
编辑|+0
提到具身智能,你首先会想到什么?
是宇树在春晚惊艳亮相的「转手绢」、特斯拉 Optimus 的「金色传说」、真到被怀疑真假的小鹏,还是 2025 年各家竞相上演的「炫技大赏」,空翻、家务、热舞、打拳,无所不能?

已经过去的 2025 年,无疑是具身智能大爆发的一年。
热闹属于硬件,但具身智能还有另一个关键赛道:具身智能与机器人基础模型,即具身智能的「大脑」。它们定义了具身智能的智力天花板,也长期主导了行业对「通用性」的解释权。
在这个赛道,过去两年的叙事主线几乎被 Pi、Google、Figure 等海外团队主导。但在 2026 年伊始,格局发生了变化。
1 月 12 号,千寻智能(Spirit AI)开源了自研 VLA 基础模型Spirit v1.5,该模型在第三方机器人模型评测组织RoboChallenge 的 Table30 榜单上位列第一,超过了之前最强模型 Pi0.5。
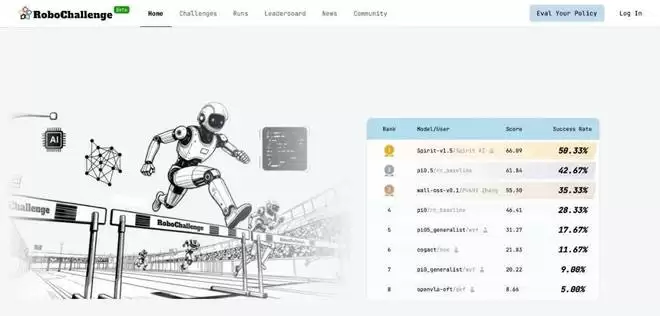
千寻开源了Spirit v1.5的基模权重、推理代码以及使用样例,接受公众检验,也方便社区在 Spirit v1.5 的基础上创新。
Code: https://github.com/Spirit-AI-Team/spirit-v1.5Model: https://huggingface.co/Spirit-AI-robotics/Spirit-v1.5Blog:https://www.spirit-ai.com/en/blog/spirit-v1-5

Spirit v1.5 vs Pi0.5 视频对比。上:Spirit v1.5,下:Pi0.5。
这一手「硬核登顶+开源共享」的组合拳,引发了海外 AI 社区的即时关注,甚至引来了英伟达具身智能负责人 Jim Fan(范麟熙)的点赞、Hugging Face 的最新祝贺,以及多位海外大 V 的转发。
这不再是一次简单的榜单轮换。它意味着,在具身智能这个未来的核心战场上,中国团队终于结束了「跟随模式」,正式拿到了「全球第一梯队」的入场券。
Spirit v1.5 为什么能赢 Pi0.5?
要回答这个问题,我们必须先看一眼「竞技场」。
RoboChallenge 是由 Dexmal、Hugging Face 和智源研究院等机构发起的全球首个大规模真机评测平台。与常见的仿真环境跑分不同,RoboChallenge 的核心在于物理世界的真机实测
平台建立了一套名为「Table30」的任务集,包含设定在桌面环境中的 30 个多样化操作任务。这些任务不仅涵盖插花、制作三明治、插入网线等日常技能,还被特意设计用来挑战模型能力的各个维度:包括精确的 3D 定位、遮挡处理、时间依赖性以及多阶段长序列任务。
在该体系下,Spirit v1.5 在多构型机器人(包括 Franka、Arx5、UR5 及双臂 ALOHA 系统)上均进行了评测。截至 2026 年 1 月 12 日的评估显示,Spirit v1.5 在该基准测试上超越了 Pi0.5 等之前的全球领先开源模型,取得了当前最优的性能。

Spirit v1.5 vs Pi0.5 视频对比。上:Spirit v1.5,下:Pi0.5。
Spirit v1.5 的胜出并非偶然,其核心原因在于对机器人预训练数据范式的根本性重构。
摆脱「干净数据」的诅咒,
转向「物理常识」的习得
传统的具身模型,大多基于如 Open X-Embodiment (OXE)、Agibot 和 RoboCOIN 等数据集进行训练。这些数据集虽然规模庞大,但主要由高度精选的、即所谓的「干净」数据组成。
在这种模式下,为了最大化采集成功率,研究人员往往像电影导演一样精心设计场景:物体被放置在可预测、易于触及的位置,动作被简化或脚本化。这种「完美」的数据虽然为模型提供了一个稳定的起点,但却产生了一个致命的副作用:经验的零散孤岛。
如果在训练中,「擦桌子」的数据集永远只包含桌子和标准的擦拭动作,模型就永远学不会如何在抹布打滑后恢复,或者如何处理桌面上意料之外的杂物。这种过度「净化」的数据限制了机器人的泛化能力,一旦面对开放世界的不可预测性,模型极易失效。
相比之下,Spirit v1.5 采用了「开放式、目标驱动」的数据采集策略。其核心理念是摒弃书面脚本,只给操作员一个模糊的高层目标(如「清理厨房」),允许其即兴发挥。
在 RoboChallenge 的 Table30 测试中,Spirit v1.5 展现出的跨场景泛化能力主要得益于以下几点:
构建连续的技能流形
传统数据制造了任务间的割裂,而 Spirit v1.5 的数据采集员可能会先拿起食物容器,发现碎屑后开始擦拭,接着整理餐具。这种连续的会话将多个微技能自然串联,涵盖了抓取、扭转、插入和复杂的双手协调。
这意味着模型不再是机械地重复单一动作,而是学习到了动作与动作之间的过渡与衔接。如同案例所示:无论是给假人模型化妆,还是组装复杂的乐高结构,模型掌握的是一个原子技能谱系,而非孤立的动作片段。
内化的纠错与恢复能力
这是 Spirit v1.5 区别于传统模型的关键。由于训练数据通过「将采集员派往现实环境中的随机地点」获得,包含了海量的物体交互和环境转换,模型见识过各种失败与混乱。因此,Spirit v1.5 习得了类似人类的「物理常识」。
当面对复杂操作中的干扰、物体打滑或光线突变时,模型展现出了惊人的韧性,它学会了在动作执行受阻时如何进行动态调整和恢复,而不是像脚本机器那样直接死机。

多样化采集数据示例。上:采集员通过末端执行器操作给假人模型化妆。下:采集员组装复杂的乐高结构。两个案例都展示了多样化原子技能的连续流,包括抓取、扭转、插入和复杂的双手协调。
模型不是「更大」,
而是「更对」
技术报告中的消融实验进一步证实,Spirit v1.5 的优势源于更高效的数据利用策略,而非盲目的算力扩张。
实验建立了两组模型进行对比:A 组使用精选演示数据,B 组使用开放式多样化数据,且保持两组的总数据量完全相同。结果揭示了显著的「多样性增益」:
收敛速度与迁移效率:在针对全新任务微调时,使用多样化采集训练的模型(Spirit 策略)达到相同性能基线所需的迭代次数比基线模型少了 40%。这表明,任务的多样性比单任务的演示数量更为关键。
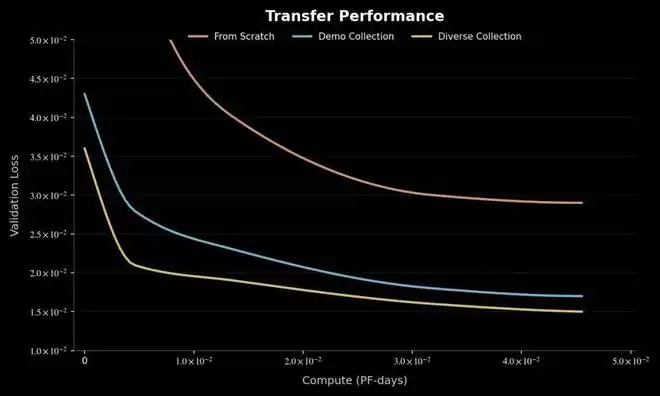
多样化采集预训练的模型比干净数据采集训练的模型具有更快的收敛速度和更好的验证误差。
验证误差的持续下降:研究还发现,随着多样化数据规模的扩大,模型在新任务上的验证误差呈持续下降趋势。这证明模型正在有效地从现实世界日益增加的内在多样性中汲取养分,形成了一种通用的策略基础。
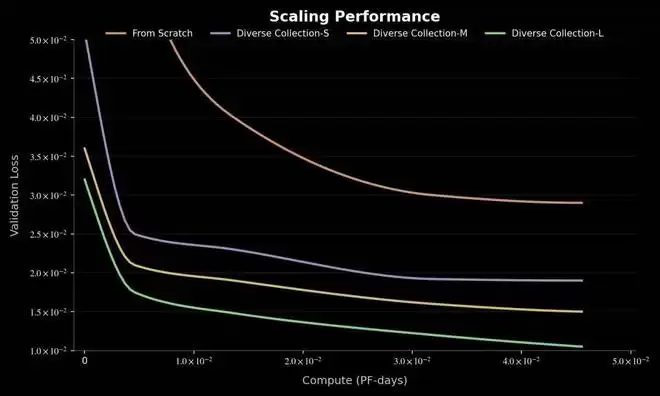
不同数据规模下的模型效果。扩大多样化采集的数据规模可以持续降低模型的验证误差。
既是「榜单杀手」,
也是「工程利器」
除了在学术榜单上领先,Spirit v1.5 在工程落地层面也解决了困扰行业已久的可扩展性的难题。
传统的「干净数据」采集需要工程师团队设计任务、编写详细指南并严格筛选数据,这种工作流程极大地限制了数据采集的体量和扩展性。
Spirit v1.5 采用的非结构化采集方式,允许操作员在只设定高层目标(如「清理厨房」)的前提下即兴发挥。这种范式转变带来了巨大的工程效益:
采集效率提升:数据显示,人均有效采集时长增加了200%。因为操作员不再是重复数百次枯燥的机械动作,而是像玩游戏一样在物理世界中互动,保持了极高的投入度。专家依赖降低:这种流程将对算法专家干预的需求削减了60%。这意味着,大规模扩展数据采集规模不再受限于稀缺的专家资源,管理成本不再线性增加。
目前,Spirit v1.5 的基模权重、推理代码以及使用样例已全部开源,供研究人员复现和探索。这不仅证明了其作为「实战派」模型的底气,也为通用机器人从实验室走向真实的家庭和产线环境铺平了道路。
中国开源力量的突破性进展
如果说技术上的超越是 Spirit v1.5 的「硬实力」,那么选择全量开源则是其更具产业价值的决定。
回顾过去两年,从 Qwen、DeepSeek 到 Kimi、GLM 等,中国的大模型团队已经证明了这一点:开源模型不仅能追平闭源模型的性能,更能成为推动全球技术平权的重要基础设施。这些来自中国的开源力量,实际上已经成为了许多海外开发者构建应用的首选基座。
不可否认,「开源共建」也已逐渐成为具身智能领域的行业共识,但拼图尚未完整。
高性能的机器人基础模型(如 Google RT 系列或 Pi)大多处于闭源或半闭源状态。开发者往往面临「两难」:要么使用性能较弱的旧模型,要么依赖大厂的 API,不仅成本高昂,且难以针对特定硬件进行适配。这种「基座缺失」直接制约了具身智能从实验室走向产业落地的速度。
Spirit v1.5 的开源,标志着中国团队正在将 LLM 领域的开源繁荣,延续到具身智能领域。
对于科研界,它打破了「无 SOTA 可用」的局面,提供了一个与 Pi0.5 同等甚至更强的可复现基线;对于产业界,它为大量试图进入具身智能赛道的中小型厂商,提供了一套经过验证的、可商用的技术底座,避免了行业性的重复造轮子。
从 Qwen、DeepSeek 到 Spirit,中国团队正在通过高质量的开源贡献,逐渐从全球 AI 生态的「参与者」转变为关键基础设施的「建设者」。
结语:
从「追随」到「定义」
RoboChallenge 的榜首位置或许会轮换,数据的记录终将被刷新,但 Spirit v1.5 的出现具有明确的界碑意义:
它通过实验证明了「非结构化的多样性是比精选数据更好的老师」。在通往通用具身智能的道路上,中国团队已经结束了单纯的「跟随模式」,具备了在核心技术路径(数据范式)与生态建设上与全球顶尖团队「对等对话」甚至「定义规则」的能力。
随着代码仓库的公开,全球的目光和测试数据将涌向 Spirit v1.5。对于千寻智能而言,登顶榜单只是一个开始,真正的考验才刚刚拉开序幕:如何在真实世界的千万种场景中,经受住全球开发者的验证与打磨。
文中视频链接:https://mp.weixin.qq.com/s/ZrBDFuugPyuoQp4S6wEBWQ




