
新智元报道
编辑:LRST
【新智元导读】当下多数多模态模型仿佛被困在了一座名为“视频”的孤岛中——它们只能针对视频内容本身进行问答。但在现实世界里,人类解决问题的方式往往是“观看视频寻找线索 → 上网搜索查证 → 综合推理判断”。为了填补这一空白,来自QuantaAlpha、兰州大学、香港科技大学(广州)、北京大学等机构的研究者联合推出了首个视频深度研究测评基准VideoDR。
在传统的视频问答任务中,答案通常就隐藏在视频画面里。
然而,一个真正智能的视频代理,必须具备深度研究的能力。
想象这样一个场景:你看到视频中博物馆的一件展品,想知道“该博物馆推荐的展品里,距离这展品最近的那个,其注册编号是多少?”
这不仅需要理解视频内容(识别展品、定位位置),还需要跳出视频框架,去博物馆的官方网站查找地图、推荐列表和编号信息。

双依赖测试:剔除了那些“只看视频就能答”或“只搜文字就能答”的样本,确保模型必须结合两种能力。
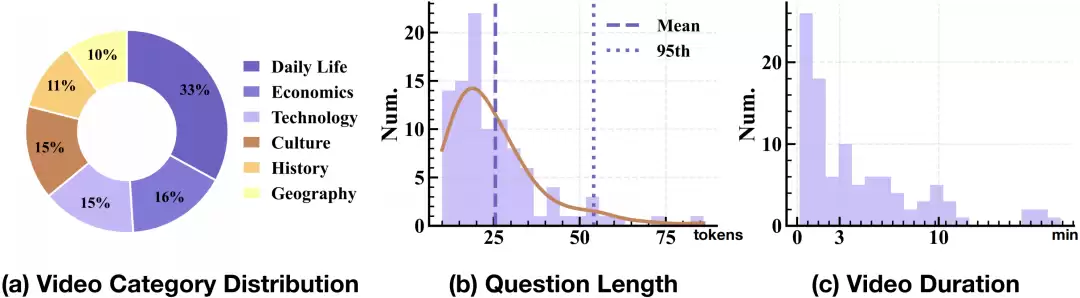
六大领域覆盖:涵盖日常生活、经济、科技、文化、历史、地理。
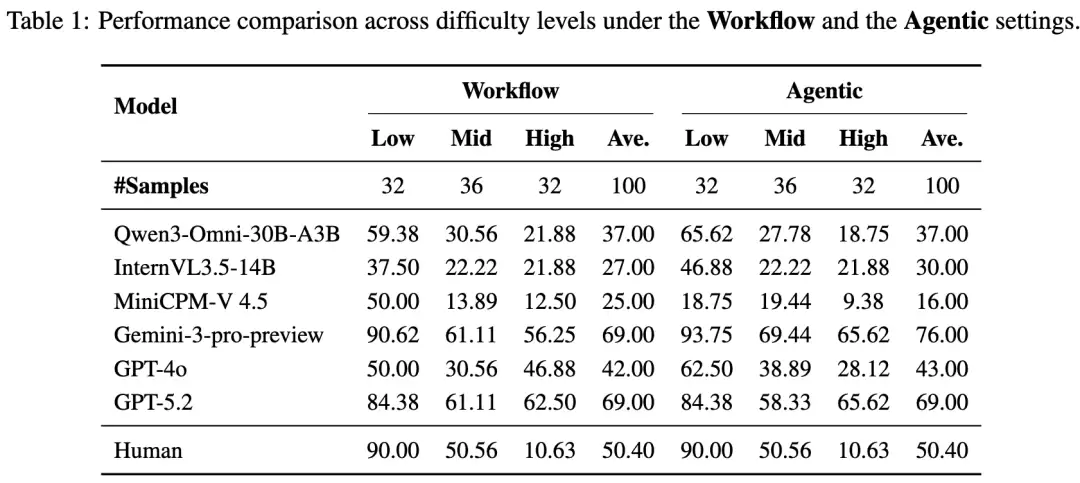
Workflow 与 Agentic 模式对比
研究人员对比了两种主流范式:
工作流模式:将视频转化为结构化文本线索,再进行搜索推理。
代理模式:模型直接端到端处理视频和搜索,自主决定何时搜索、何时思考。
测评模型:
闭源模型:GPT-5.2, GPT-4o, Gemini-3-pro-preview
开源模型:Qwen3-Omni-30B-a3b, InternVL3.5-14B, MiniCPM-V 4.5
核心发现与洞察
谁是目前的最强王者?
Gemini-3-pro-preview和GPT-5.2处于第一梯队,准确率达到了69%-76%左右,显著领先于其他模型。
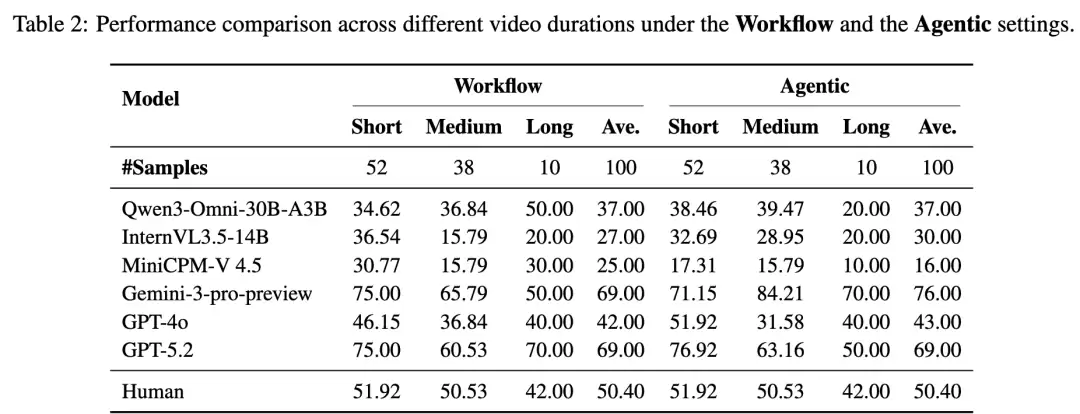
代理模式一定更强吗?
答案是不一定。
虽然代理模式更灵活,但在长视频或高难度任务中,模型容易出现目标漂移。
工作流模式的优势:显式的中间文本充当了“外部记忆”,防止模型在漫长的搜索链路中忘记最初视频里的视觉细节。
代理模式的短板:一旦初始的视觉感知出现偏差,且无法回看视频,错误的搜索路径会被不断放大。
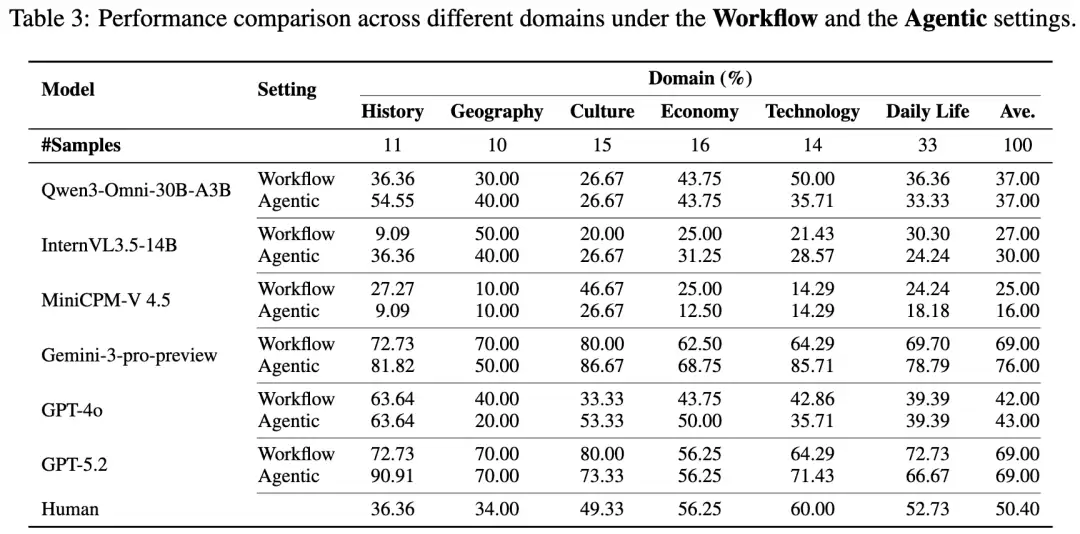
长视频是“照妖镜”
在长视频场景下,模型保持长期一致性的能力成为瓶颈。
强如Gemini-3在代理模式下能利用长上下文获得提升,而部分开源模型在长视频下性能反而大幅下降。
总结
VideoDR将视频理解的战场从封闭测试集延伸到了无限的开放网络。
测评结果深刻揭示了“端到端”并非万能药:在面对长链路搜索时,模型往往会陷入“记忆衰退”的困境。
未来的视频智能体只有在保持视觉线索的长程一致性上取得突破,才能真正胜任现实世界的复杂调研任务。




