OpenAI警示AGI近在咫尺,GPT-5能力已超越人类天花板

免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
新智元报道
编辑:元宇
【新智元导读】如同智能手机一样,大模型也进入了一个「能力过剩」时代,即大模型本身的能力与人类使用方式之间存在着巨大断层。
刚刚,GPT-5.2刷新了一项新纪录!

OpenAI联合创始人Greg Brockman发帖称使用GPT-5.2在ARC-AGI-2基准测试上,表现超过了人类基线水平。
在基准测试时技能爆表,但一到实际应用就「掉链子」,OpenAI前首席科学家Ilya Sutskever提到的这种大模型「性能悖论」我们并不陌生。
这也是AGI评估领域一个长期存在的难题——如何区分大模型「真正的推理能力」与「刷题型能力」。
而ARC-AGI-2的出现正好打破了这一难题。
ARC-AGI-2的全称为「Abstraction and Reasoning Corpus for Artificial General Intelligence-Version 2」,是ARC系列基准的最新升级版本。
该基准由François Chollet(Keras之父、前Google Brain研究员)及其团队在2025年推出,其设计初衷十分明确:
测试AI是否具备AGI所必需的抽象、归纳与迁移推理能力,而非记忆或统计模式匹配。
ARC系列与传统NLP或多模态benchmark最大的不同在于:它没有大规模训练集,每道题目都是从未见过的新任务,因此不存在通过「刷数据」获得高分的可能。
它要求AI像人类一样具备真正的推理和举一反三的能力。
Chollet曾多次公开表示,如果一个系统只能在见过的数据分布上表现良好,那它并不具备AGI所需的能力。
因此,ARC基准测试刚好直击大模型的「软肋」。
从「及格」到「优等生」
一次关键跨越
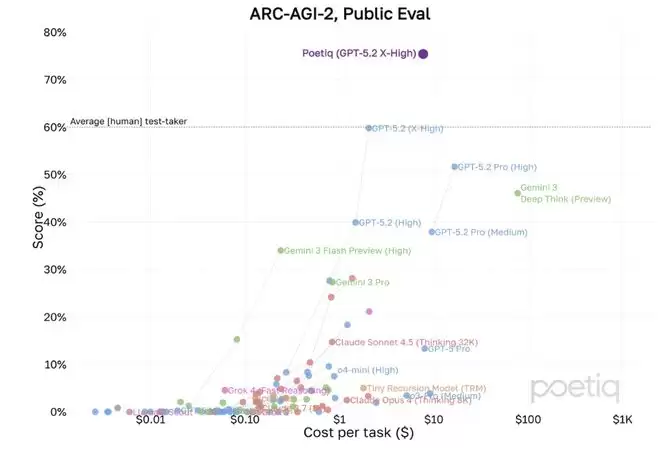
新纪录的刷新者,并非单一模型,而是一个名为Poetiq(GPT-5.2X-High)的系统。
Poetiq是一家专注于元系统(Meta-System)架构的AI公司。
其核心理念并不是训练一个更大的模型,而是通过软件层面的系统设计,自动构建「会调用模型的系统」。
Poetiq(GPT-5.2X-High)在ARC-AGI-2数据集上实现了75%准确率,每问题成本不到8美元,超越前SOTA 15个百分点。
在Poetiq(GPT-5.2X-High)系统出现之前,GPT-5.2(X-High)已经非常接近人类平均水平。
ARC-AGI-2榜单中,人类平均准确率约为60%,GPT-5.2X-High的成绩与之几乎持平,代表了当时AI在该基准上的最强推理能力。
但Poetiq的加入,使GPT-5.2(X-High)的得分从60%直接拉升到了75%,从勉强及格(人类平均水平)迈入了优等生的行列(显著超越人类平均水平)。
在同一榜单上,还能看到Gemini 3 Deep Think(Preview)的身影。
该模型主打「深度思考(Deep Think)」技术,在ARC-AGI-2上的成绩约为46%,明显落后于GPT-5.2系列,并且成本相对后者也略高。

Poetiq表示,整个过程没有对GPT-5.2进行任何训练或者特定优化。
这正是Poetiq元系统的初衷,旨在自动构建完整的系统,通过调用任何现有的前沿模型来解决特定任务。

从15%的提升数据来看,Poetiq对于基础模型性能的提升幅度还是非常明显的。
它的存在证明了不需要堆算力,通过优秀的软件架构也能大幅提升AI性能。
从这个角度上,它也验证了接下来OpenAI的一个判断——
当前大模型,正逐渐进入「能力过剩」阶段。
大模型「能力过剩」时代

就在同一天,OpenAI最新也在X平台发布了一项关于2026年的预测。
在这条推文中,OpenAI明确提到一个关键词:Capability Overhang(能力过剩)。
核心意思是:
当前模型「能够做到的事情」,与人们「实际使用AI的方式」(产生效果)之间,存在巨大的断层。
OpenAI认为,未来AGI的进展将不再仅取决于模型本身的突破,还将取决于:
人们是否知道如何有效使用AI
AI是否真正融入现实工作与生活
系统是否能将模型能力转化为实际价值
因此,在2026年,OpenAI将继续前沿研究,同时重点投入于应用层、系统层、人机协同,尤其强调医疗、商业和日常生活场景。
人机协同
AGI的另一半拼图
OpenAI这篇最新推文涉及一个人机协同的问题。
实现AGI,是需要模型和人协同发挥作用:AGI不只靠模型升级,更要「教人用AI」。
通过正确的使用AI,充分发挥出AI的潜能,这样才能让AI开始从「炫技」转向「普惠」,真正影响亿万人生活。
这一观点也得到了社区的强烈回应。
于是,乐观的网友称「直接把我整个人自动化吧」!
也有网友提到,真正的挑战在于如何将AI融入工作流程中:见过太多组织买了「AI」,却从未改变任何一个流程。
大模型真的「能力过剩」了吗?
那么,是不是真如OpenAI所说的,大模型的能力已经过剩了呢?
通过上面Poetiq所公布的Poetiq(GPT-5.2X-High)在ARC-AGI-2上的表现,75%的得分超过了人类平均水平(60%)15个百分点。
此前OpenAI最新在介绍GPT-5时强调其在解决复杂跨学科问题上达到了专家级基准,后被外界引申为「博士级智能」。
这说明GPT-5等大模型在某些专业任务中表现类似于人类博士的专业水平。
从模型本身来说,也许并未完全过剩,但从「未被充分释放的能力」角度来看,已经严重过剩。
其中,有模型设计者方的原因,比如他们没有紧跟用户的使用场景,「不再与用户并肩同行了」。
也可能由于前沿模型在推理和创新上缺乏根本性的突破。

还有模型本身迭代得太快,用户不得不在日常生活中不断弃用已经「成功上手」的模型。
Poetiq 的出现,以及OpenAI对「能力过剩」的判断,共同指向了未来AI领域的一个新方向:
下一阶段的AI竞争,不再只是模型参数之争,而是系统、流程与人机协同的竞争。
参考资料:
https://x.com/poetiq_ai/status/2003546910427361402
https://x.com/OpenAI/status/2003594025098785145
秒追ASI
⭐点赞、转发、在看一键三连⭐
点亮星标,锁定新智元极速推送!
相关攻略

提起大模型,许多人或许觉得它既神秘又遥远。实际上,我们可以将其理解为一个由海量数据“喂养”而成的超级智能大脑。其最核心的价值,在于其庞大的知识储备与强大的自主学习能力。 大模型的核心特点 首先,大模型拥有极其丰富的知识库。在训练过程中,它“阅读”了天文数字级别的文本、图像等多模态数据,涵盖从古籍经典

在人工智能技术飞速发展的当下,大语言模型正深刻改变着我们与信息交互的方式。作为实现模型精准化应用的核心步骤,全量参数微调技术的重要性日益凸显。这项技术听起来专业,实则是将通用AI模型转化为领域专家的关键桥梁,直接影响着模型在具体任务中的表现与落地效果。 通俗地讲,全量参数微调是大模型训练流程中的“专

在人工智能技术快速发展的今天,如何让AI大模型在面对未知数据和全新场景时,依然保持出色的性能与稳定性,已成为推动AI真正落地应用的关键。模型的泛化能力直接决定了它是只能应对特定任务的“实验室模型”,还是能够适应多变环境的“工业级解决方案”。本文将系统性地解析提升AI模型泛化能力的核心策略与实践方法。

最近研读了一篇关于企业AI数据安全落地的学术论文,题为《Positive Data Control: A Secure Architecture for LLM-Mediated Data Governance》。该论文深入探讨了一个关键议题:当用户使用自然语言向数据库发起查询时,如何确保大语言模型

随着人工智能大模型在各行各业的深度应用,一个核心的伦理与技术挑战日益凸显:如何构建更公平、更无偏的AI系统?问题的症结,往往深植于其训练数据之中。数据偏见如同隐匿的瑕疵,若不系统性地识别与清除,最终将损害模型的公正性与可信度。因此,建立一套科学、可操作的AI数据偏见识别与纠正方法,已成为开发负责任人
热门专题







热门推荐

据传REDMI正研发一款配备7英寸2K大屏与超10000mAh电池的手机。该产品旨在融合巨屏显示与超长续航,兼顾通信、支付等基础功能,并拓展至办公、阅读、影音等多场景应用,试图在便携与实用间寻求新平衡。此举或填补高端安卓大屏市场空白,重新定义巨屏手机体验。

河南省科学院召开“十五五”规划咨询会,18位两院院士线上线下共商发展蓝图。会议总结“十四五”在机制、人才、平台及成果等方面成效,明确未来五年将聚焦特色领域、深化科产融合、加强人才培养与重大设施建设,致力建成全国一流新型研发机构,支撑区域创新发展。

科学家唐立梅兼具深海与极地科考经历,近期转型短视频科普。她发现严谨表达未必受欢迎,情感共鸣内容反而更易引发关注,流量规律令其困惑。尽管难以把握算法,她仍坚持每条视频必须承载扎实的科普价值,并依靠年轻团队适应传播环境。

知情人士透露,虎鲸文娱旗下AI写真应用妙鸭相机核心团队已于去年9月底解散。该产品去年7月上线后曾迅速走红,用户支付9 9元即可生成数字分身制作写真。目前产品已停止更新与推广,仅维持基础运营。其从爆红到解散的短暂历程,为AI应用的商业可持续性提供了反思案例。

特斯拉在柏林工厂内部使用自动驾驶系统完成约15万公里短途转运,替代人工挪车。闭环测试环境提升了生产效率和空间利用率,展现了人工智能在工业流程中的实际应用。