微软开源统一语音识别模型VibeVoice-ASR,赋能长音频处理
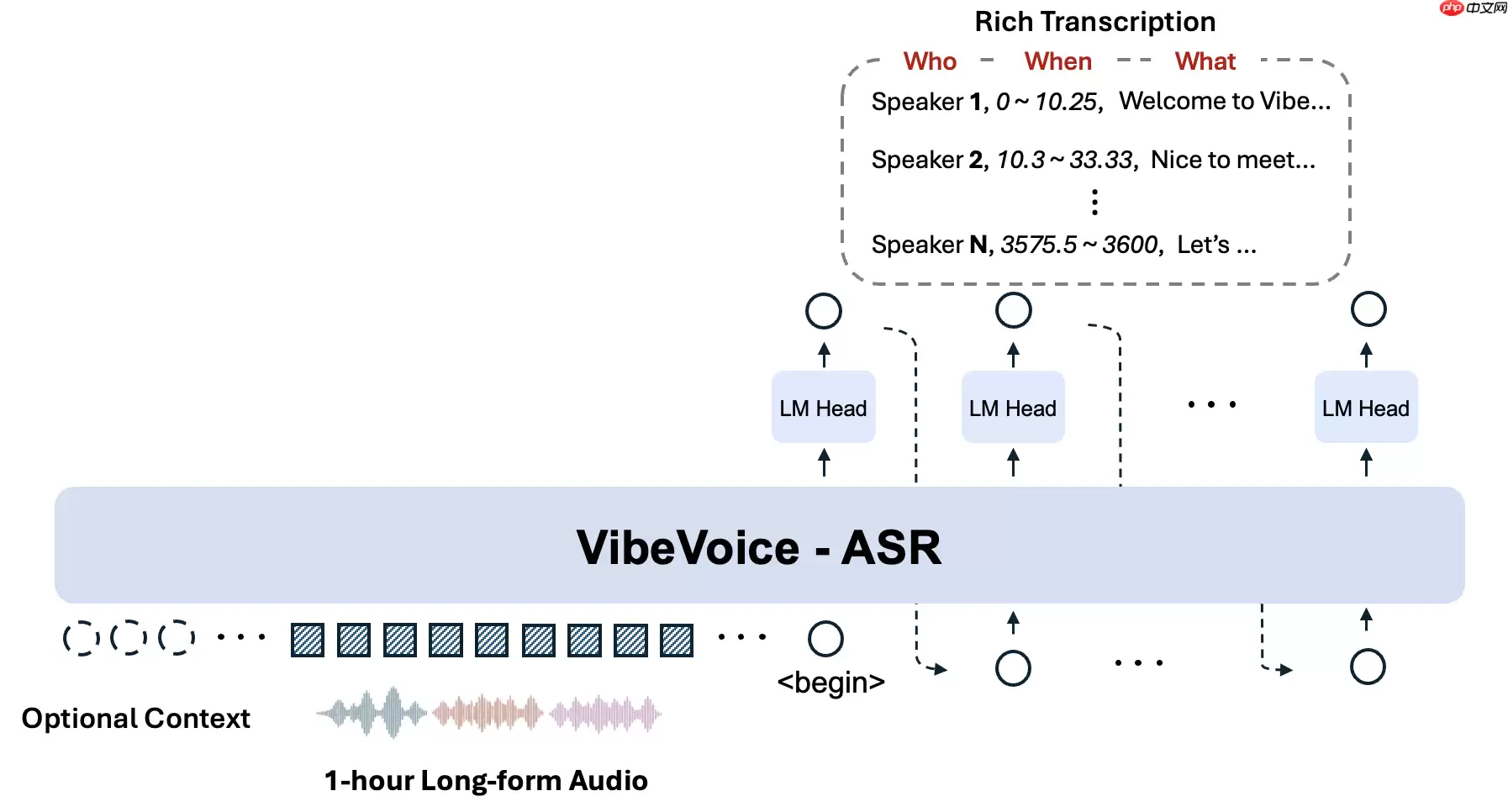
微软近日开源了全新的统一语音识别模型VibeVoice-ASR,其参数量高达惊人的900亿。该模型专门针对长音频理解任务而设计,能够一次性处理最长60分钟的连续语音流,并在单次推理中直接输出结构化的转录结果——包含说话人身份标识、毫秒级精确时间戳及对应的文本内容。此外,该模型还支持用户灵活地注入领域专属热词,从而增强对专业术语、专有名词或上下文敏感词汇的识别鲁棒性。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
VibeVoice-ASR的核心能力亮点:
- 原生支持长达60分钟的端到端音频处理:区别于传统自动语音识别(ASR)模型需将长音频切分为数秒级短片段(易造成上下文断裂与说话人混淆),VibeVoice-ASR原生适配最大长度为64K token的音频序列,完整覆盖一小时语音,保障跨时段说话人一致性建模与语义连贯性建模。
- 可配置热词引导机制:用户可通过简单接口传入自定义热词列表(如企业名称、产品型号、学术概念等),模型在解码阶段动态强化相关词元概率,显著提升垂直场景下的识别精度。
- 三位一体化结构化输出(Who-When-What):模型深度融合语音识别、声纹区分与时间定位能力,同步完成说话人分离、起止时间标注与文本转写,最终生成清晰可解析的“谁在何时说了什么”格式结果。
模型整体架构如下:
开源地址
热门专题







热门推荐

PChome 3月31日消息,OPPO官微官宣,OPPOx哈苏影像新品联合发布会将于4月21日晚19:00在成都举办,Find X9s Pro、Find X9 Ultra等新品将至。据了解,OPPO

小红书网页版登录入口为https: www xiaohongshu com explore,支持扫码、手机号验证码及微信三种登录方式,首页默认瀑布流展示热门笔记,具备多维度内容检

两年前,谢添天发现自己的声音被一款APP“盗”走——用户输入文本,即可用他的音色生成以假乱真的AI声音。维权半年,因举证难度太高,最终以和解和对方致歉了结。两年后,一场大规模的联合发声,将AI盗声侵

来源:央广网3月28日至29日,以“发挥主流媒体引领力 激发多元主体创造力——共创繁荣网络内容生态”为主题的2026中国网络媒体论坛在河南郑州举行。网络媒体因技术而诞生,凭创新而繁荣。面对新一轮科技

当大语言模型与AgenticAI(智能体)从试验场进入企业级生产环境,SaaS行业的底层价值逻辑正面临系统性重估。这一轮变革的核心,正指向“AI CRM 2 0”的全面到来——它不再是传统CRM的功