Meta Llama 4 即将发布:1300位作者报告揭示其潜力
编辑 | Panda
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
路透社消息,Meta最新组建的AI团队本月已在内部交付了首批关键模型。据透露,该信息来自Meta公司首席技术官Andrew Bosworth,他表示团队开发的AI模型“表现非常出色”。
早在去年12月就有报道称,Meta公司正在研发一款代号为“Avocado”的文本AI模型,计划于第一季度发布;同时还在开发另一款代号为“Mango”的图像与视频AI模型。Bosworth并未具体透露哪几款模型已交付内部使用。
值得注意的是,就在这篇报道发布的前几天,一份名为《Llama 4家族:架构、训练、评估与部署说明》的技术报告在arXiv平台悄然上线。报告全面回顾了Meta Llama 4系列模型所宣称的数据与技术成就。

报告标题:The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
需要说明的是,上传这份报告的作者是Meta公司一位机器学习工程师Arthur Hinsvark,但这份报告并未明确标识来自Meta官方。
尽管如此,这份报告还是将Llama 4项目的所有参与者都加入了作者名单——超过1300人,足足占了5页篇幅!因此,我们可以大体上认为这份报告就是来自Llama 4团队,尽管其中不少人现在已经从Meta离职,比如前Meta FAIR团队研究总监田渊栋。
值得注意的是,这份报告的引言有一段明确说明:“本文档是对公开材料的独立调查。报告中的基准数值归因于模型卡,除非另有说明;应将它们视为开发者报告的结果,并对评估工具、提示工程和后处理持通常的保留态度。”
也就是说,这份报告整体回顾了Meta公布的各种Llama 4相关材料,尤其是其宣称的一些数据。但没有明确解释其在实际应用中表现明显不及预期的原因。想要了解相关背景的读者可参阅:
Meta Llama 4被疑“作弊”:在竞技场刷高分,但实战中频频翻车;Llama 4在测试集上训练?内部员工、最新下场澄清,LeCun转发
不过,该报告也并非完全没有提到相关原因。仔细阅读的话,我们能在行文中看到一些端倪。其中主要的讨论点集中在部署限制和榜单争议上:
架构能力与实际部署的差距(尤其是上下文长度):论文反复强调了一个“经常出现的操作主题”:模型的架构支持能力与实际服务中提供的能力之间存在差距。虽然Scout在架构上设计为支持10M上下文长度,但在实际部署中(如Cloudflare或AWS),由于显存和KV缓存的硬件成本限制,服务商往往将可用上下文限制在128K或1M。这意味着用户在实际使用托管服务时,可能无法体验到模型宣称的全部长上下文能力。
榜单成绩与发布版本的差异:论文提到了关于LMArena排行榜的争议。Meta在榜单上提交的Maverick“实验性聊天”变体与公开发布的版本不完全相同。这导致了外界批评其“操纵基准测试”。这也解释了为什么用户使用公开发布版本时的体验,可能与某些榜单上的高分表现不一致。
营销话术与技术指标的区别:论文明确指出,发布公告中的某些声称(例如Scout是“同类最佳”或强调性价比)属于“面向营销的主张”,应当与严谨的模型卡基准测试结果分开解读。
这些细节似乎暗示了这份报告是Meta Llama团队对于Llama 4系列模型备受社区广泛批评(数据亮眼但能力很差)的最终回应。
对于这些说明,不知道你怎么看?
具体到内容上,这篇技术报告的内容仅有15页,其中1300多位作者的名单就足足占了5页,再去掉一页参考文献,实际内容仅有9页。其中,Meta Llama团队总结了:
已发布的模型变体(Scout和Maverick)以及更广泛的系列模型背景,包括预览版的Behemoth教师模型;
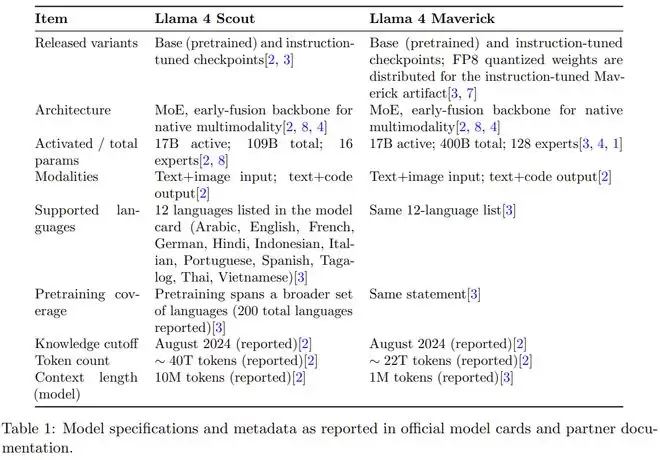
超越高级MoE描述的架构特征,涵盖路由/共享专家结构、早期融合多模态,以及针对Scout报告的长上下文设计元素(iROPE和长度泛化策略);训练披露,跨越预训练、用于长上下文扩展的中期训练,以及发布材料中描述的后训练方法(轻量级SFT、在线RL和轻量级DPO);开发者报告的基础和指令微调检查点的基准测试结果;在主要服务环境中观察到的实际部署限制,包括特定于提供商的上文限制和量化打包。
此外,这份报告还总结了“与再分发和衍生命名相关的许可义务,并回顾了公开描述的安全措施和评估实践。其目的是为需要关于Llama 4精确、有来源依据的事实的研究人员和从业者提供一份紧凑的技术参考。”
更多详情请参阅原报告。
相关攻略

在人工智能快速发展的今天,我们经常听说AI助手能够调用各种工具帮助人类完成任务,比如查询信息、计算数据或生成文档。然而,在现实应用中,这些AI助手必须在各种限制条件下工作——就像一个厨师不仅要会做菜

一水 发自 凹非寺量子位 | 公众号 QbitAI编程智能体时代,顶流Cursor举旗发布新的评测基准——CursorBench,专门评价Cursor中不同模型谁更“智能体”(即高效执行复杂任务)。

北京商报讯(记者 陶凤 王天逸)3月10日,原力无限宣布,以第一作者单位首发AtomVLA模型。据称,该具身大脑核心模型LIBERO基准成功率达到97%,在真机平台上,AtomVLA成功完成了叠T恤

机器之心编辑部如果有价值 $100 万美金的顶级专家任务,AI 能完成其中多少?答案是 48 万美金,而只需要 100 美元的 Token 费用。这个数字怎么来的?Humanlaya Data La

IT之家 3 月 9 日消息,BrowseComp 是一项基准测试,用于检验人工智能模型在网络上查找难以定位信息的能力。当人工智能公司 Anthropic 将其 Claude Opus 4 6 模型
热门专题







热门推荐

绿联充电头爆炸事件全解析:用户险遭毁容,品牌售后方案为何引发不满? 近来,数码配件安全领域爆出一桩令人担忧的事件。知名3C品牌绿联旗下的一款USB充电器在正常使用过程中突然发生爆炸,火花飞溅,险些造成用户眼部受伤。这起安全事故迅速在社交平台发酵,引发广大网民对消费电子产品质量与售后服务的集中讨论。

红色沙漠中断的研究任务怎么做?完整通关流程与奖励详解 《红色沙漠》中的“中断的研究”是斯科拉斯敦学会势力任务线的关键支线之一。许多玩家在推进学会声望时都会遇到这个任务,本文将为你整理最新、最全的任務攻略,助你顺利完成并获取丰厚回报。 红色沙漠中断的研究任务有哪些 一 任务基本信息与前置要求 任务类

从通信到算力:商业卫星的「百万颗」狂飙之路与星空危机 近期,全球天文学界向美国联邦通信委员会(FCC)提交的一份联合意见书,引发了巨大震动。细看署名便可感知其分量——这份文件由美国天文学会(AAS)牵头,联合了国际天文学联合会(IAU)、英国皇家天文学会(RAS)、欧洲南方天文台(ESO)等几乎所有

iPhone 18系列全面前瞻:性能巨变下的取舍与市场战略新布局 最新产业链动态显示,下一代iPhone 18标准版很可能在外观设计上延续前代风格,仅对屏幕尺寸进行小幅优化。这一消息迅速引发科技爱好者热议,许多用户纷纷评论:苹果在创新节奏上似乎再次进入“挤牙膏”模式。 回顾去年亮相的iPhone 1

龙胤立志传先天功怎么获得 一、先天功获取途径总览 作为一本标注为“江湖”的无门派顶级橙色内功心法,《先天功》的获取方式多样,能满足不同阶段玩家的需求。总体而言,主要可通过以下四个核心途径入手: 首推 皇家宝库奇遇,此途径充满机遇,有机会在探索宝库深处时直接获得。其次是 拍卖行竞拍购买,只需备足银两,