,成本是平方级增长的。
解决方案:PromptCaching(提示词缓存)
OpenAI采用了一种类似于「前缀匹配」的缓存策略。
简单来说,只要你发给模型的前半部分内容(System指令、工具定义、历史对话)没变,服务器就不需要重新计算,直接调取缓存。

这一招,直接让长对话的成本从平方级增长降到了线性级。
但这里有个坑:任何改变Prompt前缀的操作都会导致缓存失效。比如:
中途换模型
修改权限配置
改变MCP工具列表
OpenAI团队甚至在文章里承认,他们早期的MCP工具集成有bug:工具列表的顺序不稳定,导致缓存频繁失效。
痛点二:上下文窗口有限
再大的模型,上下文窗口也是有限的。
如果Agent读了一个巨大的日志文件,上下文瞬间就满了,前面的记忆就会被挤掉。
对于程序员来说,这就意味着:「你把前面我定义的函数给忘了?!」
这不仅是智障,更是灾难。
解决方案:Compaction(对话压缩)
当Token数超过阈值,Codex不会简单地「删除旧消息」,而是会调用一个特殊的/responses/compact接口,把对话历史「压缩」成一个更短的摘要。

普通的总结(Summary)只是把长文本变成短文本,会丢失大量细节。
OpenAI的Compaction返回的是一段encrypted_content(加密内容),保留了模型对原始对话的「隐性理解」。
这就像把一本厚书压缩成一个「记忆卡片」,模型读了卡片就能回忆起整本书的内容。
这让Agent在处理超长任务时,依然能保持「智商」在线。
这一次,OpenAI硬核揭秘Codex CLI背后的「大脑」「Agent Loop」,释放出一个信号:AI真的是要把活儿给干了。
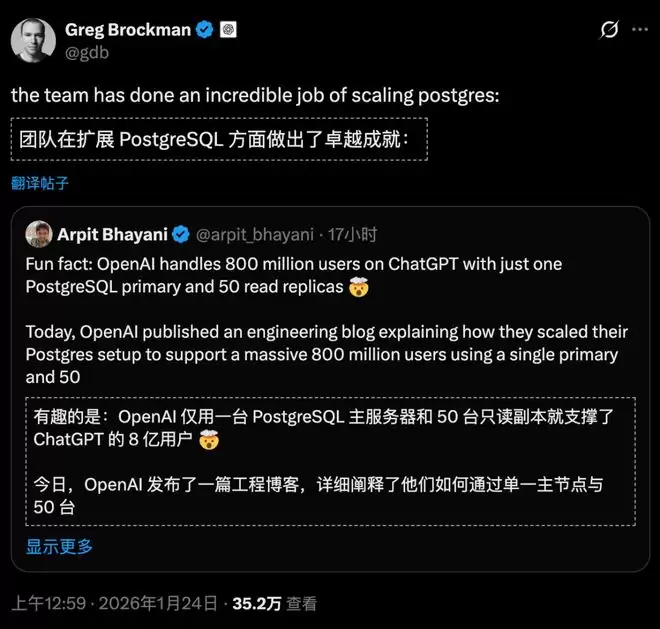
1个主库扛8亿用户
PostgreSQL的极限操作
在大家都在聊AI模型有多牛的时候,OpenAI悄悄曝光了一个更劲爆的消息:
支撑全球8亿ChatGPT用户、每秒处理数百万次查询的,竟然只是一个单一主节点的PostgreSQL数据库!
它只用1个PostgreSQL主节点+50个只读副本就做到了。

8亿用户,这简直是在开玩笑!有网友惊叹。
在分布式架构盛行的今天,大家动不动就是「微服务」「分片」「NoSQL」。
能用巨型分布式集群解决的问题,绝不用单机。
结果OpenAI告诉你:我们就用个PostgreSQL,照样扛。

他们是怎么做到的?
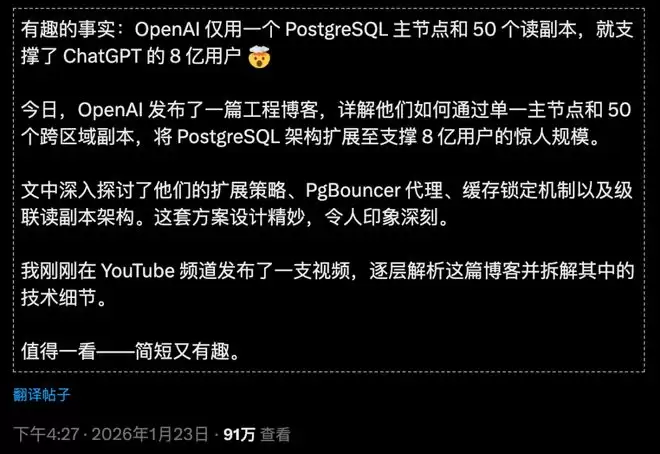
根据OpenAI工程师披露的信息,关键技术包括:
1. PgBouncer连接池代理 :大幅减少数据库连接开销
2. 缓存锁定机制 :避免缓存穿透导致的写入压力
3. 跨地域级联复制 :读请求分散到全球各地的副本
这套架构的核心思想是:读写分离,极致优化读路径。
毕竟对于ChatGPT这种应用,读请求远远多于写请求。用户发条消息,系统可能需要读几十次数据(用户信息、对话历史、配置信息……),但写入只有一次。
根据OpenAI最新博客披露,关键技术包括:
1.连接池代理(PgBouncer)
通过连接池管理,把平均连接建立时间从50ms降到了5ms。
别小看这45ms,在每秒百万级查询的场景下,这是巨大的性能提升。
2.缓存锁定/租约机制(CacheLocking/Leasing)
这是一个非常聪明的设计。
当缓存未命中时,只允许一个请求去数据库查询并回填缓存,其他请求等待。
这避免了「缓存雪崩」——大量请求同时涌向数据库的灾难场景。
3.查询优化与负载隔离
团队发现并修复了一个涉及12张表连接的复杂查询。
他们把复杂逻辑移到应用层处理,避免在数据库里做OLTP反模式操作。
同时,请求被分为高优先级和低优先级,分别由专用实例处理,防止「吵闹邻居」效应导致的性能下降。
4.高可用与故障转移
主库运行在高可用(HA)模式,配有热备节点。
读流量全部分流到副本,即使主库宕机,服务仍能保持只读可用,降低故障影响级别。
天花板终究会到来
不过,OpenAI也坦言,这套架构已经碰到了物理极限。问题出在两个地方:
PostgreSQL的MVCC限制
PostgreSQL的多版本并发控制(MVCC)机制会导致写放大(更新一行需要复制整行)和读放大(扫描时需要跳过死元组)。对于写密集型负载,这是个硬伤。
WAL复制压力
随着副本数量增加,主库需要向所有副本推送预写日志(WAL)。副本越多,主库的网络压力越大,副本延迟也越高。
为了突破这些限制,OpenAI正在做两件事:
1. 把可分片的、高写入负载迁移到AzureCosmosDB等分布式系统;
2. 测试级联复制:让中间副本向下游副本转发WAL,目标是支持超过100个副本。
这个案例完美诠释了一个架构哲学:如无必要,勿增实体。
不要一上来就搞分布式:先用简单的方案撑住,撑不住了再说。
很多公司的问题是:还没到需要分布式的阶段,就已经把架构搞得无比复杂了。结果既没有分布式的好处,还背上了分布式的复杂度。
OpenAI用实践证明:一个优化到极致的单机架构,能走得比你想象的更远。

Codex VS Claude Code的争霸赛
Claude Code的杀手锏是什么?是端到端的开发体验。
它不是一个简单的代码补全工具,而是一个能在终端里独立干活的Agent。
它能读代码、改代码、跑测试、处理Git、甚至自己修Bug。现在甚至还能写文档,做PPT。
这直接威胁到了Codex CLI的地位。
OpenAI这波更新,其实是在说三件事:
第一,我的Agent架构更成熟。
Agent Loop的公开,展示了OpenAI在Agent架构上的深厚积累。这不是一个临时拼凑的产品,而是经过精心设计的系统。
Prompt Caching、Compaction、MCP工具集成……这些都是实打实的工程能力。
第二,我的基础设施更强。
PostgreSQL的案例,展示的是OpenAI的后端能力。8亿用户的规模,不是随便一个创业公司能玩转的。
这也是在暗示:我们的「护城河」不只是模型,还有整个工程体系。
第三,我的模型在变得更强大。
网络安全评级的公开,一方面是在做「预期管理」,告诉大家模型有风险,我们在负责任地处理。
另一方面,这也是在秀肌肉:我们的模型已经强大到需要专门评估网络安全风险了。
这场AI编程工具的竞争才刚刚开始。
Claude Code逼迫OpenAI加快了Codex的迭代速度。OpenAI的回应,又会倒逼Anthropic继续创新。
最终受益的,是我们这些开发者。
参考资料:
https://openai.com/index/unrolling-the-codex-agent-loop/
https://x.com/gdb/status/2014744842941956606

相关攻略

AI智能体规模化应用面临架构瓶颈,用户多设备体验割裂。研究指出,分布式智能与系统级编排是破局关键,能大幅降低云端成本并提升响应与隐私安全。智能手机将演变为个人AI生态核心,行业需推动跨设备协同与边缘计算整合,实现以用户为中心的智能服务。

在人工智能与复杂系统研究的前沿,基于多智能体系统的分布式优化正成为核心技术焦点。它不仅引领着学术探索的方向,更是破解未来大规模协同与决策难题的关键。本文将深入解析其原理、方法与未来趋势。 一、研究背景与核心价值 我们已全面进入万物互联的时代。从工业物联网到智慧城市管理,系统的规模与复杂性呈指数级增长

在分布式智能体系统的设计与实践中,实现多个智能体(Agent)之间的高效通信与协同协作,是保障系统整体性能与可靠性的关键技术。这好比一支高度协同的团队,若成员间缺乏顺畅的信息交换与任务配合,即便个体能力再强,也难以达成整体目标。那么,这些分布在网络各处的智能体,究竟通过哪些机制与策略来完成有效的“对

分布式能源并网审批因申请激增而周期延长,核心瓶颈在于人工处理现场采集数据耗时严重。当前焦点转向利用实景捕获与计算机视觉技术,自动从图像生成工程数据,以压缩准备时间。电力公司可通过优化流程、引入自动化工具提升效率,从而加速并网进程。

在分布式系统中,多个智能体(Agent)如何协同完成共同目标,是提升系统效率的关键课题。这就像一支无需指挥的交响乐团,每个成员自主决策却又和谐统一。实现这种高效协作,依赖于一系列精心设计的核心运行机制。 分布式决策:局部感知与全局优化 每个Agent都具备独立的决策能力。它们基于自身感知的局部状态与
热门专题







热门推荐

在追求极致效率的现代软件开发中,一款名为Cursor的AI代码编辑器正引领着开发范式的变革。它被定义为“面向未来的IDE”,其核心理念清晰而有力:将人工智能深度无缝地集成到编码工作流的每一个步骤,为开发者创造一种前所未有的“AI结对编程”体验。 Cursor sh应用场景 那么,这款AI驱动的编辑器

在众多AI图像生成工具中,WHEE凭借其精准的产品定位与持续的功能迭代,正成为越来越多设计师和内容创作者的首选工具。它专注于打造高品质的AI视觉素材生成器,核心使命就是帮助用户快速、高效地获得可直接使用的优质图片素材。 那么,这款AI绘图工具究竟有哪些核心优势?下面我们从其关键特性与功能设计进行深入

在AI绘画工具不断涌现的当下,一款名为NightCafe Creator的应用以其全面的AI艺术生成能力脱颖而出。它不仅是一个简单的图片处理工具,更是一个融合了多种前沿人工智能技术的创意平台,帮助用户轻松实现从构思到成品的艺术创作。 NightCafe Creator是什么? NightCafe C

近期加密货币市场受到宏观经济不确定性及流动性紧缩影响,比特币(BTC)、以太坊(ETH)以及多种山寨币出现明显下行走势,市场情绪趋于谨慎。 比特币近期走势分析 比特币的价格近期表现如何?简单来说,它跌破了几个市场公认的关键支撑位,而且伴随交易量的放大。这种放量下跌的信号,往往意味着多空分歧加剧。无论

蔡司宣布将于6月2日发布一款新镜头,并称其为镜头技术的重大突破,标志着全新纪元的开启。官方仅公布了产品剪影,但措辞暗示其可能带来根本性的技术升级,例如全新光学结构、先进镀膜或对焦系统改进。具体细节需待发布日揭晓。