数据采集5大陷阱:训练前标注已注定模型成败,如何破解?
衡宇 发自 凹非寺
量子位 | 公众号 QbitAI
“我们只交付100%可以复现的轨迹。”
具身智能创企鹿明机器人媒体沟通会上,联席CTO丁琰对具身智能数据采集现状、困境,以及最新兴的采集方式UMI作了前沿的深度分享。
他在分享中反复强调,很多团队以为具身模型训不出来是卡在训练阶段,实际多数问题在数据生成的起点就已经埋下了。后面再堆模型、堆算力,只是在给错误输入继续加速。
丁琰的履历能解释他为什么会把“数据的可训练性”看得这么重。
他的研究方向是机器人学与具身智能,2024年3月从美国纽约州立大学计算机学院博士毕业。去年年底加入鹿明之前,他做过一星机器人的CTO,更早则在上海AI Lab担任研究员。
按他的说法,从2024年3月起,他就持续投入UMI方向,是大陆最早做UMI方向的人。

UMI全称叫Universal Manipulation Interface,最早来自斯坦福在2024年2月提出的一套工作。
其核心是用与具体机器人本体解耦的方式,记录人类在真实物理世界中的操作行为,把“操作意图+运动轨迹+多模态感知”统一到一个通用接口里,供不同形态的机器人学习和复现。
在去年9月之前,UMI还是一个偏冷门的方向。
具身智能进入下半场后,数据的重要性与日俱增。
丁琰分享道,前段时间有人归纳了具身智能在解决数据难题时的四种解法。
遥操作数据,最著名的代表是智元机器人。仿真数据,代表公司是银河通用机器人。人类视频数据,它石智能就是这种解法的代表。UMI,去年9月开始冒头,鹿明就是代表性公司。
鹿明基于现实需求,做出了一个名为FastUMI Pro的产品,这是一个无本体数采硬件。
系统适配市面主流机械臂和夹爪,机身重量在600多克量级,但能夹起两三公斤物品,场景覆盖工厂与家庭。
它还支持多模态输入,包括触觉、听觉、六维力等。
在UMI设备最核心的空间精度上,丁琰称FastUMI Pro的1mm是“全球最高精度”。

硬件产品背后,还有鹿明布局的数据采集、模型训练生态。
以“可复现”作为第一性原理做数据治理,丁琰带领团队建立了8道工业级数据质量评估体系,并承诺只交付100%可复现轨迹。
(以下为丁琰分享的关于具身行业数采、UMI等相关内容,在不改变原意的基础上作了编辑调整)
具身数采的现存痛点
2024年3月起,我就开始在做UMI,应该是大陆最早做这一块的人。
大家都知道,具身智能最关键的就是数据,海量的数据是训练的一个必经之路。
但是数据现在有很多痛点。
第一个痛点就是成本,成本异常高昂。
美国那边,为了采集一个小时的训练数据,大概要付出100-200美金的成本。
现在的具身模型都还很小,PI 0的训练数据大概是1万个小时,Generalist的GEN 0是27万个小时。这个规模对比GPT-3的训练数据,还是非常小的。
我们做了一个统计,大概相当于7.9亿个小时的数据,才能在具身智能界训出一个GPT-3规模的模型。按照现在的市场价格,需要耗费数百亿美金。

另外,具身数据整体采集效率还是比较低的。
2024年到2024年左右,业内都是以遥操为主,一个小时大概能采集35条数据,效率异常低,成本也不可控。
遥操还有个问题是什么呢,就是采集时,因为摄像头记录的是机械臂本身的运动轨迹和画面,但每家机器人长得又都不一样,所以用A机器人做遥操作采集的数据是很难很难用到B机器人上的,这就产生了数据孤岛问题。
大家重复造轮子,也会造成高昂的隐形成本。
这是我们想解决的关键问题所在。
用UMI数采,你为什么训不出来模型?
前段时间我写了一篇小红薯,题目叫《你为什么训练不出来UMI的模型?》。
我想就这次机会简单跟大家介绍一下UMI行业的现状。大家可能看到的更多的是冰山的一角,但浮在水下面的一个世界还是比较深的。
一个很明显的现状就是什么呢?
做UMI的人陆陆续续越来越多,但是训出来模型的异常的少,可能一只手都数得过来。
很多UMI设备涌现出来,大家都会强调自己低成本、能即插即用、快速部署,但是基本上你看不到什么成功的案例,就这个是非常非常有意思的现象。

国外有两家比较知名的公司,一个叫Sunday,一个叫Generalist,他们还是训出模型了。
国内目前我们觉得训模型训得比较好的一家就是我们,再有就是清华一家,上交一家,总共也就两、三家能训得出来。
大多数情况下,要么训不出来,要么即使是在相似的条件下能跑出来demo,时间也非常短,可能就3、4秒,也很卡顿,不丝滑。
关于为什么大家用UMI采集出来的数据训不出模型,最常见的解释是“算法不是很成熟”“模型不够大”“数据规模不足”,但是其实这些解释都不是真正的原因。
真正的原因根本不在于训练阶段,而在于训练之初它就不是太对——
大量的UMI数据从生成开始就不具备进入训练管线的这个条件。
说白了就是数据不合格。

什么是可以训练的UMI数据
大家会有误解,总觉得UMI数据就是人拿个夹爪,就把这个视频数据记录下来就行了,非常非常简单,所有人都可以做。
其实完全不是。
UMI其实是AI对物理世界的理解对齐,并且在这个物理空间里面可以复现的这种交互行为。
它必须满足几个条件。

拆开了讲,第一个就是说画面要跟动作要严格对齐,要跟空间位置严格对齐;另外一个就是说因为UMI可以集成多个传感器,每个传感器之间也要做到毫秒级的同步。
举个例子,一个人想去拿眼前的一瓶水,不对齐的话得反应好几秒,水就可能拿不起来。
另外,一个好的轨迹必须可以在物理空间运动中可复现的。
本质要求是希望UMI采集的数据是高一致性的、高密度的,并且可复现的时序数据结构。
为什么大多数UMI设备采不到好的数据?
现在大量的UMI设备采不出满足条件的数据,两个根本原因。
一,核心问题是硬件能力完全不够。
UMI的CMOS组件或者主控芯片,性能非常差。
导致的结果就是画面覆盖有限,画质不怎么好,曝光也不怎么好,帧率比较抖动,这时候画面就非常糟糕。
它破坏了动作和视觉的因果关系。本来模仿学习就是我看到什么画面就做什么动作,结果画面和动作完全无法对齐,就会导致这个模型根本没办法学习。

二,市面上很多产品不是系统设计的,而是很多现成模块拼凑起来,用USB Hub连接的。
这样一来,产品的贷款架构非常脆弱,每个模块都会抢带宽。一旦有什么负载,就会出现掉帧等一系列问题,所以数据的质量就非常糟糕,基本没办法稳定复现交互记录。
也就是说,从硬件层面讲,这些设备从一开始就没办法训出模型需要的数据。
“脏数据”和“废数据”
但即使设备好了,采的数据能不能训出数据也不是一定的。
举个例子,别人拿到我们的设备,也不一定能训出好的数据。
为什么呢?这就要说数据的质量高低了。
数据质量的高低其实并不是干净程度,而是说有效的信息密度。
低质量的数据,包含大量抖动、漂移、时间错位,非常不利于学习。特别是在单视角情况(很多UMI是单个机械臂),这种噪声不会因为你的数据量增大而被平滑掉,所以说你学出来的策略会非常非常糟糕,基本上训不出来。
低价值数据不是完全没有价值。
它还是有点价值,可以去认识这个世界,知道什么是杯子,什么是麦克风,但没办法从它身上学习到精确的物理交互信息。
它不知道桌上的麦克风我是怎么拿到的,我到底该正着拿还是反着拿,还是需要倾斜角度去拿。
除了低质量的脏数据,我还把一种数据叫“废数据”。

废数据是什么?
就是很多人拿着设备直接去众包去采集了,人怎么采就拿它怎么采。
这种数据完全copy人类的自然行为,没有任何设计和技巧,过于“天然去雕饰”了,基本上是不可能训出来模型的。
现在都在做的叠衣服,其实是最需要采集技巧的一个任务。叠衣服的时候要抖一下,抖的过程中还要注意方向、速度,才能抖好。
但人在叠衣服的时候,很少会注意那么多tricks。
每家具身公司都有自己的采集技巧,所以如果没有注入任何技巧,即便拿到很好的UMI设备,采集的数据很像人的行为,但其实是废数据,基本上模型训练不了。
能当然可能未来,十年、二十年,模型发展好了,这些数据可能就有用了。但目前很长一段阶段这些数据基本上训不了,所以称为废数据。
硬件、数据和算法环环相扣
正确的UMI的工程范式首先是一种系统的自洽,而不是一种简单的功能拼接。
传统的路径下面大家做机器人,首先有个硬件,硬件弄完了之后再弄软件,弄完软件我再弄算法,我反过头来我再去补点数据,把这个整个loop给跑通。
但在UMI这个很特殊的场景下,这个范式是失效的。
因为UMI是一个强耦合系统,数据会决定整个模型的性能,硬件会决定这个数据的质量;数据又会决定这个算法的性能,算法又会反向去约束我这个硬件的执行和这个数据的设计。
硬件、数据和算法环环相扣,任何单点的这种失效都会导致训不出优秀的模型。

关于UMI,团队做了什么
博士毕业后,我从2024年3月就开始在做面向UMI的工作。
去年9月之前,UMI在行业里还是比较冷门的,除了我和我的团队基本没人做。
当时我们就有一个愿景,希望能打破这个数据获取的这个不可能的三角,把非常高质量的数据砍到白菜价,加速应用来推进这个整个具身智能行业的发展。
这里跟大家分享我和团队近两年的一些典型工作。
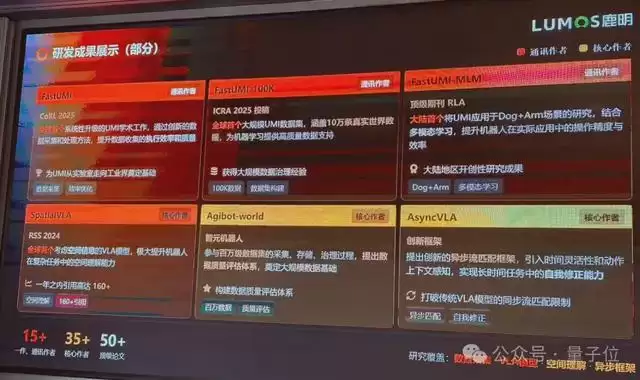
首先就是FastUMI,我是这篇工作的通讯作者。
FastUMI应该是全球首个将学术界(UMI,斯坦福,2024年2月)的工作升级成工业级别系统,然后推进它进入工业的。我们从2024年3月左右开始做这个工作,在7、8月左右完成,当年的9月中了CoRL 2025。
FastUMI主要解决的问题是提高采集效率和数据质量。
另外一个工作是FastUMI 100K。
在有了一个很稳定的软硬件系统后,我们开始扩大规模去采数据。当时我在上海AI Lab建立了一个数采长,我带着11个人在3个月时间里,采集了10万条真机数据,为机器学习提供了非常高质量的数据支持。
这是全世界首个大型的UMI数据集。
从这个工作中FastUMI团队获得了大规模的数据治理的经验。
我们还有一个工作叫Fastumi-MLM,它把UMI这项技术用于“狗+臂”。
之前UMI都应用在单臂、双臂或者轮式双臂工作上。这是大陆第一个能将UMI用在这种构型机器人上的工作。
除此之外,还有Spatial VLA、Agibot World、AskVLA等等。
相关攻略

数智时代,领导形象在透明环境中被全方位记录与解析。传统“形、象、道”理论面临挑战,微表情、决策等数据流可被传播甚至篡改。抓拍照片可能引爆舆论,算法茧房扭曲真实意图,数字原住民追求真实性,使精心构建的形象显得脆弱易碎。

Matrix 是一种开放且去中心化的即时通讯协议,允许用户自主部署私有服务器并接入全球 Matrix 联邦网络。OpenClaw 网关通过集成 Matrix 的 Client-Server API,实现与这一分布式通信生态的无缝对接。 前置准备 在配置 OpenClaw 连接 Matrix 之前,请

周二晚间,AI领域迎来了一则重磅消息。在权威AI评测平台Artificial Analysis的榜单上,一个名为「HappyHorse-1 0」的神秘模型异军突起,一举登顶视频生成能力排行榜,引发了业界的广泛关注与热议。 这一成绩极具含金量。无论是文本生成视频,还是图像生成视频,HappyHorse

当AI开始学会“脑补”物理世界的运行规律,并尝试模拟一个动态变化的真实环境时,我们距离那个传说中的通用人工智能(AGI)究竟还有多远? 进入2026年以来,“世界模型”毫无悬念地成为了科技圈最炙手可热的核心议题。它标志着一个关键的范式转变:人工智能正从被动地“感知当下”,迈向主动地对时空与动态变化进

上周三关于“世界模型”的线上沙龙反响空前热烈,这充分表明,从被动感知迈向主动推演,这条被视为实现通用人工智能(AGI)的核心技术路径,正深度吸引着整个AI行业的关注。鉴于持续高涨的讨论热度,我们决定加开一场深度分享会。 那么,这条充满潜力却又极具挑战性的前沿赛道,目前进展到了何种阶段?顶尖的研究者们
热门专题







热门推荐

来看一组让人揪心的数字:截至5月28日,超过半数的委内瑞拉民众,选择支持经济“美元化”——他们想要用美元来对抗全球数一数二的恶性通胀。根据AtlasIntel的调研,31%的受访者明确支持美元化,另有26%的人表示强烈支持,加起来支持率高达57%;而明确反对或强烈反对的,合计只有30%。换句话说,在

游戏开局,玩家第一眼看到的主角是谁?没错,就是零。不过这里有个挺常见的误会——很多人会下意识觉得零是女主角,那是不是还有个男主角?其实不然。进入游戏之后,外观是可以自由选择的,性别、形象都由你定,男女主角本质上都是同一个人。两种造型唯一的区别就是视觉风格,至于基础属性、成长路线、技能体系,完全一致。

或许有人觉得,AI音乐生成工具不过是图个新鲜感,与专业音乐制作相距甚远。但5月28日,ElevenLabs推出的Music v2,很可能改变这一印象。这次升级版音乐生成模型,已不再停留在去年那个“新手友好”的初级阶段,而是在工作流、版权合规和落地场景上都做了充分布局。 一、核心进化:创作从“一次性生

iPhone20周年纪念款将采用四曲面屏与圆润边框设计,边框仅1 1毫米,但边缘亮度存在失真问题,苹果正与三星、LG合作解决。若无法攻克,可能沿用平面边框。该款预计2027年亮相,属于Pro系列,含双版本,并计划采用屏下前摄与FaceID。

对于技术从业者而言,面试备考始终是一个老生常谈却又不断变化的话题。时间碎片化、知识点庞杂、实战表达欠缺,每一项都可能成为关键时刻的瓶颈。有没有一种方法,能让我们把通勤、运动等零散时间充分利用起来,高效地“打磨技能”呢?今天要介绍的「播面」,或许就是一个值得关注的解题新思路。 播面是什么 简单来说,「