新年伊始,MIT CSAIL 的一纸论文在学术圈引发了不小的讨论。Alex L. Zhang 、 Tim Kraska 与 Omar Khattab 三位研究者在 arXiv 上发布了一篇题为《Recursive Language Models》的论文,提出了所谓“递归语言模型”(Recursive Language Models,简称 RLM)的推理策略。

图丨相关论文(来源:arXiv)
早在 2025 年 10 月,Zhang 和他的导师 Omar Khattab 就在博客上公开了初步想法,引发了一些关注。如今这篇正式论文带来了更系统的实验和更扎实的数据,论证了通过让语言模型把长文本当作“外部环境中的变量”来处理,可以让模型有效处理超出其上下文窗口 2 个数量级的输入。
Zhang 在推文中写道:“正如 2025 年是从语言模型到推理模型的转换之年,我们认为 2026 年将是递归语言模型的时代。”他还特别提到,RLM 是他们对推理时算力扩展(inference-time scaling)的“bitter lesson 式”解法,即与其精心设计复杂的人工规则,不如让系统自己去学、去算。RLM 的设计哲学与此一脉相承,它不试图从模型架构层面“修复”长文本处理的问题,而是提供一套通用的推理时框架,让模型自己决定如何与超长输入交互。
过去两年,几乎所有主流大模型都在竞相扩展上下文窗口。Gemini 把窗口拉到了百万级别,GPT 系列持续加码,Llama 更是喊出了千万 token 的口号。表面上看,这是一场“谁更能装”的军备竞赛。但问题在于,上下文窗口变大并不意味着模型就真的能把所有内容都“读进去、记得住”。
2025 年年中,向量数据库公司 Chroma 发布了一份技术报告,正式为这种现象命名,“context rot”(上下文腐烂)。Chroma 的研究团队测试了包括 GPT-4.1 、 Claude 4 、 Gemini 2.5 、 Qwen3 在内的 18 款主流模型,发现即便是在最简单的“大海捞针”(Needle in a Haystack,NIAH)任务上,模型的准确率也会随着输入长度的增加而显著下降。
更值得注意的是,当任务本身变得复杂,比如需要语义推理而非简单的字面匹配,性能下滑会来得更早、更陡峭。所谓百万 token 的上下文窗口,实际有效利用的可能只有一小部分。
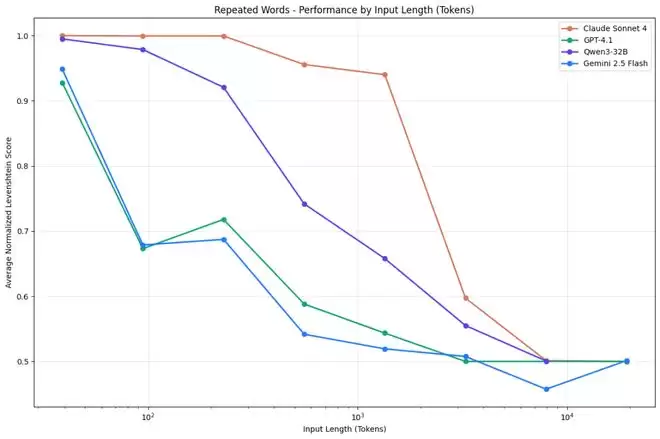
(来源:Chroma Research)
针对长上下文的解决方案目前业界已经发展出几种主流策略。最常见的是“上下文压缩”(context condensation),也就是当上下文超出一定长度时,让模型先对前面的内容做摘要,再继续处理新内容。这种方法简单直接,但摘要本身是有损的,早期出现的细节可能在压缩过程中丢失。
另一种流行方案是检索增强生成(Retrieval-Augmented Generation,RAG),先把长文档切块存入向量数据库,根据问题检索相关片段再喂给模型。这避免了让模型一次性吞下整篇长文,但效果高度依赖检索质量,对于需要综合全文信息的问题往往力不从心。
还有一类是递归任务分解框架,允许模型把复杂任务拆解成子任务再递归调用。但这些方法的共同局限在于:它们要么损失信息,要么无法真正突破模型本身的上下文窗口限制。
RLM 的核心思路在于换了一个角度来思考问题。与其绞尽脑汁让 Transformer 直接消化长文本,不如把长文本“外包”到一个独立的运行环境中,让模型通过编程的方式按需访问。具体来说,RLM 会启动一个 Python 的 REPL(Read-Eval-Print Loop,读取-求值-打印循环)环境,把用户的长文本作为一个字符串变量存进去。
然后模型不再直接阅读全文,而是编写代码来“窥探”这个变量,打印一小段看看、用正则表达式搜索关键词、按章节拆分等等。更关键的是,模型还可以在代码里调用另一个语言模型来处理子任务,并把结果存回变量中。整个过程是迭代式的:模型执行一段代码,观察输出,决定下一步怎么做,直到最终拼凑出答案。
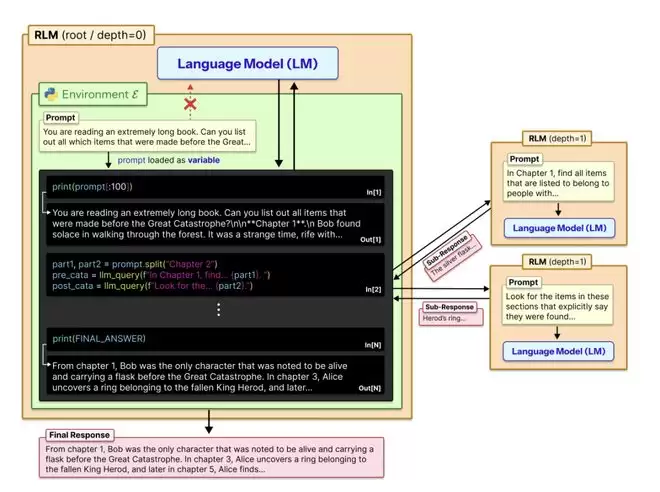
图丨递归语言模型将提示视为环境的一部分(来源:arXiv)
这种设计的灵感据称来自“外存算法”(out-of-core algorithms)。在传统计算机科学中,当数据量超出内存容量时,系统会把数据存在硬盘上,通过精心设计的调度策略来回读取需要的部分。RLM 本质上是在给语言模型搭建一个类似的“内存管理层”。对外部用户而言,RLM 的接口与普通语言模型完全一样:输入一个字符串,输出一个字符串。但内部的处理方式已经不同。
论文中的实验设计了 4 组不同复杂度的任务。S-NIAH 是最简单的大海捞针任务,答案固定,不随输入长度变化。OOLONG 要求模型对输入中的每一行进行语义分类并汇总,处理量与输入长度成正比。OOLONG-Pairs 更极端,要求找出满足特定条件的所有“用户对”,处理复杂度与输入长度的平方成正比。还有一组 BrowseComp-Plus,给模型 1,000 篇文档(总计约 600-1,100 万 token),要求回答需要跨文档推理的问题。
实验结果显示,裸跑 GPT-5 的表现随着输入长度和任务复杂度的增加而急剧下滑。在 OOLONG-Pairs 上,GPT-5 和 Qwen3-Coder 的 F1 分数都不到 0.1%。但套上 RLM 框架之后,GPT-5 的 F1 分数跃升至 58%,Qwen3-Coder 也达到了约 23%。
在 BrowseComp-Plus 的千文档场景下,RLM(GPT-5)取得了 91.33% 的准确率,而上下文压缩方案只有约 70%,检索工具代理是 51%。研究者还强调,RLM 的成本并不比直接调用基础模型贵多少,在某些任务上甚至更便宜,因为模型可以选择性地只查看需要的片段,而非一股脑把所有内容都送进 Transformer。
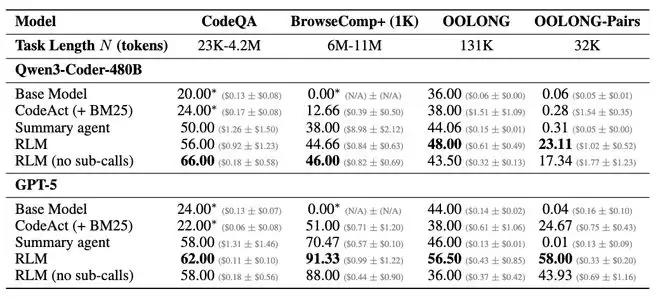
(来源:arXiv)
当然,任何新方法都有其适用边界。论文坦承,当输入较短、任务较简单时,直接使用基础模型可能比 RLM 更高效。毕竟 RLM 需要多次与环境交互,开销不可忽视。当前实现使用同步的、阻塞式子模型调用,端到端延迟较高,研究者认为通过异步调用和并行化还有优化空间。
此外,论文中的系统提示词是固定的,并未针对不同任务调优。另一个值得关注的问题是,让模型在 REPL 环境中自主编写和执行代码,在安全隔离和行为可预测性方面带来了新的工程挑战。
论文作者在文末提到,未来可能会出现专门针对 RLM 范式进行训练的模型,就像今天有专门针对推理任务训练的模型一样。他们认为 RLM 的轨迹本身可以被视为一种推理形式,理论上可以通过强化学习或蒸馏来优化。这个方向是否能走通,还需要更多后续工作来验证。
参考资料:
1.https://arxiv.org/pdf/2512.24601
2.https://research.trychroma.com/context-rot
3.https://x.com/a1zhang/status/2007198916073136152
运营/排版:何晨龙




