微软研究院近日发布了一款专为机器人领域设计的全新AI模型——Rho-alpha,并宣布将率先通过研究型早期访问计划向外部研究人员开放。
这是微软首次基于Phi系列视觉-语言模型,专门为机器人应用场景深度定制开发的AI系统。从技术路径来看,Rho-alpha被明确纳入微软“物理AI”整体战略框架之中。与主要在虚拟环境中运行的大语言模型不同,该方向聚焦于构建能与真实物理世界实时、可靠交互的智能体。
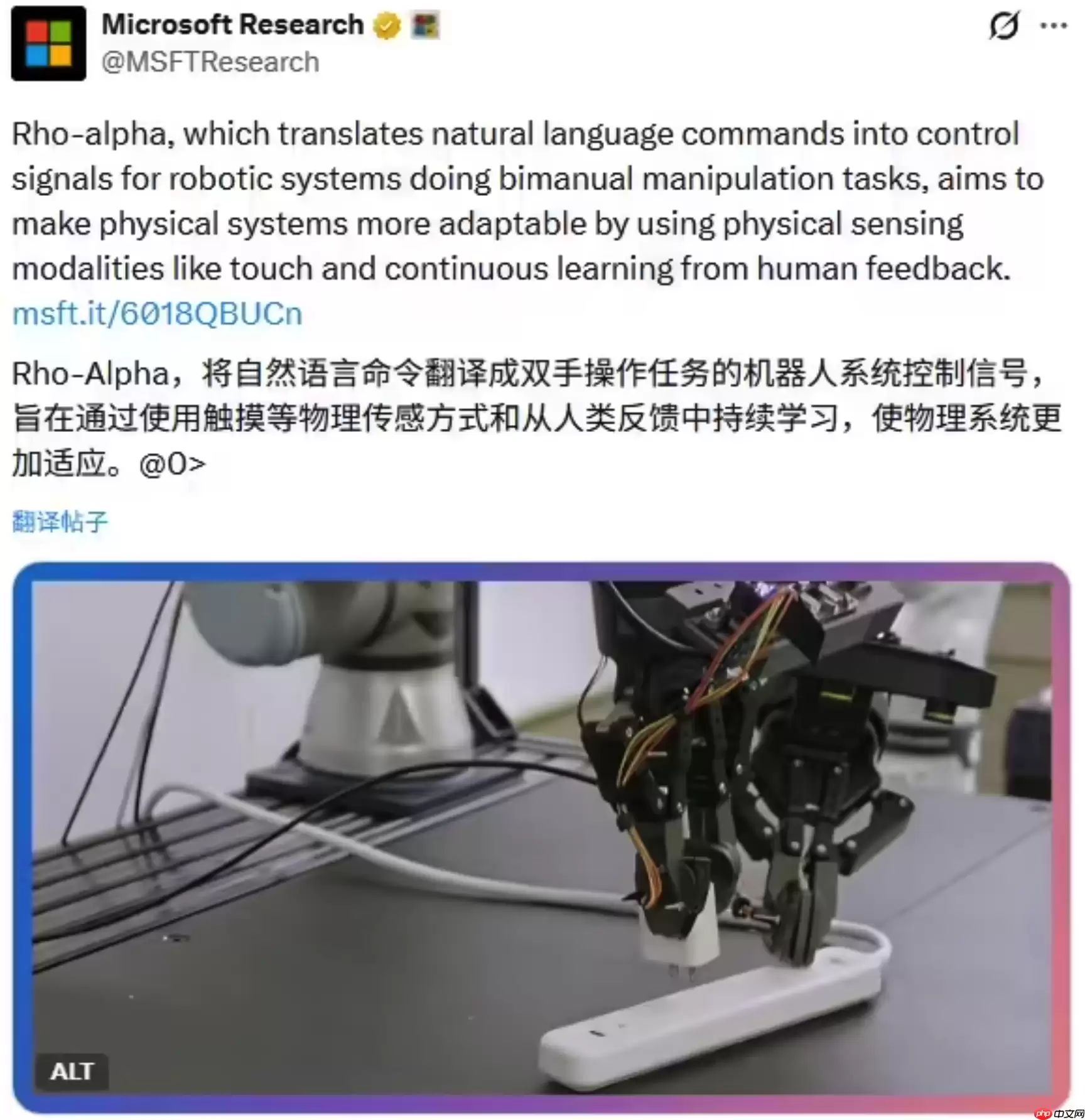
Rho-alpha的关键突破在于,它可以直接将自然语言指令解析并映射为底层机器人控制信号,从而驱动机器人执行高难度的双手协同任务,彻底摆脱传统工业机器人对硬编码脚本和固定流程的依赖。目前,该模型已在双臂操作平台及类人机器人硬件上开展多轮验证与性能评估。

Rho-alpha有望打破机器人长期受限于高度结构化、强约束环境的瓶颈,实现从人类口语化指令到精准物理动作的端到端映射,支撑复杂双手协作任务的自主完成,无需预设程序或人工编排流程。
值得一提的是,该模型展现出较强的在线适应能力:可在任务执行过程中依据环境变化动态优化行为策略;同时支持人类操作者借助简易可视化界面进行实时干预与修正,相关反馈将被自动整合进后续决策与学习循环中。针对机器人领域真实标注数据严重缺乏的挑战,Rho-alpha采用融合真实示范数据、高保真仿真任务以及海量视觉问答样本的混合训练范式,其中大量合成训练数据依托Azure云平台构建的仿真流水线高效生成。

目前,Rho-alpha正同步部署于双臂机器人与类人机器人两大硬件平台进行实机测试。其架构不仅融合了视觉理解与语言处理能力,还首次集成了触觉感知模块,使机器人能够基于接触反馈即时调整抓取力度、姿态与运动轨迹;后续迭代版本将进一步扩展力觉、滑觉等多模态传感融合能力。




