马斯克推出AI超算Dojo+3:性能飙升50倍,成本仅1/10

免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
新智元报道
编辑:好困 桃子
【新智元导读】刚刚,马斯克向英伟达宣战!AI芯片9个月一更,Dojo 3涅槃重生,强攻英伟达5万亿帝国。
马斯克重磅官宣:AI5芯片步入正轨,Dojo 3项目正式重启!
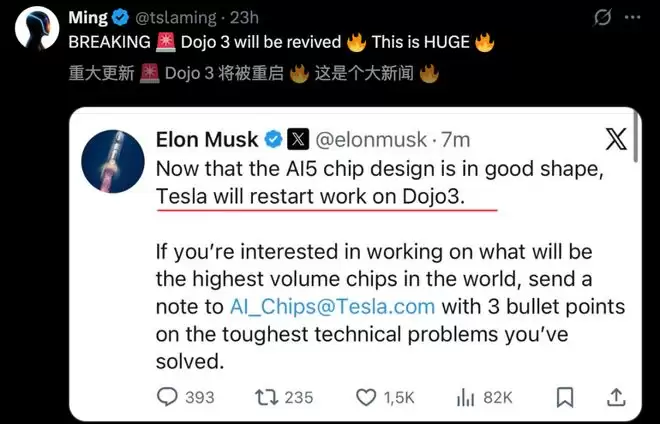
对于特斯拉而言,AI5这颗芯片不仅仅是一次硬件升级,它直接「关系生死」。
这种紧迫感体现在投入的力度上——
不仅两个主力团队全押注在AI5上,就连马斯克本人也亲自下场,连续数月每周六与团队一同攻坚。
最终,AI5芯片性能极具杀伤力:
性能对标:单颗SoC直接对标英伟达Hopper,若是双芯组合相当于Blackwell;
成本优势: 成本不到Blackwell十分之一;
能效碾压: 能效比高出Blackwell约3倍。
就在几天前,马斯克宣布了全球首个1GW超算Colossus 2正式上线。
狂堆55万块GPU,清一色采用英伟达GB200和GB300。

未来,Dojo 3和AI5的成功,或将成为特斯拉摆脱GPU依赖的「大杀器」,彻底在AI领域站稳脚跟。
向英伟达AMD宣战
特斯拉AI芯片9个月一更
在去年的特斯拉股东大会上,马斯克在台上,首次揭秘了自研芯片的神秘面纱。
AI系列芯片本质上不是「通用芯片」,是专为自家AI软件栈深度优化的芯片。
正是这种专用性,赋予了特斯拉挑战物理定律的底气。
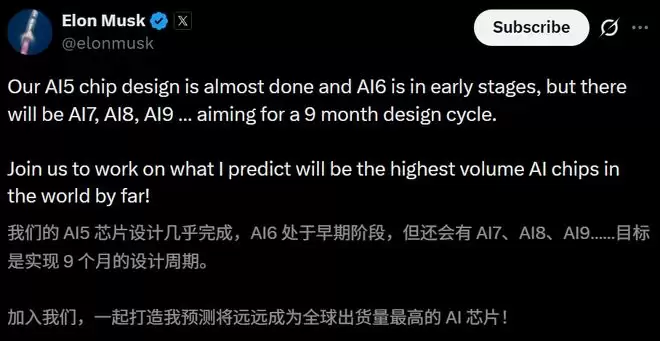
为了追赶AMD、英伟达,马斯克更是立下军令状:将芯片迭代节奏,拉升至约每9个月一个设计周期。
为何能做到如此神速的迭代?最关键的是,团队走的专用路线。
英伟达和AMD都需要做一个「万能」的方案,把各种需求都考虑进去,并维持一年一更的节奏。
目前,AI5芯片设计快搞定了,AI6还处于早期阶段,后续的AI7、AI8、AI9.......蓝图也已铺开。
甚至,马斯克还预言,这将在很大程度上成为世界上出货量最大的AI芯片!
AI5性能狂飙50倍
三星和台积电,是AI5的主要代工厂。他们将生产版本不同AI5,前者2nm,后者采用的是3nm工艺。
相较于上一代AI4,关于AI5更多性能表现,主要有以下几点:
总性能提升50倍,内存多9倍,原始算力提升10倍,加固的块量化与Softmax提升5倍。

它是由特斯拉软硬件团队协同设计,面向最优推理,摒弃了GPU、图像信号处理器(ISP)等传统组件。
AI5每瓦效率,要比英伟达Blackwell芯片高2-3倍,成本约为其10%。
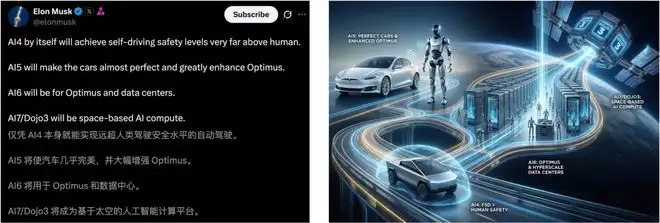
在马斯克的战略版图中,每一代AI芯片,都有独特的「使命」——
AI4:就能让自动驾驶的安全性远超人类;
AI5:让汽车性能趋近完美,同时大幅增强Optimus的能力;
AI6:专攻Optimus进化和数据中心算力;
AI7/Dojo3:目标星辰大海,成为部署在太空的算力基座。
杀死Dojo 2,重启Dojo 3
提及特斯拉AI芯片,Dojo项目,外界曾一度认为已陷入停滞。
毕竟,上一代芯片AI4真正上车交付,至今已过去三年了。2024年初,特斯拉开始交付搭载HW4.0硬件的Model S/X,这是AI4的首次亮相。
短短一年时间,AI4不仅成为汽车的大脑,还被用在了超算的建设中。
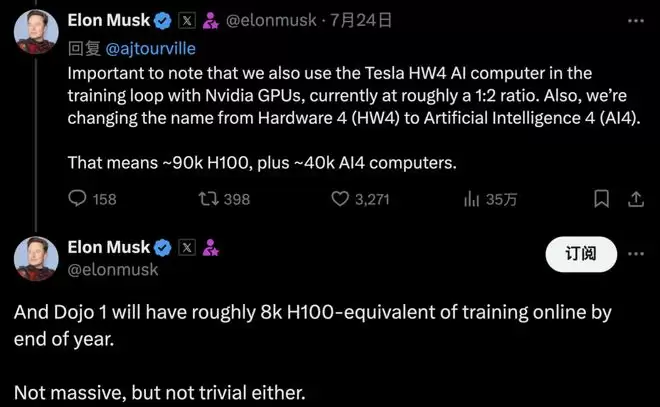
马斯克曾透露,自家AI训练系统中,不仅使用了英伟达GPU,还使用了AI4,比例大约是1:2。
这意味着,大约有9万个H100,加上大约4万个AI4计算机。
相比之下,2024年首次官宣的Dojo超算,更是命运多舛。六年过去了,依旧停留在Dojo 1上迟迟未取得进展。
它基于特斯拉自研D1芯片构建,于2024年7月开始投产,随后在Palo Alto正式部署。

Dojo 1超算
从Dojo诞生之日起,它便专注于解决带宽瓶颈(7nm),最终为了摆脱英伟达的依赖。
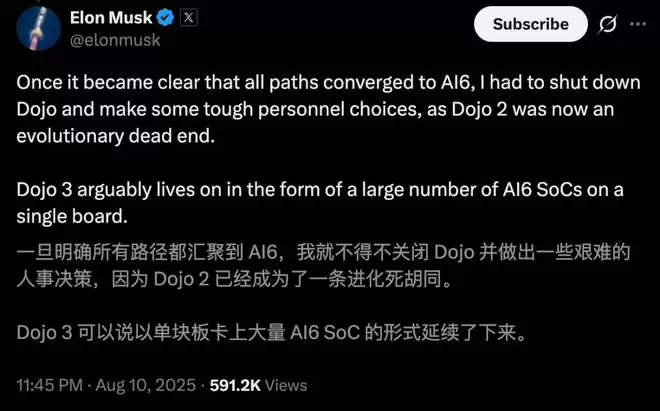
然而Dojo 1之后,在很长一段时间里,Dojo 2都处于「只闻其身」的状态,最终被证实为一条「死路」。
原本传闻中,Dojo 2采用台积电5nm制程,性能将得到大幅提升。
谁曾想,去年8月,马斯克一条帖子,直接给Dojo 2判了「死刑」。
死因何在?
根本原因在于,「双轨制」的内耗:车端用「推理芯片」(AI4/HW4.0);云端用训练芯片(D1)。
特斯拉要维护两套完全不同的芯片架构,直接分散了顶尖人才的精力。
如今,这一战略内部已被重新整合。也就是,马斯克刚刚确认重启的新一代Dojo 3。
Dojo 3将不再使用独立的D系芯片架构,直接使用下一代车载推理芯片AI5,以及后续AI芯片去搭建计算集群。

统一架构下的极限压榨
然而,统一架构带来了一个棘手的新问题:节奏冲突。
马斯克想要9个月一更,但AI5首先是一颗车载芯片。
汽车工业对「冗余设计」和「安全认证」有着近乎苛刻的执念。
车载芯片必须满足ISO 26262等一系列严苛的功能安全标准。相比之下,跑在恒温机房里的数据中心芯片,其工程验证复杂度要低不少。

既然硬件迭代被「车规级安全」和「物理规律」锁死,特斯拉如何实现性能飞跃?
答案是:基于平台的增量演进。
在AI6、AI7乃至AI9的迭代中,特斯拉将复用核心基座(指令集、内存架构、安全框架),仅针对算力扩展和工艺节点迁移(Node Shrink)进行微调。
但这还不够。
既然硬件不能像英伟达那样暴力堆料,那就从数学底层改写规则。
特斯拉的「数学作弊码」
最新的专利US20260017019A1揭示了特斯拉的终极武器:混合精度桥接器(Mixed-Precision Bridge)。

在AI世界里,存在一个永恒的矛盾。
要智能(高精度):Transformer模型依赖32位浮点数(FP32)来处理复杂的三角函数,以确保「旋转位置编码(RoPE)」的准确性(比如记住30秒前的路标)。
要省电(低精度):车载芯片和机器人无法承受FP32的功耗。通常使用的8位整数(INT8)虽然省电,但会因精度丢失导致AI「视力模糊」。
特斯拉的解法是:只在计算的一瞬间保持精确。
1. 对数转换与预计算
工程师设计了「混合精度桥接器」,将关键位置数据转换为对数形式。对数极小的动态范围使其能完美塞进廉价的8位硬件通道。同时,系统利用预先存好的「查找表(LUT)」,省去了现场计算的算力消耗。
2. 泰勒级数与霍纳法则
当这些8位数据到达计算核心(MAC)后,芯片利用经典的泰勒级数展开和霍纳法则,通过简单的乘法和加法,瞬间将数据还原为接近32位精度的正弦/余弦值。
3. 8位进,16位出
专利中最有趣的操作是「位移技巧」:将乘累加器变成高速交织器,通过位移操作将两个8位数值粘合成一个16位输出。这意味着,在不增加任何物理线路的情况下,芯片内部有效带宽直接翻倍。
从「健忘」到「过目不忘」
这项底层数学创新,直接解决了自动驾驶中最大的挑战之一:物体恒存性(Object Permanence)。
超长记忆:以前的FSD可能会因为视线被遮挡5秒就「忘记」路标。现在的芯片利用RoPE和混合精度架构,能精准追踪30秒甚至更久之前的数据。那个被遮挡的路标,就像被钉子钉在AI的3D地图中一样纹丝不动。
内存魔法:为了承载这30秒的高清记忆,特斯拉引入了对数存储KV Cache(内存占用减半,记忆容量翻倍至 128k)和分页注意力(像操作系统管理虚拟内存一样动态分配显存)。
永不崩溃:引入「注意力汇点(Attention Sink)」,强制保留序列开始的关键Token,确保机器人即使连续工作8小时,神经网络也不会因计算漂移而「崩溃」。
当对手富可敌国
特斯拉为何要被逼着在8位芯片上跑出32位的精度?为何要重新设计整套数学逻辑?
看看它的对手——英伟达,你就会明白「战略独立」的含金量。

第四大「经济体」的压迫感
英伟达已经不再仅仅是一家公司,从体量上看,它更像是一个超级大国——
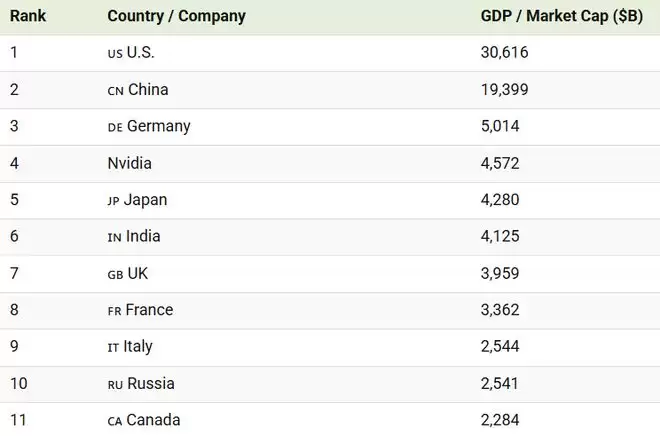
它不仅是史上第一家、也是唯一一家市值突破过 5万亿美元 大关的公司。
如果我们将这一市值放入国际货币基金组织(IMF)的国家GDP排名中,英伟达将超越日本、印度和英国,直接坐上世界第四大经济体的交椅——仅次于美国、中国和德国。
尽管将公司的市值(存量财富)与国家的GDP(年度产出)直接对比并非完全精准的经济学算法,但这种视觉冲击力足以说明问题:在AI时代,算力即国力。
拓展阅读:英伟达,全球首个5万亿美元公司诞生!「GPU帝国」超日本德国GDP
比总量更可怕的是效率。
英伟达创造这一富可敌国的估值,仅依靠了3.6万名员工。作为对比,被其超越的日本GDP,是由1.24亿人口辛勤劳作支撑起来的庞大经济机器。
这意味着,在AI革命的浪潮尖端,一个人才加上正确的算力杠杆,其创造的资本价值可以是传统工业社会模式的数千倍。
护城河的延伸
是什么支撑了这5万亿的帝国?
除了黄仁勋口中「销量好到爆表」的Blackwell芯片和早已售罄的云端GPU产能,英伟达的野心正在向特斯拉的腹地延伸。
硬件只是入场券:英伟达真正的底牌是CUDA生态。正如沃伦·巴菲特所言,这构成了极宽的「护城河」。它通过极其粘性的软件环境锁死了开发者,让任何试图迁移到其他芯片(包括特斯拉试图做的)的成本变得极高。
物理AI的新战场:英伟达不再满足于让AI在屏幕里聊天,它正在大举进军「物理AI」——即机器人、自动化和工业系统。
正是在这样一个由5万亿巨头统治、且入场费极其昂贵的「物理AI」赛道上,特斯拉的那种「在8位芯片上跑出32位精度」的突破,才显得尤为关键。
而Dojo 3与AI5的组合,就是特斯拉在这场不对称战争中,打出的最强反击。
参考资料:
https://x.com/Teslaconomics/status/2013047446348431385
https://x.com/elonmusk/status/2013108912380326218
https://www.tomshardware.com/tech-industry/artificial-intelligence/elon-musk-reveals-roadmap-with-nine-month-cadence-for-new-ai-processor-releases-beating-nvidia-and-amds-yearly-cadence-musk-plans-to-have-the-highest-volume-chips-in-the-world

相关攻略

ABB机器人与英伟达达成合作,缩小虚拟仿真与现实工业应用差距 3月10日消息,工业自动化领域的知名动向来了:ABB机器人业务部门与英伟达牵手了。双方的合作目标很明确,就是要解决一个长期困扰行业的“老大难”——工业机器人在虚拟仿真里表现完美,但一到真实工厂车间,怎么就“水土不服”了? 具体怎么操作呢?

IT之家 3 月 31 日消息,深圳制造商 eGryphon 现已在众筹平台 Kickstarter 上线了一个 OCuLink 显卡坞项目。其体积 1 86L,内置 400W 电源和桌面端的英伟达

文 | 伯虎财经,作者 | 楷楷开年至今,全民掀起了一股“龙虾热”,以OpenClaw为代表的开源AI智能体迅速走红,全球用户忙着养数字员工“干活”,Token消耗量呈指数级暴涨。为此,英伟达CEO

henry 发自 凹非寺量子位 | 公众号 QbitAI还记得Hugging Face去年推出的桌面机器人Reachy Mini吗?在刚发布的时候,量子位曾第一时间报道过这只身高28cm、体重1 5

IT之家 3 月 31 日消息,英伟达更新 GeForce Now 云游戏服务,在最新 2 0 83 版本中,专门针对苹果 Vision Pro 头显,提升游戏串流画质。本次版本更新全面解锁高帧率模
热门专题







热门推荐

目录 1 从冷门到日均 $2M 的独立赛道 2 这其实是一个短期期权市场 3 极致的精准博弈:为何 0 79% 的价差里藏着大机会? 4 抓住订单簿里的僵尸红利 5 大神模板:拆解 VibeTrader 的包围网打法 6 交易者实操指南:如何寻找你的 Edge? 本文导读 Polymar

别再瞎选 GEO 工具了!2026 年这 4 款软件亲测好用 投入大把预算做营销,结果客户在AI里一搜,发现的全是对手的信息——这种尴尬,不少品牌都遇到过吧?根据《GEO全域流量协同打造品牌增长超级引擎》白皮书,GEO作为优化AI模型答案的关键策略,眼下正成为驱动品牌增长的超级引擎。那么,市面上哪些

敦煌网究竟怎么样?深度解析这个跨境电商平台的真实面貌 谈到中国跨境电商,敦煌网绝对是一个绕不开的名字。它高频出现在各种出海讨论中,但伴随的疑问也不少:这个平台到底靠不靠谱?为买卖双方带来了什么价值?今天,我们就抛开笼统的宣传,从几个关键维度,把敦煌网的里里外外梳理清楚。 平台优势:不止于“大而全”

擒贼先擒王:《军团再临Remix》关键任务实战解析 在《魔兽世界:军团再临Remix》中,“擒贼擒王”算得上是一个标志性的挑战。它不仅考验玩家个人的战斗技巧,更是一场对团队协作与战术理解的综合测试。想要在这场狩猎中取胜,拿到丰厚的经验、金币和装备奖励,有些门道你得先摸清楚。 魔兽世界军团再临remi

潜力与体验升级下的商业转型样本 实体商业的客流焦虑,早已不是什么新鲜话题。但就在这片略显沉寂的土壤上,一个意想不到的“客流发动机”正在轰鸣运转——专业室内真人CS品牌镭战大联盟(GLSA)。你或许很难想象,周末早晨十点,在上海五角场万达广场的店里,已经能看到家长带着孩子在前台排队。门店教官的反馈更直