Jeff Dean:性能依旧至关重要的五大深层原因

新智元报道
编辑:倾倾
【新智元导读】很多人背着「过早优化是万恶之源」的名言,写出的却是处处漏风的代码。Google传奇Jeff Dean的这份笔记破了真相:性能不是最后调出来的,而是你在选第一个容器、敲第一行代码时,就已经注定的物理结局。
2025年,是个很容易让人产生错觉的时间点。
这时算力不再稀缺,云资源随叫随到,AI已经能写出准确无误的代码。
在这样的环境里,「性能」似乎正在悄悄贬值。因为代码写得慢一些,好像也没什么大不了。
就在这种氛围下,Google的传奇工程师Jeff Dean更新了一份老文档:Performance Hints。
比起一篇炫技的论文,它更像是一份老派工程师的随笔,里面重新整理了基础法则。
它反复重申一个事实:计算机底层的物理规则,从未因为云原生、AI或硬件的进步而改变。
硬件的进步掩盖了代码的低效,这些问题会在系统中不断堆积,直到成为无法绕开的成本。
「过早优化」,成了平庸代码的豁免权
所有工程师都听过一句老话:
Premature optimization is the root of all evil.(过早优化是万恶之源)。
它原本是提醒我们,别为了抠几行代码,把系统搞成一团乱麻。
但在实践中,这句话慢慢变了味,成了一个免责口令——只要遇到性能质疑,一句「别过早优化」就能把所有问题挡回去。
结果走向了另一个极端:写代码时,性能被整体忽略。抽象可以多一层,数据可以多拷贝一次,API可以写得更「通用」。
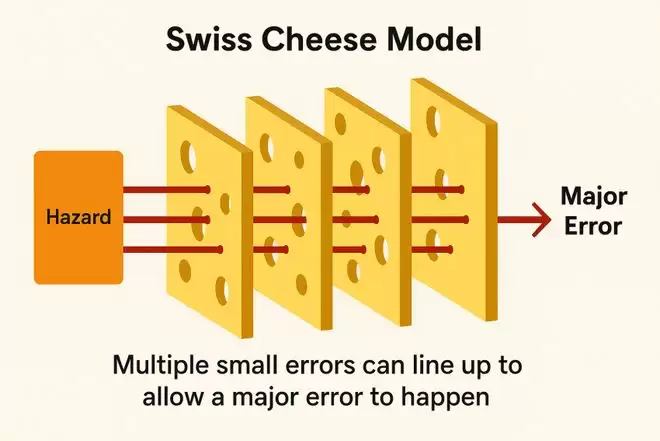
瑞士奶酪模型:单个小漏洞没事,但是一层层叠加,对齐了会出大事
大家总觉得将来有profiler,等真慢下来再说。
可等系统上线,流量涌入,响应开始变拖沓,大家终于打开性能分析图,却发现屏幕上什么都没有。
没有一个函数占掉40%的时间,没有明显的性能热点。你看到的只有一张异常平坦的火焰图——每一层都慢一点,每一个看似无关紧要的选择,都给未来埋下隐患。
你很难指出哪里出了错,因为问题从一开始就没有集中出现——这正是Jeff Dean反复强调的一种模式。
性能不是被某个错误决定拖垮的,而是被一连串「看起来没问题」的决策慢慢稀释掉的。

一旦走到这一步,优化会变得异常昂贵,因为你失去了明确的下手点。
所谓「关键的3%」,指的从来不是写完代码后再去抠字眼,而是在写第一行代码时,就要避开那些虽然方便、但明显低效的路径。
这不只是技巧,更像一种素养。真正拉开差距的地方,往往发生在profiler还没派上用场之前。
5ns和5ms之间,隔着整个物理世界
如果说前面的区别发生在「已经来不及了」,那么接下来要说的是:「为什么我们会在一开始就走错路」。
事实上,很多工程事故并不是因为「不会优化」,而是因为对「慢」没有感觉。
在编辑器里,5ns和5ms看起来只是多了几个0。缩进一样,语法一样,在Code Review时看起来合理合规。
但在物理世界,这些数字根本不属于同一个尺度。
Jeff Dean在清单里列出了一张延迟对照表。一旦把这些数字还原成现实中的时间,很多所谓的设计直觉会当场崩塌。
L1缓存命中:约0.5ns,等于微观世界里的一次脉搏。
分支预测失败:5ns,是连续十次脉搏。
主存访问:50ns,相当于起个身,走下楼,取了个外卖。
随机磁盘寻址:10000000ns,相当于从北京一路走到了上海。
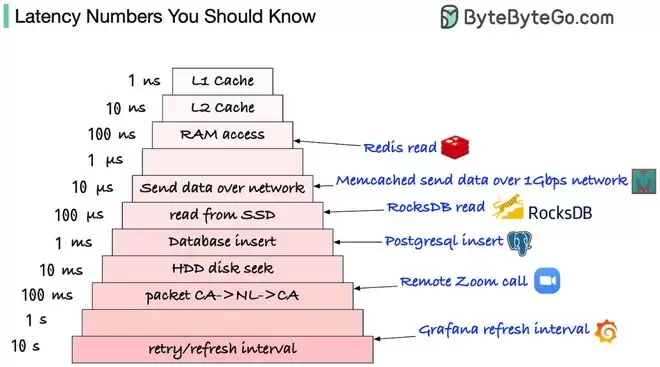
最早由Google工程师整理,Jeff Dean在多次演讲中用过这个思路
如果你的方案里出现了一次磁盘寻址,后面无论代码写得多优雅、逻辑多漂亮,在物理尺度上都已经输透了。
这就是顶级工程师脑子里的「物理地图」。他们本能地知道:哪些操作属于同一量级,而哪些操作一旦混进来,系统的节奏就彻底乱了。
这也是「信封背面估算」(Back-of-the-envelope calculation)的价值所在。
它是一次动手之前的排查:这个方案会触发多少次内存访问?有没有隐藏的分配?循环里会不会撞上网络IO?
如果答案里出现了一个不合时宜的量级,这个方案就应该被扔进垃圾桶。
很多性能问题并非「实现得不够好」,而是选错了路径。
一旦建立起这种尺度感,很多无意义的争论就能一眼看穿。
反直觉的真相:Google大佬的代码为什么看起来很「土」?
真正拉开差距的地方,不在于「写得多聪明」,而在于知道哪些地方「不值得聪明」。
翻开这份Performance Hints,我们能发现一个反直觉的事实:没有复杂的算法,很多改动看起来都有点「土」。
但这些细碎的选择,却被Jeff Dean反复拿出来强调。
对内存的节制
「尺度感」让我们意识到分配内存的珍贵,在实战中,这种意识会转化成对容器的极致考究。
为什么他们偏爱InlinedVector?因为在绝大多数场景下,它根本不碰堆内存,数据直接躺在栈上。
这带来的是实实在在的物理收益:少一次分配,多一次缓存命中。
同样的,使用Arena(内存池)也不只是为了管理方便,而是为了让数据在物理内存上变得连续,顺应CPU缓存的节奏。
对数据分布的尊重
所谓的Fast Path(快路径),本质上是承认世界是不均匀的。99%的请求和输入都比想象中普通。
如果坚持让每一次调用都走那条「最通用、最保险」的路,实际上是在用极少数的边缘情况,绑架绝大多数的正常流量。
清单里提到的UTF-8处理就是一个典型:现实中大量字符串其实只有纯ASCII字符。
如果一上来就按完整的解析逻辑走,那每一个字节都在为万分之一的极端情况买单。
看一眼,是ASCII就直接放行——这种行为,建立在对数据规律的尊重之上。
对抽象成本的自觉
清单里举了个例子:把Protobuf逻辑改成原生结构体,性能提升20倍,让很多人不安。
Protobuf确实解决了跨语言和版本演进的难题,但便利从不是免费的,每一层封装、每一次解析,都是一笔隐蔽的「抽象税」。
就像在透支信用卡,你可以尽情购物,可一旦账单寄来,就要付出相应代价。
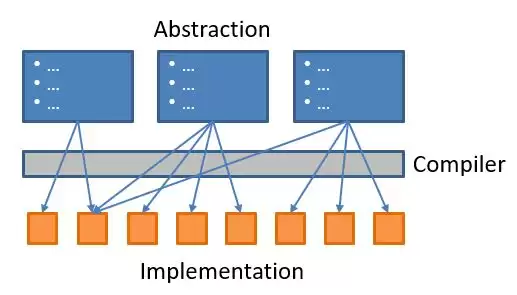
抽象并不会消失,只是被编译器展开,最终落实到一行行具体的实现上。
当抽象层数不断叠加,成本也会在底层被一并兑现。
这就是为什么他们建议在热路径里避开不必要的层级、避开那些「为了完整而完整」的设计。
目的是让你清楚地意识到,你到底在为什么付费。
顶级工程师关心的,从来不是如何写出最聪明的代码,而是如何避免那些本不该出现的开销。
当你在敲键盘时,能对分配、分布、抽象成本保持警惕,很多性能瓶颈在发生之前,就已经被挡在了门外。
想提高性能,就不能对代价视而不见
很多人把性能理解成一种阶段性的工作:系统慢了,就开始优化;不慢,就先放一边。
但读完这份清单,你很难再这样看待它。
Jeff Dean们反复强调的,其实不是「如何省下几纳秒」,而是「你是否真正理解自己正在使用的计算资源」。
CPU、内存、缓存、磁盘......这些底层的物理规律并没有因为云原生或AI的流行而消失,它们只是被包装得更抽象了。
顶级工程师之所以显得从容,是因为他们很少走到「火场」里:在写第一行代码时,他们就已经避开了那些注定昂贵的路径。
这份Performance Hints读起来不像教程,更像是一份肌肉记忆。它不要求你处处极限优化,而是要求你在做决策时,不要假装不知道代价。
也许真正的分界线一直是——当你写下一个循环、设计一个数据结构、决定要不要多加一层时,脑海中是否浮现出那张时间和尺度的地图。
一旦有了它,很多平庸的代码,你就再也写不下去了。
参考资料:
https://x.com/JeffDean/status/2002089534188892256?s=20
秒追ASI
⭐点赞、转发、在看一键三连⭐
点亮星标,锁定新智元极速推送!
相关攻略

CPU-Z发布2 20版本,显著扩展了对新一代处理器的识别支持,包括AMD锐龙PRO9000、锐龙AI400G系列及代号“GorgonHalo”的多款高端型号,以及英特尔相关平台。同时,新版本新增了对HUDIMM和HSODIMM等前沿内存模组的识别能力。

据外媒报道,近期发生了一件可能是最离谱的“捡漏”故事,不过这种运气可不是人人都有。 最近在Reddit上,一位用户的经历让整个硬件圈都直呼“离谱”。他在一家本地的清仓店里,只花了6 99美元,就成功拿下了一套64GB的DDR5笔记本内存(2×32GB)。 价格错误的“捡漏”故事之前也听过不少,比如半

日本DDR5内存价格“跳水”,但市场迷雾仍未散 最近,日本PC硬件市场传来一个值得玩味的消息:多款DDR5内存套装价格在4月中旬出现了显著松动,部分型号的降幅甚至超过了20%。这波降价,是市场回归理性的信号,还是又一次短暂的波动? 主流规格领跌,高频型号跟进 先看具体数据。根据市场监测,32GB(1

内存危机引发硬件涨价潮,Meta官宣Quest系列调价 一场由内存(RAM)供应紧张引发的连锁反应,正在消费电子市场掀起波澜。继索尼、微软之后,Meta也正式加入了涨价行列。公司今日宣布,自4月19日起,将对旗下Quest系列虚拟现实头显的售价进行全面上调。 具体来看,这次调价覆盖了多个产品线: M

采购价近乎翻倍:消息称苹果砸重金狂买三星12GB内存,只为首款折叠手机iPhone Fold 行业风向标终于有了新动向。来自韩媒The Bell的最新报道显示,苹果的首款折叠屏手机iPhone Fold,已经进入了量产备货的冲刺阶段。这不,为了保障核心零部件的供应,苹果已经开始向三星大量订购12GB
热门专题







热门推荐

钉钉文档官网 在探讨企业级协同办公解决方案时,钉钉文档无疑是备受瞩目的核心工具之一。作为阿里巴巴钉钉官方推出的旗舰级应用套件,它深度融合了在线文档编辑、智能表格、思维导图等多种高效创作工具。其核心优势在于与钉钉平台生态的无缝衔接,能够直接同步企业内部组织架构与通讯录,实现团队成员间的即时协作与信息流

在数字化转型浪潮中,高效、易用的数据分析工具已成为企业提升决策效率的关键。商汤科技推出的“办公小浣熊”智能助手,正是基于自研大语言模型打造的一款创新产品,旨在彻底降低数据分析的技术门槛。用户无需掌握编程知识或复杂操作,即可通过自然对话完成从数据查询、处理到可视化洞察的全流程,让数据价值触手可及。 办

在人工智能技术快速发展的今天,MiniMax作为一家专注于全栈自研的AI公司,正以其独特的技术路径和前瞻性的布局,在业界脱颖而出。公司致力于构建覆盖文本、图像、语音和视频的新一代多模态智能模型矩阵,这不仅体现了对核心底层技术自主权的深度掌控,也展现了对未来人机交互与内容生成形态的前瞻思考。 那么,M

ApolloCreditFund(ACRED)作为连接传统信贷与DeFi的桥梁,其价格受市场情绪、协议基本面及宏观环境影响。其价值逻辑根植于现实世界资产(RWA)的收益捕获与链上流动性释放。短期价格波动难以预测,但长期发展取决于信贷资产质量、协议安全性和市场采用度。投资者需关注其底层资产表现、代币经济模型及整个RWA赛道的发展趋势。

在数字化转型浪潮中,一套能够深度适配业务、彰显品牌特色的智能客服系统,已成为企业提升服务效率与用户体验的关键工具。然而,市场上许多解决方案往往模式固化,难以满足个性化需求。如何让AI客服不仅具备基础的自动化应答能力,更能承载独特的品牌文化与服务哲学?其核心在于系统是否支持深度的自定义与持续的AI训练