摩尔线程开发者大会:上市后首发重磅更新与未来路线图


国产GPU的叙事重心,正在从“造芯”转向“造生态”。
作者|王艺
摩尔线程上市后的首场大会来了。
2025年12月20日,摩尔线程首届MUSA开发者大会(MDC 2025)于北京中关村国际创新中心正式开幕。
这是摩尔线程首次举办开发者大会,也是国内首个聚焦全功能GPU的开发者盛会。本次大会以自主计算创新与开发者生态共建为核心议题,吸引了2000多名来自产学研的专业人士和开发者参与。
本次大会上,摩尔线程不仅发布了全新的GPU架构“花港”、万卡智算集群“夸娥”和搭载了智能SoC芯片“长江”的个人智算产品MTT AIBOOK(AI算力本),还分享了面向下一代超大规模智算中心的MTTC256超节点架构规划;同时,摩尔线程还展示了自己在推理领域的最新成果,并公布了在具身智能、科学智能(AI4S)、AIfor6G、开发者生态建设等领域的全新进展。
这一系列成果的发布,标志着摩尔线程已成功构建起一套以自主统一架构为根基、贯穿“芯-边-端-云”的完整技术栈,实现了从底层硬件到上层应用的系统化闭环。
1.硬核突破:“花港”架构与万卡集群的算力答卷
如果说过去国产GPU常被诟病的点是“性能”和“能效”,那么此次摩尔线程新一代全功能GPU架构“花港”的发布,则用数据一举打破了之前的刻板印象——该架构采用全新一代指令集,相比上一代架构,算力密度提升约50%,并通过深度架构优化实现最高10倍的能效提升。

在AI计算方面,花港全面支持FP8、FP6、FP4等多种低精度计算单元,显著提升大模型训练与推理的效率;在系统层面,花港可支持10万卡以上的超大规模计算集群,并引入新一代异步编程模型,以提升算力利用率。
同时,花港还在图形领域引入新一代AI生成式渲染架构(AGR),并重构第二代硬件光线追踪引擎,渲染和光追性能实现代际跃升。在安全性方面,花港构建了四级硬件安全防护体系,支持国密与机密算法,面向数据中心和关键行业应用。
基于花港架构,摩尔线程未来将发布AI芯片“华山”。该产品定位为AI训练与推理一体化的高端算力芯片,同时具备强大计算能力,面向大模型和AI超级集群场景。
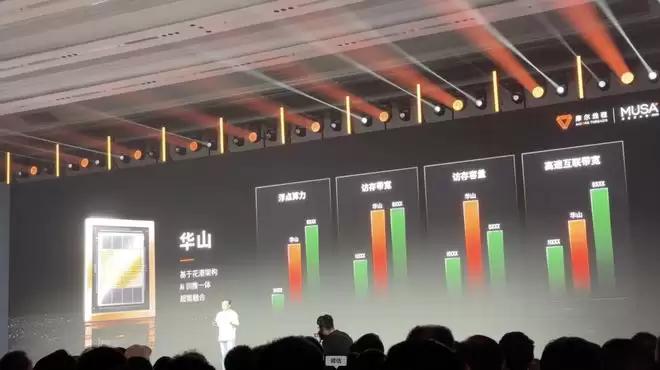
摩尔线程基于“花港”架构的AI训推一体芯片“华山”图源:「甲子光年」拍摄
在算力方面,华山的浮点计算能力对标国际先进GPU产品,能够支撑主流大模型的训练和推理需求;在系统设计上,华山配备高带宽缓存和大容量存储,并支持MTLink4.0及多种内嵌互联协议,提升集群兼容性与扩展能力。
摩尔线程创始人、董事长兼CEO张建中表示:“一张卡的性能很重要,但真正决定AI训练效率的,是能否稳定、高效地Scale到成千上万张卡。”
据介绍,华山单点最高支持1024颗GPU直连Scale-Up,并集成RAS2.0可靠性机制,支持错误检测、隔离与恢复,提升大规模训练的稳定性和成功率。此外,华山还在硬件层面内置大语言模型关键算子的加速引擎,实现软硬件深度协同。
同时亮相的庐山是一款面向高性能图形渲染计算的GPU产品,适用于CAD/CAE、工业设计、建筑可视化以及高端内容创作等场景。相较上一代S80产品的架构,庐山整体图形性能提升约15倍,AI算力提升64倍,几何处理能力提升16倍。其硬件级光线追踪性能相比S80提升约50倍,显存容量提升至前代的4倍。

摩尔线程基于“花港”架构的高性能图形渲染芯片“庐山”图源:「甲子光年」拍摄
“庐山”内置AI原生能力,并原创AI生成式渲染技术(AGR),让AI能力贯穿几何、像素、光追和后处理等整个渲染流程。同时,全新的统一任务引擎(Unified Task Engine)可实现GPU内部计算资源的全面并行,大幅提升渲染效率。
“庐山不仅是一张能玩3A游戏的显卡,更是一张面向专业设计和工业应用的生产力GPU。”张建中说。
在国产算力的语境里,“万卡”从来不是把卡堆起来那么简单。更难的部分,往往是“能跑多久、跑多稳、跑多满”。因此,摩尔线程全新发布的“夸娥万卡”智算集群,成为了本次大会继“花港”架构之后的第二个亮点。
张建中强调了“夸娥”万卡智算集群在万卡规模下的工程化能力与可靠性:能够支撑万亿参数模型训练,并在多项关键指标上对齐国际主流水平——浮点运算能力达到10Exa-Flops;Dense大模型MFU 60%、MOE大模型MFU 40%;有效训练时间占比超过90%,训练线性扩展效率达95%;
在训练侧,夸娥万卡集群基于原生FP8能力,完整复现顶尖大模型训练流程,并且在技术层面实现关键优化:Flash Attention算力利用率>95%,并突破FP8累加精度等瓶颈。

在推理侧,张建中同样展示了全功能GPU单卡的超强实力:摩尔线程联合硅基流动,在运行DeepSeekR1671B满血版大模型时,MTTS5000单卡Prefill吞吐速度突破4000tokens/s、Decode吞吐速度突破1000tokens/s。

但在AI战场,万卡“能训”只是起点,下一步要解决的是更高密度、更高带宽、更低单位能耗的系统形态。在大会上,摩尔线程公布了面向下一代超大规模智算中心的MTTC256超节点架构规划,主打高密硬件与极致智算性能。

并不是只有芯片和算力集群这样的“钢铁巨兽”。面对更加C端与更广大的开发者,摩尔线程也拿出了诚意。
此次大会上,摩尔线程了发布搭载智能SoC芯片“长江”的AI算力本MTT AIBOOK。其端侧AI算力可达50 TOPS,实现从芯片、驱动到开发环境全栈整合,并构建了Agent的“工具集”,大幅降低AI开发的门槛,同时创新打通了Linux开发、Windows办公与Android应用之间的场景壁垒,这使得AIBOOK不仅完整保留了传统PC的功能,还可以实现高效的AI开发体验。
这一创新工具,也成为开发者接入MUSA生态的关键入口。

2.软件根基:MUSA5.0,从“能用”到“好用”的系统工程
如果说上述产品的发布是摩尔线程上市之后对外界的一次“秀肌肉”和“牛刀小试”,那么MUSA软件栈,才是摩尔线程此次发布会祭出的真正“大杀器”。
国产GPU软件栈,一直都是中国GPU产业的“阿喀琉斯之踵”。当前,英伟达的CUDA生态在AI和科研领域仍然是“事实标准”,垄断着GPU开发的大半江山,而国产GPU多依赖开源方案(如OpenCL、Vulkan)或自研框架,工具链成熟度低、移植成本高、开发者意愿不足。
尽管部分国产GPU专注AI训练/推理,但配套的编译器、算子库、模型优化工具链仍需长期积累;此外,国产GPU的驱动程序的稳定性、游戏兼容性、图形API支持(如DirectX、Vulkan)也不完善,用户体验与国际产品有较大差距。
MUSA(Meta-computingUnifiedSystemArchitecture)是摩尔线程自主研发的元计算统一计算架构,覆盖从芯片架构、指令集、编程模型到软件运行库及驱动程序框架等的全栈技术体系。MUSA不仅定义了统一技术标准,更是被摩尔线程赋予了长期“底层创新”的战略意义,并服务于全功能GPU的多场景目标:AI计算、图形渲染、物理仿真和科学计算、超高清视频编解码等。
在大会上,张建中回顾了MUSA架构与产品的演进路径:
“硬件可以一年一代,但软件必须持续进化。”张建中表示。
在本次大会上,摩尔线程正式发布MUSA5.0。全新升级的MUSA5.0标志着架构步入成熟新阶段,在全栈统一性、极致效能与生态开放性上取得关键突破:
编程生态全面升级:原生MUSA C,深度兼容TileLang、Triton等编程语言,为开发者提供灵活高效的全栈开发体验。
计算效能极致优化:核心计算库muDNN实现GEMM/FlashAttention效率超98%,通信效率达97%,编译器性能提升3倍,并集成高性能算子库,显著加速训练与推理全流程。
开源生态持续扩大:计划逐步开源计算加速库、通信库及系统管理框架在内的核心组件,向开发者社区开放深度优化的底层能力。
前沿特性拓展边界:即将推出兼容跨代GPU指令架构的中间语言MTX、面向渲染+AI融合计算的编程语言muLang、量子计算融合框架MUSA-Q,以及计算光刻库muLitho,持续拓展全功能GPU的算力边界。

“MUSA5.0基本可以完整覆盖今天用户的全部应用场景,能够完美支撑AI GPU的生态体系。”张建中说。
值得注意的是,MUSA并非只面向单一平台或操作系统。MUSA5.0在兼容主流国际CPU与操作系统的同时,也全面支持国产CPU与国产操作系统,实现国产生态与国际生态的并行适配,统一支撑云、边、端全系列GPU产品。
这意味着,无论是数据中心、工作站还是终端设备,摩尔线程均可通过同一套软件体系进行部署和开发,大幅降低了开发与运维成本。
3.战略转身:从“造芯”到“造生态”的突围战
然而,仅有硬件和软件还不够。国产GPU更大的问题,是“不够好用”。
硅基流动创始人兼CEO袁进辉在大会上表示,由于芯片细节太多、场景太杂,因此必须通过软件栈一层层抽象,把复杂性隐藏起来。当抽象不够时,开发者就不得不往下挖,“当开发者发现最上层的抽象不满足需求的时候,他会再往下去发掘更底层的一些工具箱……一直到底层的芯片。”
这就国产芯片普遍有30-50%的理论性能释放不出来的原因——要么是软件栈的API太厚把特性藏起来了,要么就是太薄,让开发者无从下手。
除了性能释放得不够极致、芯片不够好用,北京智源人工智能研究院AI框架研发负责人敖玉龙也指出了国产GPU的另一个问题——当前大部分的大模型仍然是跑在CUDA上的,迁移到国产原生软件栈的成本比较高。
“我们不能总在migration(迁移),怎么基于国产去原生的去做一些事情?大家缺的可能一方面是信心,另一方面产品质量和生态也很关键。”敖玉龙说。
怎么办?众人拾柴火焰高。
袁进辉举了一个行业规律:即便是最主流的平台,新芯片发布后也需要时间被真正“用顺”——“通常过一年之后在上面跑的软件能够加速两倍以上。”更重要的是,很多玩法并非芯片公司预设,而可能是“新的”,是原来那个芯片厂商也没有预计到的。他期待在MUSA上也出现“开发者玩出来”的创新:“这就可能需要摩尔线程提供一些架构的资料手册……让更多开发者去hack。”
这是一种生态的打法:把底层能力向社区开放,让优化与创新不再只能由厂商完成。
摩尔线程联合创始人兼首席技术官张钰勃在大会上表示,在上一代“平湖”架构中,Attention算法的利用率就已经能够做到90%以上了,而同期的H100只能做到75%。“那剩下的东西怎么样能够暴露出来呢?我们就通过像支持Python,甚至是将来基于Tile的编程方式,通过编译器的方式把它暴露出来。我们觉得光靠厂商自己的软件栈还不够,还需要跟开发者做深度的结合。”张钰勃说。
因此,摩尔线程的策略是“双轨制”:一方面在开发者使用习惯上“贴近主流”;另一方面,通过更高阶抽象、DSL/编译器与软硬协同,而是通过与模型团队、系统团队的深度联合优化,把GPU的潜在性能释放出来,确保国产平台永远能“跑满”而不只是“能跑”。
换句话说,摩尔线程正在把叙事重心从“造芯”挪向“造生态”。
这一点,与郑纬民院士在大会上的判断形成了清晰呼应。在郑纬民看来,主权AI并不是单点技术问题,而是一项系统工程,其核心由三根支柱共同支撑:算力自主、算法自强、生态自立。其中,生态的重要性往往被低估,却恰恰决定了一项技术路线能否走得长远。
郑纬民把产业现实说得很直接:不同厂商接口不一,导致用户经常为同一软件做重复适配。“你做出一个芯片固然很重要,但如果没有足够多的开发者愿意长期在上面写代码,那就是白生产。”郑纬民表示,真正决定国产算力成败的,并不是有没有一两款性能亮眼的芯片,而是有没有一个以开发者为中心、能够持续演化的产业生态。“我希望用户工作量的减少,不同芯片、不同系统,最后是一套东西。”
在大会上,摩尔线程联合创始人兼首席技术官张钰勃也表示,未来摩尔线程的GPU,从架构到上面的每一层软件,全部都会坚持开源的路线,为发展好的国产计算生态贡献自己的力量。
正如清华大学高性能计算所所长翟季冬在大会上所说,芯片性能可以在几年内追赶,但生态系统需要十年、二十年的持续投入和积累。当前,国产GPU产业正站在一个关键的十字路口。一方面技术突破正在加速到来,另一方面,碎片化与内卷的隐患也在累积。这些问题如果不解决,国产GPU可能会陷入“有算力用不好、有芯片没生态”的困境。
这正是摩尔线程此次MUSA大会最大的价值所在——它并没有在宣告一场胜利,而是在吹响一场更艰苦战役的号角——战役的主角,是坐在台下的每一位开发者。只有当足够多的中国开发者开始在MUSA平台上“hack”出新玩法,只有当第一个世界级SOTA模型诞生于国产的GPU软件栈上,只有当国外团队开始“反向移植”面向MUSA优化的模型架构,那一天,我们或许才能说,属于中国GPU的时代真正到来了。
(封面图及文中未标注来源图片均来自摩尔线程)
相关攻略

晨涧云是什么 在人工智能和前沿科学计算领域,算力正成为驱动创新的核心引擎。然而,自建高性能计算集群不仅成本高昂,其复杂的运维也让许多团队望而却步。正是在这样的背景下,晨涧云应运而生。 简单来说,晨涧云是一个专门为深度学习、AI模型训练以及复杂科学模拟打造的GPU算力服务平台。它的核心价值在于,将分散

智谱的ZCube组网架构通过优化网络拓扑,在不增加GPU和修改代码的情况下,使集群推理吞吐量提升15%,首Token响应延迟降低40 6%,并减少三分之一的交换机和光模块用量。行业正从堆硬件转向挖掘系统效率,类似OpenAI的MRC协议等技术也聚焦网络优化,推动高端交换机与高速光模块需求增长,帮助企业在现有算力中提。

英伟达最新财报显示营收与净利润同比大幅增长,但股价小幅下滑,市场对其高增长数字已显“审美疲劳”,更关注长期战略。黄仁勋阐述了“后GPU时代”的新增长点:将数据中心业务细分为超大规模市场和覆盖广泛经济规模的ACIE市场;同时积极进军CPU业务,下一代VeraRubin系统也将量产。公司还宣布大幅增加股票。

英特尔CEO陈立武透露,其18A制程已支持PantherLake量产,良率提升超预期;14A制程的PDK已发布,并向更先进的10A和7A节点规划。他着重指出,AI计算正从训练转向推理,CPU因通用性强、延迟低而愈发关键,未来CPU与GPU的配比可能达到4:1。为把握机遇,英特尔正积极拓展ASIC定制芯片业务。

AMD开发者大会指出AI正转向推理普及,面临算力与隐私挑战。AMD通过开放生态应对,强调系统协同与统一内存,推出锐龙AIMax系列处理器支持本地大模型运行,并展示ROCm软件栈实现高效部署。AMD深耕中国生态,推出开发者云等服务,与本地开发者共推AI创新。
热门专题







热门推荐

在《燕云十六声》中领悟“菩提苦海”,需沉浸探索游戏世界。主线剧情构建认知框架,战斗观察、场景细节与NPC对话皆暗藏线索。通过多元视角拼凑因果,方能深入理解游戏蕴含的宏大叙事与深邃魅力。

2026年618大促的序幕刚刚拉开,初期战报已经透露出一些耐人寻味的信号。截至5月21日,海信电视在京东平板电视累计销售竞速榜上拔得头筹,其RGB-Mini LED爆款王——海信小墨E5S Pro,更是同时拿下了天猫平板电视和抖音大家电的5 20单品销冠。 这并非偶然。奥维云网的全渠道监测数据给出了

充电桩领域的“军备竞赛”再次迎来重磅升级。5月22日,极氪汽车正式发布了其全新一代液冷超级充电桩,将单枪峰值功率一举提升至行业领先的800kW,标志着超充技术迈入新阶段。 根据官方披露的核心信息,这款超充桩主要具备四大优势:极速补能、高效节能、广泛适配与多重安全。具体而言,其单枪峰值电流高达800A

获取电弧机剑主要有五种途径:推进主线任务以解锁线索;探索遗迹、工厂等特定区域;挑战特定副本与Boss;完成提及传说武器或遗物的支线任务;参与限时活动并达成要求。玩家可根据偏好选择或组合多种方式获取该武器。

小米汽车再次为潜在车主带来惊喜福利!即日起至5月31日,用户只需提前完成预约,并到店参与任意车型的试驾体验,即可免费获赠一款1:64精致合金车模。车模款式与颜色随机发放,为试驾过程增添一份专属的收藏乐趣,诚意十足。 参与本次活动需注意以下细则:试驾必须通过官方渠道提前预约;各授权门店的车模备货数量不