液态神经网络小模型仅用900M内存,突破Transformer架构推理瓶颈
编辑|冷猫
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
谷歌 2017 年提出的 Transformer 架构事实上已经基本垄断了大模型。
不采用 Transformer 架构的大模型已经是少之又少,而采用非 Transformer 架构,还能与主流第一梯队大模型扳手腕的,更是凤毛麟角。
不知道大家是否还有印象,当年有一个尝试给大模型装上「虫脑」的初创公司,他们的研究人员受到秀丽隐杆线虫的神经结构启发,研发出一种新型的灵活神经网络,也被称为液态神经网络。
这是一个连续时间模型,由多个简单的动态系统组成,这些系统通过非线性门相互调节。这种网络的特点是时间常数可变,输出通过求解微分方程得到。它在稳定性、表达能力和时间序列预测方面都优于传统模型。
除此以外,液态神经网络的另一个特点是规模小得多,在 2024 年该架构就实现了 1.3B 大小的模型部署,但彼时尚未能与主流大模型一拼高下。
提出液态神经网络架构,并且做出 Liquid Foundation Models(LFM)大模型的,是由 MIT 计算机科学和人工智能实验室 CSAIL 孵化,成立于 2024 年 3 月的初创公司 Liquid AI。
就在刚刚,Liquid AI 又一次在 LFM 模型上放大招。他们正式发布并开源了 LFM2.5-1.2B-Thinking,一款可完全在端侧运行的推理模型。

Liquid AI 声称,该模型专门为简洁推理而训练;在生成最终答案前,会先生成内部思考轨迹;在端侧级别的低延迟条件下,实现系统化的问题求解;在工具使用、数学推理和指令遵循方面表现尤为出色。
该模型在手机上仅需900 MB 内存即可运行,同时在同等规模模型中实现了最快的推理速度和最佳的质量表现。两年前还必须依赖数据中心才能完成的能力,如今已经可以在你的口袋里离线运行。
Leap 开源链接:https://leap.liquid.ai/modelsHuggingFace 链接:https://huggingface.co/LiquidAI/LFM2.5-1.2B-Thinking
优于 Transformer 的性能
与 Liquid AI 之前的模型 LFM2.5-1.2B-Instruct 相比,LFM2.5-1.2B-Thinking 在三项能力上实现了显著提升:
数学推理:在 MATH-500 上从 63 提升至 88指令遵循:在 Multi-IF 上从 61 提升至 69工具使用:在 BFCLv3 上从 49 提升至 57
在大多数推理基准测试中,LFM2.5-1.2B-Thinking 的表现已与甚至超过 Qwen3-1.7B,尽管其参数量少了 约 40%。
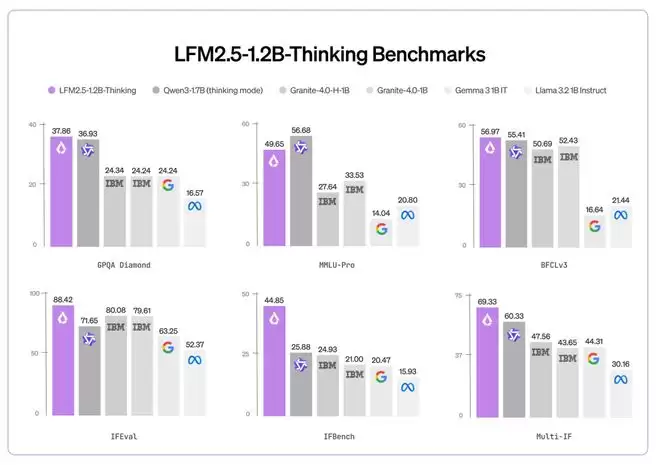
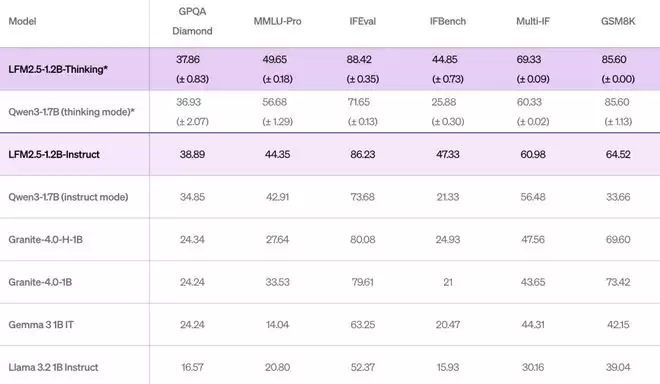
同时,该模型在质量与测试时计算效率之间取得了良好平衡:与 Qwen3-1.7B(思考模式) 相比,它在使用更少输出 token 的情况下,依然提供了更高的整体性能。
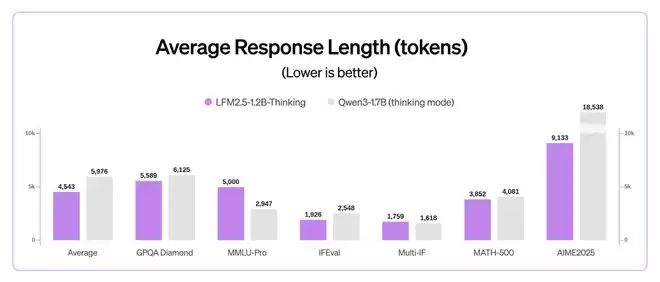
在推理阶段,这一性能差距进一步拉大:LFM2.5-1.2B-Thinking 在推理速度和内存效率两方面,都优于纯 Transformer 模型(如 Qwen3-1.7B)和混合架构模型(如 Granite-4.0-H-1B)。
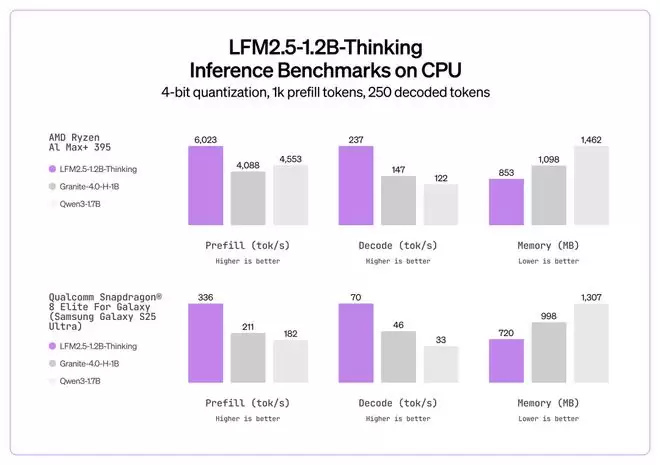
Liquid AI 表示,LFM2.5-1.2B-Thinking 在 智能体式(agentic)任务和高推理强度任务(例如工具使用、数学、编程)中表现尤为突出。当模型需要规划一系列工具调用、验证中间结果并动态调整解题策略时,其生成的推理轨迹能够发挥实际价值。而在对话交互和创意写作等场景下,则更推荐使用 LFM2.5-1.2B-Instruct。
训练细节
要构建能力强的小型推理模型,关键在于:在知识容量有限的前提下,通过多步推理来弥补能力,同时又要保持答案简洁,以满足端侧低延迟部署的需求。
此前在 LFM-1B-Math 上的实验表明,在中期训练阶段引入推理轨迹,有助于模型内化「先推理,再作答」的模式。随后,基于合成推理轨迹进行的监督微调(SFT),进一步让模型能够稳定地产生思维链,而无需依赖特定格式的奖励设计。
然而,SFT 并不能解决推理模型中的一个常见问题:模型可能陷入重复文本模式,迟迟无法得出结论。这种行为通常被称为「doom looping」(死循环式生成)。为此,Liquid AI 采用了一种相对直接的缓解方法:
在偏好对齐阶段,基于 SFT 模型生成了 5 个温度采样候选和 1 个贪婪解码候选;当不存在循环时,选择由 LLM 评判得分最高的作为正样本、得分最低的作为负样本;一旦出现循环生成,则无论评判得分如何,直接将出现循环的候选作为负样本。在 RLVR 阶段,进一步在训练早期引入了基于 n-gram 的重复惩罚,以抑制循环生成行为。
通过这些策略,模型在保持推理能力的同时,显著降低了陷入无效循环的风险。

这一方法在一个具有代表性提示词的数据集上,将死循环生成的比例从 15.74%(中期训练阶段) 显著降低到了 0.36%(RLVR 阶段),效果非常直接且稳定。
Liquid AI 的 RL 训练流水线核心采用的是无 critic、类 GRPO 方法。整体实现是 reference-free 的,并结合了多项训练技巧,包括:
非对称比例裁剪(asymmetric ratio clipping)对零方差提示组的动态过滤超长样本掩码(overlong-sample masking)不进行优势归一化(no advantage normalization)截断的重要性采样(truncated importance sampling)
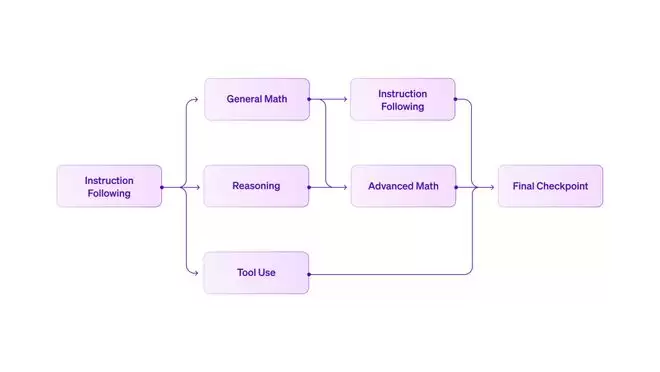
RL 方法的简化示意图:最终发布的 checkpoint 是一个合并模型,其「家族树」中包含 25 个不同的子 checkpoint。
Liquid AI 采用了一种高度并行的Curriculum RL 训练框架,先以指令跟随的 RLVR 作为基础起点,再分叉出面向推理、数学、工具使用等不同领域的专项 checkpoint。
这种并行结构不同于传统的「单模型、多任务同时训练」方式,往往会引发能力相互干扰。
Curriculum RL 提供了更精细的控制粒度:每个领域的模型都可以独立优化,拥有各自的奖励设计、超参数和评估标准。随后,我们在不同阶段进行迭代式模型合并,生成在多种能力之间更均衡的新 checkpoint。
实践表明,模型合并在保留整体性能的同时,能够有效吸收专项能力提升,是一条可行且可扩展的通用 RLVR 训练路径。
此外,Liquid AI 正在全力拓展 LFM 系列模型的生态系统和合作伙伴。
LFM2.5-1.2B-Thinking 实现了开箱即用支持,兼容最流行的推理框架,包括 llama.cpp、MLX、vLLM 和 ONNX Runtime。所有框架均支持 CPU 和 GPU 加速,覆盖 Apple、AMD、Qualcomm 和 Nvidia 等硬件。
为了确保 LFM2.5 系列 能够在各种场景下高效运行,Liquid AI 正在快速扩展软硬件生态系统,并欢迎 Qualcomm Technologies, Inc.、Ollama、FastFlowLM 和 Cactus Compute 作为新的合作伙伴加入。
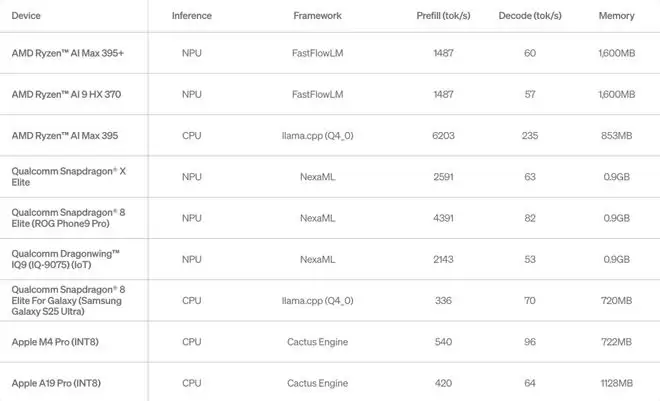
LFM2.5-1.2B-Thinking 在不同硬件设备上的长上下文推理表现。
LFM2.5-1.2B-Thinking 可能只是个起点,但它已经证明了一件事 ——Transformer 并非唯一解,小而强的端侧推理模型或许有更优解。
更重要的是,运行推理模型的门槛越来越低,让更多设备激发 AI 潜能,不论如何,都是一件美事。
参考链接:https://www.liquid.ai/blog/lfm2-5-1-2b-thinking-on-device-reasoning-under-1gb#training-recipe
相关攻略

OpenClaw的爆火,让众多AI应用开发者第一次直面了高昂的Token账单——一个用户请求可能触发多轮工具调用,每次调用都携带超长上下文,实际的API成本远超预期,甚至可能达到订阅费用的数十倍。如何有效控制Token成本,正成为AI Agent开发者面临的核心挑战与增长瓶颈。 这显然不是可持续的商

这项由瑞士洛桑联邦理工学院(EPFL)、意大利卢加诺大学(USI)、韦斯利安大学、巴黎脑研究所(ICM)以及宾夕法尼亚州立大学联合开展的研究,以预印本形式发布于2026年4月,论文编号为arXiv:2604 03480。对这一交叉领域感兴趣的读者,可以通过该编号在arXiv平台上查阅完整原文。 一、

北京商报讯(记者 陶凤 王天逸) 人工智能领域又传来一条振奋人心的消息。4月8日,摩尔线程正式宣布,其旗舰级AI训推一体全功能GPU——MTT S5000,已经成功完成了对智谱新一代旗舰模型GLM-5 1的Day-0极速适配。这意味着,推理部署与训练复现的全部流程,现在都能在这条国产算力路径上获得支

如何用SQL求解逻辑推理题:经典楼层分配谜题实战 今天我们来探讨一个非常有趣的技术应用:使用SQL来求解逻辑推理题。这听起来或许有些大材小用,但正是这种跨界应用,充分展现了SQL语言的强大灵活性以及开发者分析问题的思维能力。我们将以一个经典的五人楼层分配谜题作为案例,逐步拆解如何用纯粹的SQL找到答

一个学生忽视了一行代码,结果发现了一件很不对劲的事:在一个多模态医学AI项目中,这行代码原本负责让模型读取图像数据。但因为这次疏忽,模型实际上完全没有看到任何图片。按理说系统应该报错,或者至少拒绝回
热门专题







热门推荐

短期课程 开发人员的ChatGPT提示工程 你将在本课程中学到什么 想用大型语言模型(LLM)快速构建强大的应用吗?《开发人员的ChatGPT提示工程》这门课,正是为你准备的。通过OpenAI API,你将能解锁那些在过去成本高昂、技术门槛高甚至无法实现的能力,快速将创新想法转化为价值。 这门短期课

志设是什么 在创意设计领域,灵感与效率往往难以平衡。是否存在一个工具,既能深度理解您的创意构思,又能迅速将其转化为高品质视觉作品?这正是专业级AI图像生成平台“志设”致力于解决的核心问题。 简而言之,志设是一个融合了前沿人工智能技术的综合性设计解决方案平台。它全面覆盖从平面广告、海报设计到网页UI、

对于渴望提升外语口语与听力水平的学习者而言,如何找到一个高效、便捷且能轻松练习的环境,常常是首要难题。今天我们要深入解析的这款产品——TalkMe,正是精准切入这一需求,试图通过前沿的AI技术,提供一种全新的语言练习解决方案。 简而言之,TalkMe是一款专注于跨语言学习的AI应用,其核心功能设计紧

当冰冷的钢铁巨兽被注入炽热的战斗意志,会碰撞出怎样的战略火花?《王牌机甲》这款游戏,将宏大的科幻叙事深度融入现代战争战术框架,为玩家开启了一段关于征服、策略与深厚羁绊的未来纪元。 在这里,你绝非孤军奋战。每一位通过招募加入的精英机师,都拥有独立的背景故事、专属技能树与独特的成长路线。游戏核心的“羁绊

《暗黑大天使》的技能分支系统提供元素、物理和辅助三大专精方向,玩家需根据角色属性与战斗需求选择分支。技能可投入资源升级并可能触发连锁效果,实战中需结合装备、敌人及团队配合灵活运用。该系统丰富了玩法,但需大量资源与多系统联动,选择需谨慎规划。