6B模型加错题本:轻量超越8B的NeurIPS训练技巧

新智元报道
编辑:LRST
【新智元导读】传统训练只关注模型输出对错,最新研究在大模型训练中引入「错题本」,记录了模型犯错时的内部思考状态,包括问题、推理过程和错误位置,更接近人类反思学习。通过辅助模型学习这些「错题本」,能实时校正主模型预测,提升性能。
很多人回顾自己的学习经历时都会发现:能力真正产生跃迁,并不是刷题数量最多的时候,而是开始系统整理「错题本」的阶段。
关键并不在于把错误答案抄下来,而在于持续追问——当时为什么会这么想?是哪一步的判断出现了偏差?这种错误是偶发的,还是反复出现的思维模式?
正是通过这种反思式学习,人类逐渐学会识别自身的「错误规律」,在复杂和不确定问题面前变得更加稳健。
那么,一个问题随之而来:大语言模型有没有属于自己的「错题本」?
在当前主流训练范式中,大模型的学习过程高度简化为一个循环:
给定输入 → 预测输出
与标准答案对比 → 计算loss
通过反向传播更新参数
从本质上看,这一过程强调的是「如何更好地拟合正确答案」。
模型只需要知道结果对不对,而并不真正关心:我当时是通过怎样的内部推理路径走到这个错误结论的?
这也揭示了一个关键缺失:当前的大模型并不缺数据,也不缺算力,而是缺少一种类似人类的深度反思能力——即围绕错误本身展开的结构化复盘。
伊利诺伊大学厄巴纳-香槟分校、普林斯顿大学的研究人员发表的最新论文,提出了一个非常「人类化」的概念:Mistake Log(错题本)。

论文链接:https://arxiv.org/pdf/2505.16270
代码链接:https://github.com/jiaruzouu/TransformerCopilot
与传统训练仅关注最终输出不同,Mistake Log的目标并不是回答「模型错没错」,而是刻画一个更本质的问题:模型是在什么样的内部状态下犯下这个错误的?
换句话说,它关注的不是答案,而是错误产生的全过程。
Mistake Log的三层结构
Question:模型当时在解决什么问题?
在训练过程中,每一个输入都会被映射为一个问题级别的表示,用于刻画「模型此刻面对的任务语境」。这一步对应的是:我当时在做哪一道题?
Rationale(核心):模型当时的内部推理状态
这是该方法与标准SFT拉开差距的关键所在。研究并不满足于观察最终生成的token,而是直接读取Transformer在所有层、所有token位置上的隐藏状态表示。这些高维向量并非人类可读的文字解释,而是模型真实的内部思考轨迹:
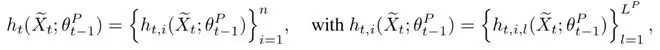
其中,t表示第t个训练步奏、i表示第i个 token、l表示第l层 Transformer、h表示模型计算过程中这一刻的隐状态。
将这些隐藏状态整体收集后,就得到了一个完整的Rationale轨迹:
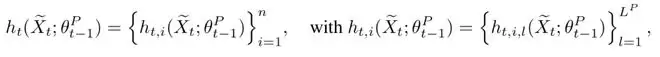
它可以被视为模型在犯错瞬间的「认知状态快照」。
这一步类似于人类在复盘错题时回忆:「我当时是基于哪个公式推导的?」「为什么在这个分支做出了错误判断?」
Mistakes:逐token精细刻画错误来源
不同于用一个标量loss模糊衡量整体错误,该工作在token级别定位偏差:(1)对比模型预测分布与真实分布;(2)计算两者在每个 token 上的差距:
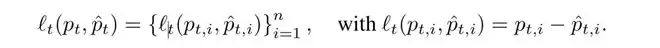
模型预测分布:
真实正确分布:
两者之间的 discrepancy(差距):
由此构建出一张错误热力图,精确回答这样的问题:错误是从哪一个 token 开始出现的?又是如何一步步累积放大的?一条完整的Mistake Log包含什么?
最终,每一次训练迭代都会生成一条三元组:
Question:任务语境
Rationale:内部推理状态
Mistakes:逐 token 的偏差刻画
如果训练进行了T步,那么模型就隐式地积累了T条结构化「错题记录」:
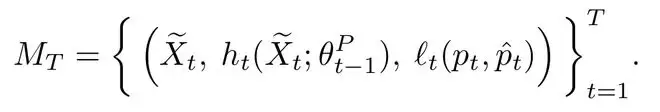
如何真正「利用」这些错题本?
作者进一步提出了一个极具启发性的设计:引入一个辅助模型 Copilot,专门学习主模型(Pilot)的Mistake Log。
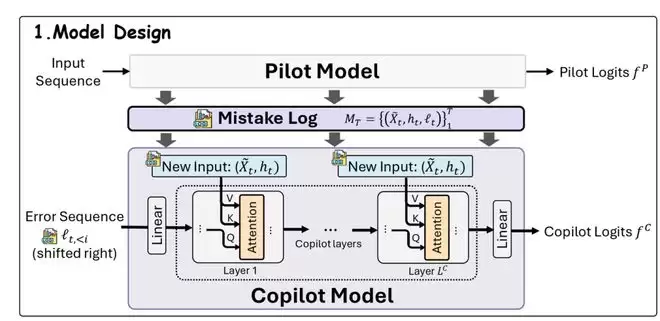
Copilot 的训练方式
辅助模型的输入形式:将任务对应的输入语境表示,与主模型在推理阶段产生的内部中间表示
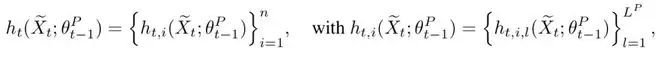
进行联合建模,以刻画模型当前的决策状态;
辅助模型的训练目标:学习预测主模型在生成过程中各个token层面的误差分布
,用于判断哪些位置更易产生偏差以及偏差程度的大小。
换言之,Copilot学习的是:在什么样的内部推理状态下,主模型更容易犯哪类错误?
Polit-Copilot的协同推理
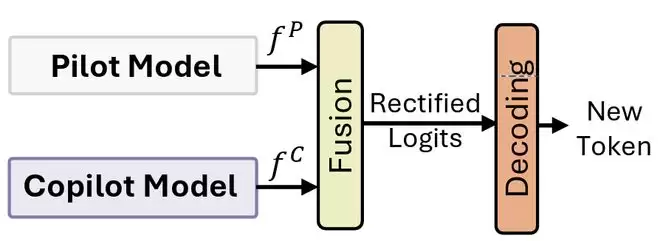
在生成过程中,Copilot输出的纠错logits会与主模型原始logits融合,从而在token生成阶段进行实时修正。最终的模型不再只是「记住答案」,而是具备了一种能力:基于历史错误经验,动态修正当前推理轨迹。
理论结果:纠错是有保证的
论文进一步证明:只要Copilot能较准确地预测错误趋势,且纠错权重λ选取在合理区间内,那么在每一个token维度上,融合后的预测期望误差严格小于原始模型的误差。

这意味着,Mistake Log并非启发式技巧,而是具有明确理论支撑的纠错机制。
纠错提升
小模型也能「以小博大」
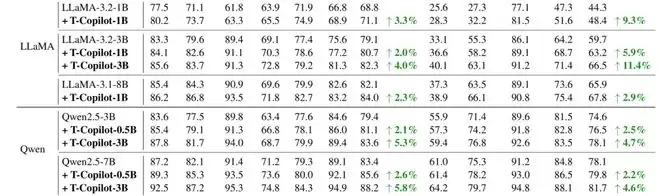
实验在多种主流模型(如LLaMA-3、Qwen2.5)和10个推理基准任务上验证了该方法的有效性。一个尤为亮眼的现象是:大模型 Pilot+小规模 Copilot+的组合,往往能显著提升性价比。
LLaMA-3.2-3B+3B Copilot(总6B参数)的性能超过原始8B的 LLaMA-3.1-8B。
这表明:纠错能力本身,可能比单纯扩大模型规模更关键。
讨论与展望
该工作首次系统性地定义并探索了大模型训练中的Mistake Log 机制,但这仅仅是一个起点。
当前主流的「反思式」方法,多依赖于显式思维链(Chain-of-Thought)和多Agent外部纠错,这些方法更多停留在输出层面,而Mistake Log则直接作用于模型内部认知状态。
一个值得深入研究的问题是:基于模型自身内部状态的「自我反思」,是否比依赖外部文本或代理的纠错方式更加有效?
此外,Mistake Log 的表示形式、错误模式的抽象方式,以及Copilot的结构设计,都仍有广阔的优化空间。目前方法在稳定性和泛化性上仍存在提升余地,值得在未来工作中进一步深入优化。
参考资料:
https://arxiv.org/pdf/2505.16270
秒追ASI
⭐点赞、转发、在看一键三连⭐
点亮星标,锁定新智元极速推送!
相关攻略

这项由MiroMind团队开展的研究发表于2026年3月16日的arXiv预印本平台,论文编号为arXiv:2603 15726v1。有兴趣深入了解的读者可以通过这个编号查询完整论文内容。说到人工智

这项由SenseTime Research联合南洋理工大学、加州大学伯克利分校、加州大学圣地亚哥分校、卡内基梅隆大学等多所知名院校合作的研究,发表于2026年3月的arXiv预印本平台,论文编号为a

这项由艾伦人工智能研究院(Allen Institute for AI)领导的突破性研究发表于2026年,论文编号为arXiv:2603 16861v1。研究团队包含来自华盛顿大学、普林斯顿大学、加

这项由上海科技大学联合腾讯混元团队共同完成的研究发表于2026年3月的arXiv预印本平台,论文编号为arXiv:2603 01142v1。对于想要深入了解技术细节的读者,可以通过该编号查询完整的学

新华社赫尔辛基3月6日电(记者朱昊晨 徐谦)芬兰阿尔托大学参与的一项最新研究发现,一些介观尺度的微小生物并非靠“更用力”或“长得更大”来游得更快,而是通过让运动在时间上呈现更强的不对称性来提升推
热门专题







热门推荐

上海启动全球首颗光计算卫星研制,其天基光计算具备抗辐照、低功耗特性,适应太空环境,可支撑在轨大算力任务。目前芯片太空验证已完成,全链条研制能力基本形成。产业面临成本与规模化挑战,需重构航天制造体系。长三角已成立创新联合体聚焦七大技术攻坚,上海将天基计算列为未来。

苹果与OpenAI合作因商业回报未达预期出现裂痕。腾讯地图推出AI骑手模式优化配送。百度成立模型委员会强化AI布局。荣耀将发布搭载云台系统的RobotPhone。Anthropic拟以9000亿美元估值融资。阿里发布智能体开发工作台Qoder1 0。千问APP接入药监局数据。发那科与英伟达深化合作,利用AI加速机器人开发。

面对海量书籍资源,数字化管理工具至关重要。小满图书管理侧重会员与库存管理,适合书店。库存管理通轻量化,支持多货品进销存。藏书馆兼具藏书管理与数字阅读功能。移动图书馆对接高校资源,提供学术服务。个人图书馆专注个人知识收集与创作。各类软件功能各异,需根据核心需求选择。

英文朗读软件能有效辅助学习。推荐几款特色应用:全能型《朗读器》操作简便;《朗读者》结合翻译与朗读;《英文翻译》支持长文朗读;《朗读大师》擅长图像识别与发音反馈;《中英文翻译》提供系统化学习路径。根据需求选择工具并坚持练习,可提升理解与发音能力。

飞机是远距离出行的高效选择,提前购票可锁定行程并享受优惠。主流购票平台包括飞猪旅行、携程旅行、航班管家、美团、飞行卡和去哪儿旅行。这些应用不仅提供机票预订,还整合酒店、景点门票、本地生活等服务,满足用户对价格、一站式规划或特定优惠的不同需求。