
机器之心发布
在大公司一路高歌猛进的 AI 浪潮里,小创业者和高校研究者正变得越来越迷茫。就连前段时间谷歌创始人谢尔盖・布林回斯坦福,都要回答「大学该何去何从」「从学术到产业的传统路径是否依然重要」这类问题。
AI,真的只是大公司的游戏吗?被算力掣肘的其他研究者、创业者,机会在哪里?在「强化学习」后训练引领「下半场」的当下,这个问题变得愈发重要。
好在,国内外都有专业团队在关心这个问题,比如前 OpenAI CTO Mira 创办的 Thinking Machines Lab,前段时间就推出了一个叫「Tinker」的产品,专注于解决后训练 Infra 的复杂性。
而在国内,一群由 95 后青年科学家组成的团队做出了足以对标甚至超越 Tinker 的竞品,成为世界第一家能够对标 Thinking Machines Lab 的公司
这个研究中心叫Mind Lab,是 Macaron AI 背后的实验室。1 月 1 日,他们发布了亮相以来的第一款产品——Mind Lab Toolkit(MinT)。这是一个用 CPU 的机器就能高效训练万亿参数模型的后训练平台,且成本优化了十倍,一天即可轻松完成一轮训练。此外,它比 Thinking Machines 更早实现了 1T LoRA-RL,是业界在万亿参数模型上进行高效强化学习的第一个成果。
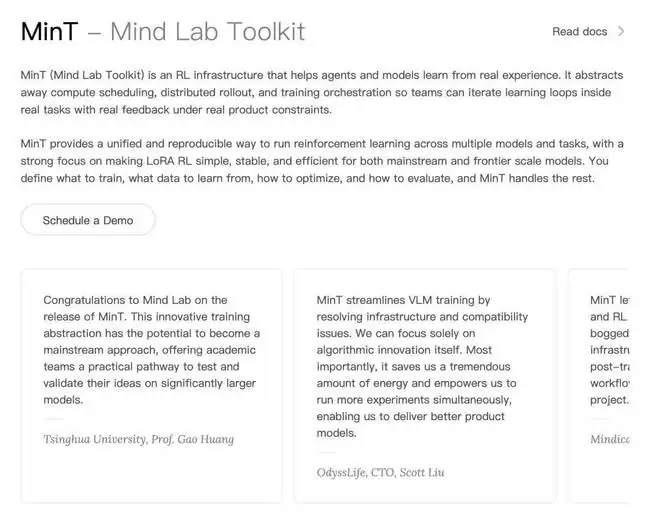
如果你是 Agent 领域创业公司或高校顶尖实验室的成员,并且被算力限制了想象力,那你将是 MinT 的首批受益者。它的应用场景涵盖基础研究到垂直行业的广泛领域,已经在圈内做出了一些成果。
细看一下,Mind Lab 的创始团队也堪称豪华。创始人 Andrew 毕业于 MIT,目前担任深圳清华大学研究院的研发中心主任,代表工作有和姚顺雨合作的 Agent 微调的经典工作之一 FireAct。
首席科学家马骁腾博士则毕业于清华大学自动化系,常年深耕强化学习领域。团队成员来自清华、MIT、CMU等高校,并有OpenAI、DeepMind、Seed 等顶尖实验室的工作经历。
团队累计发表论文超 100 篇,总引用量超 3 万次
这样一个团队打造的 MinT,正以极致的工程效率,将 AI 下半场的入场券交还到每一位研究者手中。
预训练时代结束
AI 下半场开启
过去几年,预训练一直是 AI 领域的主旋律 —— 更大的模型、更多的数据、更长的训练周期。
如今,这一阶段已趋于饱和:开源社区已经拥有万亿参数级别的模型,能够编写代码、总结文档、通过标准化考试。
但当这些系统被部署到真实产品中,新的瓶颈开始显现。模型一旦完成训练,参数就被 ' 冻住 ' 了,不停重复着相同的错误,也无法适应不断变化的用户需求,实际使用效果只能靠抽卡。
强化学习,正是破局的关键。
DeepSeek R1 的发布更是向业界证明,强化学习能够带来惊人的泛化性和样本效率 —— 模型不再只是 “记住” 数据,而是学会了在复杂任务中进行推理。
在 Gemini、DeepSeek V3.2、Kimi K2 等多个前沿模型的技术报告中都反复强调:后训练仍是一片蓝海,强化学习还没看到天花板。
2026 年的主旋律,是后训练。
后训练时代的基础设施
强化学习这么重要,为什么没普及?答案是:算法太复杂,训练太不稳定。
为了解决这个问题,前 OpenAI CTO Mira 创立的 Thinking Machines 发布了 Tinker,定义了后训练 API 的新范式,迅速获得美国学界和硅谷创业公司的热捧。
在 OpenAI 经历了 Sam Altman 被解雇又回归的内部动荡后,Mira 选择离开,并迅速组建了一支 “梦之队”—— 核心成员包括 OpenAI 前研究副总裁 John Schulman、Lilian Weng 等业界顶尖人才。资本市场对这家公司的追捧堪称疯狂。2025 年 7 月,Thinking Machines 完成了硅谷历史上最大的种子轮融资 ——20 亿美元,估值120 亿美元
他们押注的,正是后训练赛道。2025 年 10 月,Thinking Machines 发布了首款产品 Tinker,12 月面向所有用户开放。如果说 OpenAI 定义了大模型的推理 API 范式,那么 Tinker 定义的就是模型的训练 API 范式,让所有模型训练共享。
Tinker 已经获得了学术界和工业界的广泛认可,成为了硅谷和美国顶尖高校的训练新范式。
Mind Lab 与 MinT
国产后训练基础设施的崛起
Tinker 在海外大火的同时,国内也涌现出了对标甚至超越的力量 ——Mind Lab 推出的 MinT(Mind Lab Toolkit)。
Mind Lab 秉持 “From Static 'Brains' to Adaptive 'Minds'” 的理念,致力于让 AI 系统能够从真实世界的经验中不断成长。
在他们看来,当前大模型最大的问题是:训练完就 "冻住",无法从真实交互中持续学习进化。
MinT,正是为解决这个问题而生。
MinT 和 Tinker 是什么关系?可以从两个层面理解:
兼容性上,MinT 做到了模型够大够全、接口完全一致—— 与 Tinker API 完全兼容。这意味着使用 Tinker 的开发者可以几乎零成本地迁移到 MinT,享受国产基础设施带来的便利。
技术领先性上,MinT 不是简单的 “国产替代”。事实上,早在 2025 年 12 月 1 日,Mind Lab 就比 Thinking Machines 更早实现了 1T LoRA-RL,是业界在万亿参数模型上进行高效强化学习的第一个成果。
相关实现方案已经开源,并获得了Nvidia 最新转载
具体方案详见 Mind Lab 的技术报告:https://macaron.im/mindlab/research/building-trillion-parameter-reasoning-rl-with-10-gpus
MinT 解决了什么问题?
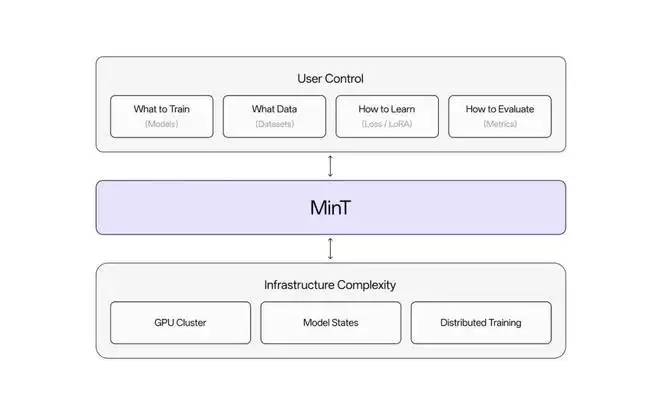
MinT 的核心价值可以用一句话说清:不论模型是1B还是1T,需要调度多少GPU,你只管数据和算法,基础设施的复杂工程全交给平台。
具体来说:用户只需在本地 CPU 机器上写几行 Python 代码,MinT 就会自动把计算任务分发到大规模 GPU 集群执行。集群调度、资源管理、容错恢复,这些让开发者和研究人员头疼的工程问题,统统由 MinT 搞定。切换不同的模型,只需修改代码中的一个字符串。
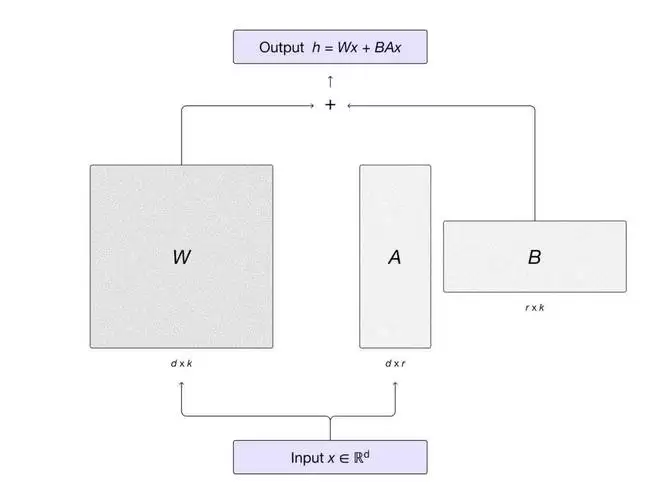
技术路线上,MinT 采用 LoRA 技术,使多个训练和推理任务可以共享同一计算资源池,从而显著降低成本。LoRA 在选择最优学习率的情况下,训练进程与全参数微调几乎完全一致,这为大规模高效后训练奠定了理论基础。
目前,MinT 已支持Kimi K2 Thinking(万亿参数级别的 MoE 推理模型)Qwen3-VL 系列视觉语言模型等前沿开源模型,并全面兼容 Tinker API。值得一提的是,MinT 还优先支持了π0 等具身 VLA 模型,这也体现出了中国公司在具身智能上的领先优势。
为什么需要 1T LoRA-RL?
强化学习被视为让大模型从 “背题” 走向 “推理” 的关键,但现实里有三大难题:训练不稳,小模型难以收敛,算力成本高。LoRA 提供了一条低成本路径,只训练少量低秩适配器即可显著提升下游任务表现,且在 RL/Agent 训练上几乎不损失性能。
Mind Lab 在 Kimi K2(万亿参数 MoE)上实现了端到端 LoRA 强化学习,带来三点突破
成本:仅用常规全参 RL 约 10% 的 GPU 资源,64 块 H800 即可完成训练。稳定性:奖励与任务成功率平稳提升,无灾难性发散;在 held-out 基准上既提升特定任务,又保持基座模型通用能力。系统:统一调度张量 / 流水线 / 专家 / 序列并行,针对 MoE 路由不均衡与通信压力做了专项优化。相关技术已贡献至 NVIDIA Megatron-Bridge 与火山引擎 verl 等开源项目。
为什么选择 MinT?
MinT 的产品设计围绕一个核心目标:把后训练和强化学习的门槛打下来。
验证成本上:MinT 允许开发者仅用 CPU 机器进行训练验证,告别配置 GPU 驱动和 OOM 的烦恼。这让团队可以在投入大规模 GPU 资源前,先低成本验证算法可行性。工程效率上:MinT 将采样、训练、回写与发布无缝串联,减少了工程拼装成本。并行策略、权重管理、optimizer state 管理、滚动训练、日志与可复现性等,都按工程标准打通。开发体验上:MinT 完全兼容 Tinker API,现有代码可快速适配,切换不同模型只需一行代码。目前已支持 Qwen、Kimi 等先进的开源大模型。迭代速度上:采用 LoRA-RL 技术让模型迭代周期从“按周” 缩短到 “按天”,真正服务于快节奏的产品开发需求。
谁是 MinT 最大的受益者?
第一批使用 MinT 的受益者,一定是 Agent 领域的创业公司和研究模型的高校顶尖实验室。
它们共同的特点是:掌握核心的数据和问题的设定。他们并非不了解前沿算法,而往往是被算力与训练框架难住了。
据 Mind Lab 正式介绍,目前 MinT 已经获得了顶尖高校和多个创业公司的认可,应用场景涵盖基础研究到垂直行业的广泛领域。
在学术机构方面:
清华大学人工智能学院黄高副教授团队(CVPR best paper 以及 NeruIPS best paper runner up 获得者)利用 MinT 开展了 RL 如何突破 Base model 知识边界的研究。上海交通大学副教授、上海创智学院全时导师蔡盼盼的 RoPL 实验室使用 MinT 在具身决策大模型和决策世界模型方面展开研究。
在行业应用方面:
硅谷创业公司Eigen AI合作探索运用 MinT 和 Data Agent 合成数据在 1T 模型上进行 agentic RL 训练。脑机接口公司姬械机利用 MinT 支持了他们的脑机接口 AgentBCI-Love,可以进行情感交互对话。瑞铭医疗利用 MinT 对医疗编码模型进行了基于 RL 的后训练,显著提升了医疗编码的准确率,并落地到数十家三甲医院
这些案例展现了 MinT 的通用性 —— 从基础研究到垂直行业,都能用。
中国团队引领后训练浪潮
如何让模型真正 “理解” 而非只是 “记住”,是众多创业团队与科研工作者共同面对的核心问题。强化学习被视为解决这一问题的关键路径,但其高门槛、高成本与不稳定性,长期限制了它在真实产品和中小团队中的落地。
2025 年,中国团队在开源模型上大放异彩。
2026 年,后训练将是中国 AI 弯道超车的下一个关键战场。
Mind Lab 选择了 LoRA-RL 这一技术路径,在超大规模模型上完成了万亿参数级别的探索与验证,再次证明了中国团队在前沿研究上的工程能力与原创实力。MinT 正是 Mind Lab 希望将这些研究成果系统化、工具化的产物 —— 让后训练和强化学习不再只属于少数头部机构,而是成为更多公司与实验室可以日常使用的能力。
这正是 Mind Lab 真正布局的方向:让先进研究转化为可用工具,让中国团队在模型后训练与强化学习这一关键技术浪潮中,实现自主可控。
可以访问以下链接了解更多:
Mind Lab 正式:https://macaron.im/mindlab相关文档:https://mint.macaron.im/doc