谷歌再更新T5-Gemma模型,编码器-解码器架构持续领先
编辑|冷猫
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
最近,或许是年底了,谷歌的发布变得有些密集。比如昨天,谷歌发布了在智能 / 成本上全球性价比最高的模型 Gemini 3 Flash。

在 Gemini 3 Flash 发布后,大家都以为谷歌今年的模型发布已经收官的时候,谷歌却又掏出了一个让大家都意想不到的模型更新:T5Gemma 2
T5Gemma 系列模型似乎没能给大众留下什么深刻印象。今年 7 月,谷歌第一次发布了 T5Gemma 模型系列,并且一口气发布了 32 个模型。
从模型名称可以看出,T5Gemma 系列模型与 T5 息息相关。T5(Text-to-Text Transfer Transformer) 是 Google 在 2019 年提出的一种编码器 - 解码器(Encoder–Decoder)大模型框架,「编解码器大模型」的思想源头,几乎都能追溯到 T5。
T5Gemma 使用了「适应(adaptation)」技术将已经完成预训练的仅解码器模型转换为编码器 - 解码器架构。
但遗憾的是,「编码器 - 解码器架构」始终没有成为大模型世界的主流,在「仅解码器」大语言模型快速迭代的大背景下难逃逐渐被边缘化的命运。
谷歌是为数不多仍在坚持编码器 - 解码器架构大模型的玩家。
今年上半年,谷歌发布了开放模型 Gemma 3 系列,性能强大,反响热烈,衍生出许多基于 Gemma 3 系列模型的优秀工作。这次更新的 T5Gemma 2 模型正是其中之一。
简而言之:T5Gemma 2,是谷歌新一代编码器 - 解码器模型,是首个多模态和长上下文的编码器 - 解码器模型,建立在 Gemma 3 的强大功能之上。
主要创新和升级功能包括:
支持多模态扩展长上下文开箱即用,支持 140 多种语言效率提升的架构创新
同时,谷歌向社区发布了 270M–270M、1B–1B 以及 4B–4B 三种规模的预训练模型,是社区中首个支持超长上下文(最高 128K)的高性能编解码器大语言模型

论文链接: https://arxiv.org/abs/2512.14856HuggingFace 链接: https://huggingface.co/collections/google/t5gemma-2博客链接: https://blog.google/technology/developers/t5gemma-2
T5Gemma 2 延续了 T5Gemma 的「适应(adaptation)」训练路线:将一个预训练的纯解码器模型适配为编解码器模型;同时,底座采用 Gemma 3 模型,通过结合 Gemma 3 中的关键创新,将这一技术扩展到了视觉 - 语言模型领域。
新架构,新能力
高效的架构创新
T5Gemma 2 不仅仅是一次再训练。它在继承 Gemma 3 系列许多强大特性的同时,还进行了重要的架构变更:
1. 词嵌入绑定
在编码器与解码器之间 共享词嵌入参数。这一设计显著降低了模型的总体参数量,使我们能够在相同的显存 / 内存占用下容纳更多有效能力 —— 这对全新的 270M–270M 紧凑模型尤为关键。
2. 合并注意力
在解码器中,我们采用了合并注意力机制,将自注意力(self-attention)与交叉注意力(cross-attention)融合为单一、统一的注意力层。这一做法减少了模型参数和架构复杂度,提升了模型并行化效率,同时也有利于推理性能的提升。
新一代模型能力
得益于 Gemma 3 的能力,T5Gemma 2 在模型能力上实现了显著升级:
1. 多模态能力
T5Gemma 2 模型能够同时理解和处理图像与文本。通过引入一个高效的视觉编码器,模型可以自然地完成视觉问答和多模态推理等任务。
2. 超长上下文
我们对上下文窗口进行了大幅扩展。借助 Gemma 3 的局部 — 全局交替注意力机制(alternating local and global attention),T5Gemma 2 能够支持最长达 128K token 的上下文输入。
3. 大规模多语言支持
通过在规模更大、更加多样化的数据集上进行训练,T5Gemma 2 开箱即用即可支持 140 多种语言。
性能结果
T5Gemma 2 为紧凑型编码器 - 解码器模型设定了新的标准,在关键能力领域表现出色,继承了 Gemma 3 架构强大的多模态和长上下文特性。
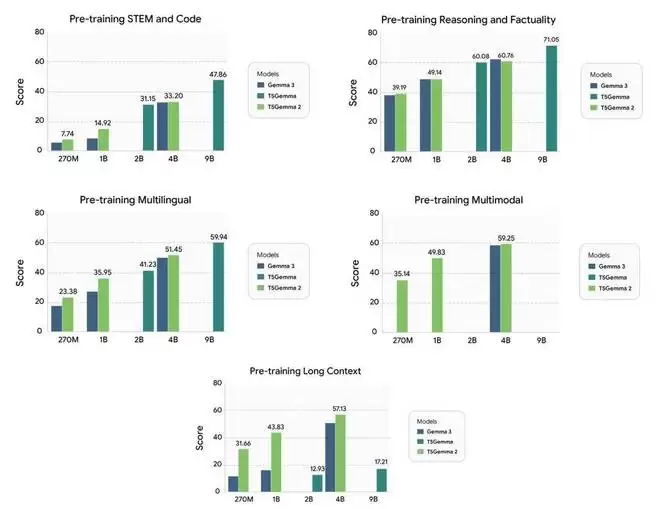
Gemma 3、T5Gemma 和 T5Gemma 2 在五个独特能力上的预训练性能。
如上图所示,T5Gemma 2 展现出以下突出优势:
强大的多模态性能:在多个基准测试中超越 Gemma 3。原本仅支持文本的 Gemma 3 基础模型(270M 与 1B) 成功适配为 高效的多模态编解码器模型。卓越的长上下文能力:相较于 Gemma 3 和 T5Gemma,在生成质量上取得了显著提升。通过引入独立的编码器,T5Gemma 2 在处理长上下文问题时表现更佳。全面提升的通用能力:在 代码、推理和多语言 等任务上,T5Gemma 2 整体上均优于其对应规模的 Gemma 3 模型。
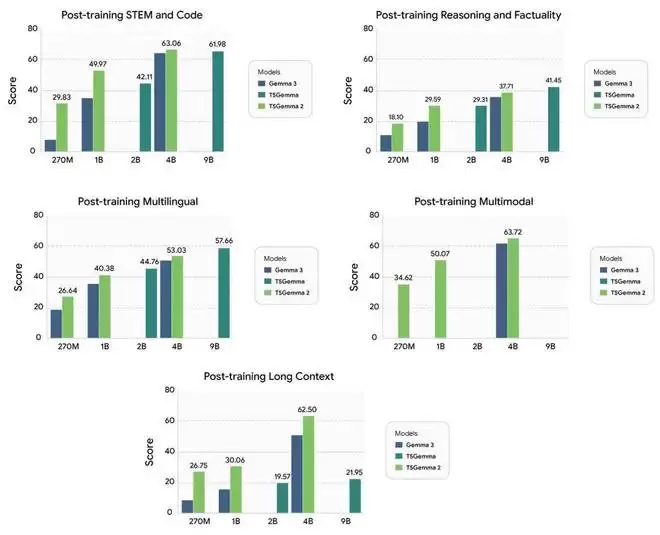
训练后性能。这里的结果仅用于说明,研究团队对 T5Gemma 2 进行了最小的 SFT,未使用 RL。另外请注意,预训练和训练后基准是不同的,因此不同图表中的分数不可比较。
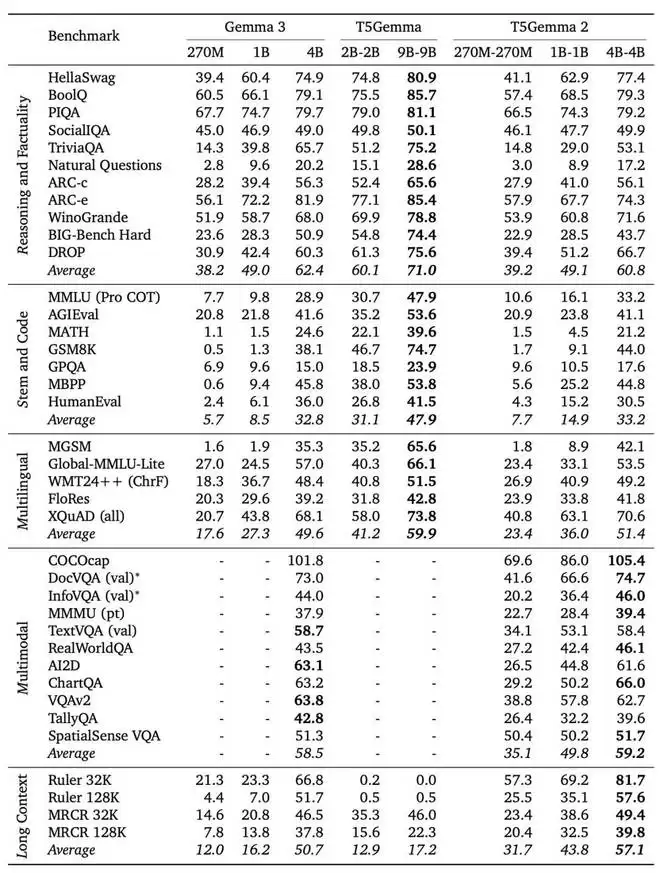
Gemma 3、T5Gemma 与 T5Gemma 2 的详细预训练结果。需要注意的是,Gemma 3 的 270M 与 1B 模型,以及 T5Gemma 的 2B–2B 和 9B–9B 模型均为纯文本模型。带有 “∗” 标记的结果为近似值,无法在不同论文之间直接比较。
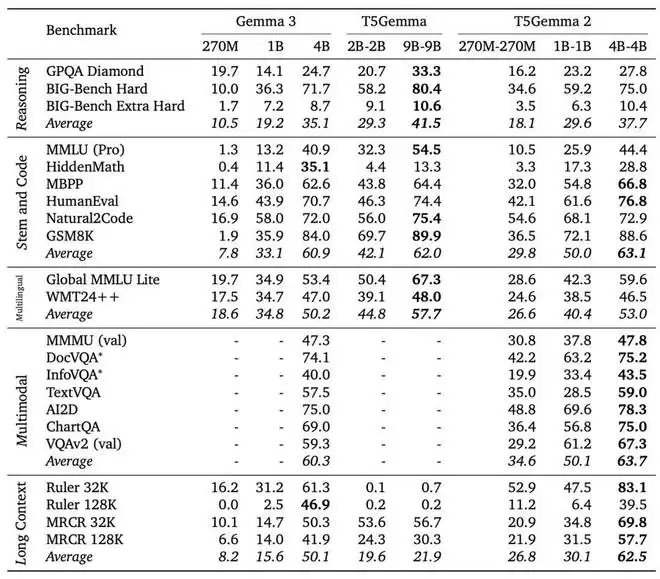
Gemma 3、T5Gemma 与 T5Gemma 2 的详细后训练结果。尽管 T5Gemma 2 的后训练过程相对轻量化,但其在大多数能力维度上仍然优于 Gemma 3。
实验结果表明,该适配策略在不同模型架构与不同模态上都具有良好的通用性,同时也验证了编解码器架构在长上下文建模方面的独特优势。与 T5Gemma 类似,T5Gemma 2 在预训练阶段的性能可达到或超过其 Gemma 3 对应模型,而在后训练阶段则取得了显著更优的表现
我们能看到,编码器 - 解码器架构下的大模型并不弱于仅解码器架构的模型,甚至具备自己独特的优势。
谷歌继续坚持的编码器 - 解码器架构,能否打破被边缘化的现状,让我们拭目以待。
相关攻略

头图由智象未来AI大模型生成智东西作者 王涵编辑 漠影在演唱会、各大晚会的舞台上,机器人伴舞团以整齐划一、精准卡点的舞姿惊艳全场。这种整齐划一不仅是硬件的胜利,更是“训练有素”的结果。具身智

智东西编译 陈佳编辑 程茜智东西4月3日消息,今日谷歌DeepMind开源发布Gemma 4系列模型,根据最新博客,这是谷歌迄今为止最智能的开放模型,专为高级推理和智能体工作流而设计,实现了单位参数

带着 Seedance 2 0 和 ArkClaw 两件新武器,火山引擎开始席卷 MaaS 市场。作者|郑玄两年前,火山引擎说要 All in Token 的时候,很多人觉得这是一句正确但空洞的口号

一个学生忽视了一行代码,结果发现了一件很不对劲的事:在一个多模态医学AI项目中,这行代码原本负责让模型读取图像数据。但因为这次疏忽,模型实际上完全没有看到任何图片。按理说系统应该报错,或者至少拒绝回

智通财经APP获悉,中信证券发布研报称,2026年以来,国产大模型厂商聚焦Agent及代码能力升级,竞相发布新模型。即将发布的DeepSeek下一代新模型有望延续高性价比开源模型路线,在能力上实现更
热门专题







热门推荐

加密货币行业翘首以盼的监管里程碑,终于有了实质性进展。美国证券交易委员会(SEC)主席保罗·阿特金斯(Paul Atkins)近日证实,那份允许加密项目在早期获得注册豁免权的“安全港”框架提案,已经正式送抵白宫,进入了最终审查阶段。 在范德堡大学与区块链协会联合举办的数字资产峰会上,阿特金斯透露了这

微策略Strategy报告:第一季录得144 6亿美元浮亏 再斥资约3 3亿美元买进4871枚比特币 市场震荡的威力有多大?看看Strategy的最新季报就明白了。根据其最新向美国证管会(SEC)提交的8-K报告,受市场剧烈波动影响,这家公司所持的比特币在第一季度录得了一笔惊人的数字——144 6亿

稳定币巨头Tether的动向,向来是加密世界的风向标。这不,它向Web3基础设施的版图扩张,又迈出了关键一步。公司执行长Paolo Ardoino在社交平台X上透露,其工程团队正在全力“烹制”一个新项目——去中心化搜索引擎 “Hypersearch”。这个消息一出,立刻引发了行业的广泛猜想。 采用D

基地位于Coinbase旗下以太坊Layer2网络Base的Seamless Protocol,日前正式宣告了服务的终结。这个曾经吸引了超过20万用户的原生DeFi借贷协议,在运营不到三年后,终究没能跑赢时间。它主打的核心产品是Integrated Leverage Markets(ILMs)——一

PAAL代币揭秘:深度解析Web3社区治理的核心钥匙 在去中心化自治组织的浪潮中,谁真正掌握了项目的话语权?PAAL代币提供了一套系统化的答案。它不仅是生态内流转的价值媒介,更是开启链上治理大门的核心凭证。通过持有并质押PAAL代币,用户能够对协议升级、资金分配乃至战略方向等关键事务投出决定性的一票