两大博士一年研发120亿大模型独角兽

免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
作者丨漫地
编辑丨关雎
头图丨Angelopoulos(右)Chiang(左)
最近,美国加州大学伯克利分校(UC Berkeley)学术研究项目孵化出的创业公司LMArena,成为了估值17亿美元(约人民币120亿元)的独角兽。而它仅仅成立一年。
其凭借构建的全球最大规模的用户偏好大模型实时数据集,来满足市场对AI可靠性评估的迫切需求,而这也让LMArena在资本市场上获得高度认可。
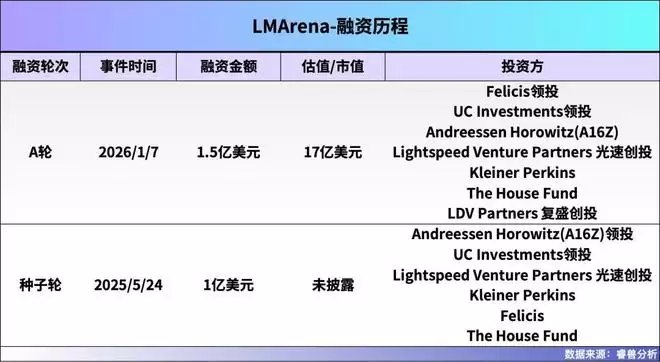
在短短一年时间内,LMArena完成了由Andreessen Horowitz(a16z)、Felicis Ventures等顶尖风投领投的两轮融资,包括种子轮1亿美元,A轮1.5亿美元的资金。
然而,其商业模式的可靠性正面临争议。一个搞AI测评的初创公司,凭什么跃升成为独角兽?


学术机构里跑出来的创业公司
LMArena脱胎于大型模型系统组织(Large Model Systems,LMSYS )。该组织起源于2024年,由加州大学伯克利分校、斯坦福大学、加州大学圣地亚哥分校、卡内基梅隆大学等多所大学合作发起。它于2024年9月注册为非营利性公司,旨在孵化早期开源和研究项目。
也是在2024年,一起在加州大学伯克利分校电子工程与计算机科学系攻读博士学位的Anastasios N. Angelopoulos和Wei‑Lin Chiang,受LMSYS资助,创立了Chatbot Arena,这即为LMArena的前身。
作为一个学术附属项目,Chatbot Arena拥有一个较为纯粹的初心:构建一个公开透明的评估平台,它能够真正地反映大型语言模型在现实世界中的应用情况。
大家都知道,我们日常使用的生成式人工智能所依托的大模型需要不断地被训练,而人们在使用过程中真实的使用体验和建议,可以最大程度地帮助大模型提升回答质量。“哪些人工智能模型对我来说最好用?” 作为用户,你也许也有这样的疑惑。
2024年5月,Chatbot Arena被正式推出。Chatbot Arena平台上会展示不同人工智能对同一问题的回答,每个用户都可以通过匿名的方式选择自己更喜欢的答案,对不同的人工智能模型进行投票。
2025年1月,Chatbot Arena注册为商业化实体LMArena,由Anastasios N. Angelopoulos任首席执行官、Wei‑Lin Chiang任首席技术官,Ion Stoica是联合创始人兼顾问。

Ion Stoica(左)Angelopoulos(中)Chiang(右)
三个人可谓强强联合。
Ion Stoica是UC伯克利大学的计算机系教授,同时领导着该校的天空计算实验室((SkyLab)。他还是位连续创业者,先后参与创办了Anyscale、Databricks、Conviva Networks等公司。
Angelopoulos 对于可信赖的人工智能系统、黑箱决策和医疗机器学习方面的研究颇深,他曾在谷歌 DeepMind 担任学生研究员,并计划在Stoica 那里开始博士后研究,专注于在高风险环境下评估人工智能。
Chiang则同样是在 Stoica 领导的天空计算实验室研究分布式系统和深度学习框架,此前曾在谷歌研究、亚马逊和微软从事研究工作。
目前,LMArena已经吸引了数百万参与者,截至2025年4月,已记录超过300万次比较,评估了400多个模型,其中包括商业化的GPT-4、Gemini、Bard以及开放权重的Llama和Mistral模型,很大程度帮助了用户以及企业理解这些模型的能力和局限性。
通常而言,大模型是基于互联网上开放的可用数据进行训练的,而大多数大模型基准测试也都是静态的。如果模型通过“记忆”污染数据就能在基准测试上获得高分,那么大模型的研发团队可能会过度优化模型以拟合这些有缺陷的指标,而非提升其实用性和解决真实世界问题的能力。这就像学生为了应付考试而死记硬背,却忽略了真正理解知识。
所以,LMArena利用实时评估来缓解这个问题,通过持续不断地收到来自真实用户的新反馈来进行修正。这些反馈会被梳理成开放的排行榜和技术文章,为大模型的性能提供重要意见,指导LLM的改进和持续开发。此外,LMArena还与开源和商业模型供应商合作,将他们的最新模型投放到平台社区进行预测试,使得这些模型在正式发布前可以进行调整。
具体来看,其运作流程是通过用户在LMArena上操作,就像是在一个类似豆包、Chatgpt等生成式人工智能平台。用户可以提出问题,平台则通过大模型生成两个不同风格或者版本的答案,用户可以在答案下方的反馈区对更偏好的答案进行选择“左边更好”、“右边更好”、“平局”、“都不好”。
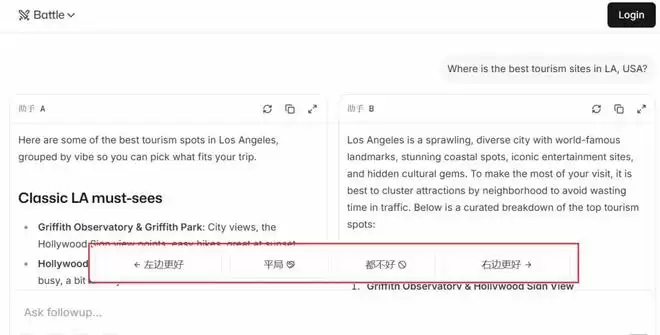
图:Chatbot Arena界面
但是这样的一个平台,在人工智能领域似乎“技术含量”并不高。它靠什么一年内完成两轮融资跃升为估值17亿美元的独角兽?

做人工智能领域的评估者
在人工智能应用渗透进日常生活的时代里,如果说AI本身的运行性能决定了它能跑多快,那它生产出来的内容是否值得被信赖,则决定了它能走多远。
“这就是我们为什么投LMArena的理由”,位于硅谷的著名风险投资基金 a16z合伙人Anjney Midha说到。LMArena的两轮融资中都有a16z的身影。
在Anjney Midha看来,当模型变得足够可靠,无疑会给各行各业带来颠覆性的效果。比如医院可以信任大模型的诊断结果、法院也可以信任大模型的分析裁判结果。而目前政府机构也已经开始参与到可靠性的人工智能领域中来,受监管的行业也在试点部署。
所以,行业的需求信号已然很清晰——对于要运行重要领域内容的人工智能而言,中立客观的评估必不可少。
而这样的需求便是一个巨大的机会。如果大模型的“实战检验”未来可以成为人工智能领域的权威认证,那么LMArena目前已经构建的规模最大、基于人工智能输出的人类偏好实时数据集,则无疑将成为其在人工智能评估领域的先发优势。
投资人的钱总会流向更可能带来更大回报的项目。LMArena最近的A轮融资,由知名的风投机构Felicis Venture和UC Investments(加州大学投资部门)共同牵头,a16z、The House Fund、LDVP、Kleiner Perkins、Lightspeed Venture Partners和Laude Ventures也参与其中。
而在去年5月份的种子轮融资中,该公司筹集了1亿美元,由a16z和UC Investments领投。

“AI测评生意”够可靠吗?
目前,市场上对大模型做测评的企业数量并不少。从测评榜单这种形式来看,AI大模型排行榜呈现出“各司其职”的多元格局,每家有自身的特色。
LMArena被誉为业内的“黄金标准”或“人气榜”,其核心在于利用用户参与这种众包形式,人类主观偏好明显。它采用匿名双盲测试,让用户在不知模型身份的情况下对话并投票,再通过类似国际象棋的Elo系统进行排名。这种方法最直接地反映了各个模型的综合用户体验和对话流畅度,但可能更偏爱回答风格“讨喜”的模型。
与之形成鲜明对比的是由学术界推动的LiveBench,其背后平台由图灵奖得主、Meta首席AI科学家杨立昆(Yann LeCun) 联合Abacus.AI、纽约大学等机构共同推出的。Abacus.AI 是一家人工智能及机器学习研究商,它帮助LiveBench成长为一个每月更新的“防作弊系统”。其排名依据全部来自最新的数学竞赛、Kaggle数据集或arXiv论文,且有标准答案,旨在从根本上杜绝模型通过记忆旧数据“刷分”,专门检验模型在陌生问题上的真实推理和泛化能力,因此被视作衡量LLM模型“硬实力”的试金石。
此外, OpenRouter Rankings直接基于平台上的实际API调用量进行排名。OpenRouter的商业模式可以概括为“聚合调度+增值服务”。它本身不研发模型,而是作为一个中间层,整合了来自60多家供应商的400多个AI大模型(包括OpenAI、Google、Anthropic等主流厂商以及众多开源模型),然后通过统一的API向开发者提供服务,收取5%-5.5%的服务费 。其发布的模型用量排行榜在开发者和投资圈内也备受关注。
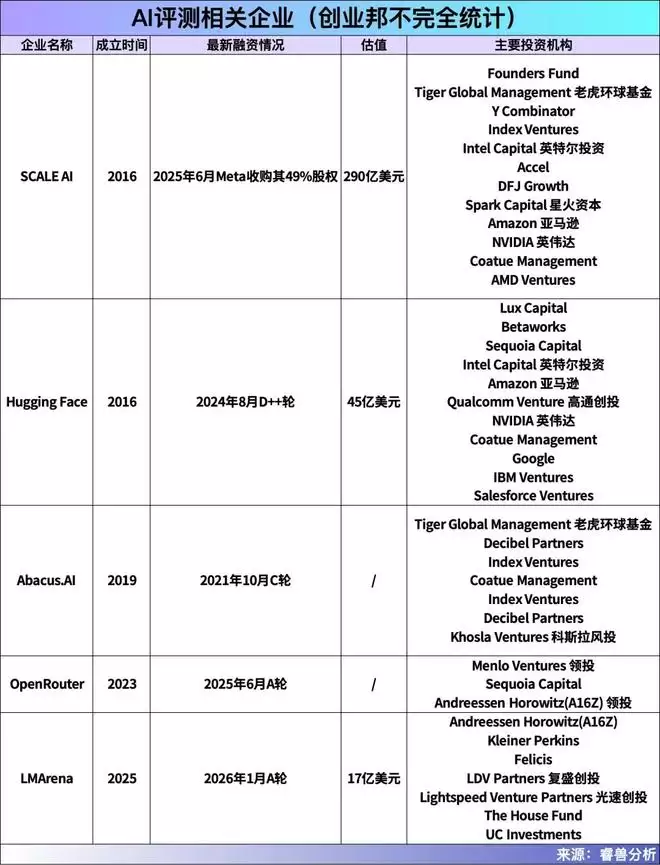
除了这些美国企业开发运营的国际榜单,还有像OpenCompass(上海人工智能实验室2024年12月开源)、SuperCLUE这样的国内榜单,它们重点关注模型在中文理解、文化背景及符合国内法规方面的能力,为本土化应用提供了关键参考。但是这些榜单大多是由政府研究机构和高校和在线社区主导,相对而言,中国在对LLM大模型评测方面的商业化程度较为空白。
回到LMArena本身的运作模式来看,其测评内容的可靠性其实本身也有诸多争议。
美国的数据标注公司Surge AI质疑LMArena的运作,称其完全依赖于不受控制的志愿者在平台上进行的游戏化劳动——随机的互联网用户花两秒钟快速浏览一下,然后点击他们最喜欢的答案。而实际上,这些用户自身并没有任何动力去认真思考作答。没有质量控制下的大模型系统打分能做到准确有效吗?
比如,针对一个关于蛋糕模具的数学问题,LMArena生成了两个答案供用户选择。但最后,用户投票支持了一个数学上不正确的答案,因为这个答案看起来似乎“更合理”。

图:LMArena的投票者奖励错误的数学计算
而LMArena的领导层也曾在公开场合谈到,他们采用了各种方法来克服用户输入数据质量低下的问题。他们承认,用户更喜欢大模型生成的带有表情符号和冗长的内容,而不是实质性高质量的内容。所以这种测评模式很可能无法真正筛选出能生产高质答案的大模型。
LMArena此轮融资虽猛,但是当潮水褪去,是否能留在牌桌上,还有待时间观察。
相关攻略

北京商报讯(记者 陶凤 王天逸)3月29日,无界动力对外宣布,夏中谱正式加入公司,担任联合创始人兼联席CTO,全面负责世界模型原生具身智能多模态大模型研发,以及数据闭环、云端仿真等核心技术基础设施建

(来源:麻省理工科技评论)好奇心驱动的研究长期以来一直是技术变革的火种。一个世纪前,对原子的好奇催生了量子力学,并最终孕育出现代计算核心的晶体管;反过来看,蒸汽机是一项实用的突破,但人们在热力学领域

henry 发自 凹非寺量子位 | 公众号 QbitAI“这笔钱只有一个目的:不再只做demo。”刚刚,由斯坦福具身智能明星赵子豪(Tony Zhao)迟宬(Cheng Chi)创立的机器人公司Su

作者丨巴里编辑丨吴岩图源丨镜识科技2026开年,镜识科技创始人王宏涛深夜风尘仆仆地赶到北京,第二天要去见几个合作伙伴。他是浙江大学求是特聘教授、国家杰出青年基金获得者,如今也是镜识科技的联合创始人。

南方财经两会报道组 张雅婷 北京报道3月6日下午,十四届全国人大四次会议广东省代表团举行开放团组活动。全国人大代表、小鹏汽车董事长何小鹏会上表示,一个企业要发展,最重要的是人才在哪里。招到特别好的人
热门专题







热门推荐

洛克王国世界40级进阶无推图阵容打法攻略 在《洛克王国世界》的成长之旅中,达到40级是一个关键的进阶门槛。许多玩家可能会发现自己并未刻意组建一支成型的推图队伍,面对这个挑战时有些无从下手。这篇攻略将为你详细解析一套无需专门推图阵容的通关思路,帮助你利用现有资源,轻松突破40级进阶关卡。 核心阵容搭配

这城有良田主C僚属红品宝玉词条搭配攻略 在《这城有良田》中,红品宝玉的词条选择,是决定你主C僚属最终伤害上限的核心环节。面对各式各样的属性词条,不少玩家会感到困惑:如何搭配才能最大程度激发核心输出的潜力?本文将为你系统解析主C位红品宝玉的挑选逻辑与进阶策略,助你在资源投入上实现收益最大化,显著提升队

哔哩猫手表版优化指南:适配小屏的关键设置 想在智能手表上流畅体验哔哩猫?直接安装手机版本,往往会遇到界面拥挤、操作不便的问题。其实,只需调整几个核心选项,就能让哔哩猫完美匹配手表的小屏幕,操作体验大幅提升。 1、DPI优化:精准调节显示密度 手表屏幕空间有限,默认的显示比例常常导致文字过大、布局浪费

《深海迷航冰点之下》咖啡机使用全攻略:生存必备热饮制作指南 在《深海迷航冰点之下》这片危机四伏的极地海域中,新手面临的第一个致命威胁往往是持续不断的体温流失。与前作不同,身体失温在游戏前期是核心生存挑战之一。有效应对失温的方法主要有:尽快解锁并制作抗压潜水服的升级模块——防寒服、靠近能提供热源的炽热

三国志王道天下吕布骑阵容玩法攻略 在策略手游《三国志王道天下》中,构建强力阵容是核心乐趣。以飞将吕布为核心的群雄骑兵队,以其惊人的爆发力与爽快的操作体验,备受玩家关注。本攻略将为你详细解析这套阵容的构建精髓、核心机制与实战搭配思路,助你打造一支所向披靡的突击铁骑。 阵容构成 这套阵容以纯粹的群雄阵营