金磊 发自 凹非寺
量子位 | 公众号 QbitAI
当Ilya Sutskever最近公开宣称“纯靠Scaling Law的时代已经结束”,并断言“大模型的未来不在于单纯的规模更大,而是要架构变得更聪明”时,整个AI界都意识到了一场范式转移正在发生。
因为过去几年,行业似乎沉迷于用更多数据、更大参数、更强算力堆出更强的模型,但这条路正逼近收益递减的临界点。
Ilya和LeCun等顶尖AI大佬不约而同地指出:真正的突破,必须来自架构层面的根本性创新,而非对现有Transformer流水线的修修补补。
就在如此关键节点,一个来自中国研究团队的新物种横空出世:
全球首个可大规模落地的开源原生多模态架构(Native VLM),名曰NEO。

△《黑客帝国》主角Neo,图片由AI生成
要知道,此前主流的多模态大模型,例如我们熟悉的GPT-4V、Claude 3.5等,它们的底层逻辑本质上其实玩的就是拼接。
什么意思呢?
就是将一个预训练好的视觉编码器(比如 ViT)通过一个小小的投影层,嫁接到一个强大的大语言模型上。
这种模块化的方式虽说是实现了多模态,但视觉和语言始终是两条平行线,只是在数据层面被粗暴地拉到了一起。
而这项来自商汤科技与南洋理工大学等高校的联合研究,要做的就是从根上颠覆这一切。

在NEO这里,大模型不仅能看、会说,而且天生就懂视觉和语言是一体两面的道理。
更惊人的一组数据是,凭借这种原生多模态架构,NEO仅用十分之一的训练数据,就在多项关键评测中追平甚至超越了那些依赖海量数据和复杂模块堆砌的旗舰级对手!
那么NEO到底是怎么如何做到的,我们继续往下看。
为什么非得是原生架构?
在深入了解原理之前,我们还需要理解多模态当前的现状。
正如我们刚才提到的,当前主流的模块化架构,实则存在三大难以跨越的技术鸿沟。
首先是效率鸿沟。
模块化模型的训练流程极其复杂,通常分为三步:先分别预训练视觉编码器和语言模型,再通过一个对齐阶段让二者学会沟通,最后可能还需要指令微调。
这个过程不仅耗时耗力,成本高昂,而且每个阶段都可能引入新的误差和不一致性;视觉和语言的知识被割裂在不同的“房间”里,需要不断“传纸条”才能勉强协作。
其次是能力鸿沟。
视觉编码器在设计之初就带有强烈的归纳偏置。比如,它通常要求输入图像必须是固定的分辨率(如224x224),或者必须被强行展平成一维的token序列。
这种处理方式,对于理解一幅画的整体构图或许足够,但在面对需要捕捉细微纹理、复杂空间关系或任意长宽比的场景(比如一张长图、一张工程图纸)时,就显得力不从心。
因为模型看到的,只是一个被过度简化和结构化的骨架。
最后是融合鸿沟。
那个连接视觉和语言的映射,几乎都是停留在简单的表层,无法触及深层次的语义对齐。这就导致了模型在处理需要细粒度视觉理解的任务时常常捉襟见肘。
例如,让它描述一张复杂图表,它可能会混淆图例和数据;让它理解一个带有空间指示的指令,比如“把左边第二个红苹果放到右边篮子里”,它可能会搞错左右或数量。
究其根本,是因为在模型内部,视觉信息和语言信息从未被放在同一个语义空间里进行真正的、深度融合的推理。
也正因如此,NEO背后研究团队从第一性原理出发,直接打造一个视觉与语言从诞生之初就血脉相连的统一模型——
这个模型不再有视觉模块和语言模块的区分,只有一个统一的、专为多模态而生的大脑。
回顾AI发展史,从RNN到Transformer,每一次真正的飞跃都源于架构层面的根本性创新。
而过去几年,行业陷入了“唯规模论”的路径依赖,直到今天,以Ilya为代表的一批顶尖研究者才集体发出警示:Transformer架构的固有局限已日益凸显,仅靠堆叠算力和数据,无法通往真正的通用智能。
NEO的诞生,恰逢其时。它用一个简洁而统一的原生架构,有力地证明了:下一代AI的竞争力,关键在于架构有多聪明。
NEO背后的三大原生技术
NEO 的核心创新,体现在三个底层技术维度上,它们共同构建了模型的原生能力。
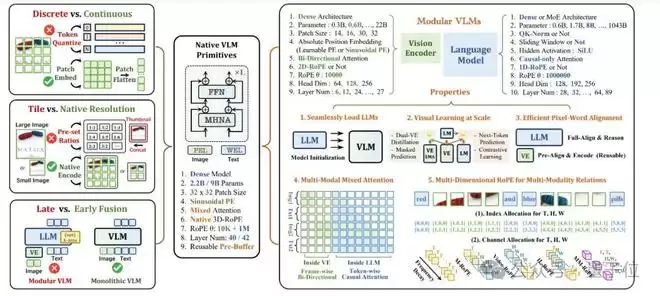
第一,原生图块嵌入(Native Patch Embedding)。
传统模型常预先采用离散的tokenizer或者连接vision encoder压缩图像信息或语义token。
NEO则是直接摒弃了这一步,它设计了一个轻量级的图块嵌入层,通过两层卷积神经网络,直接从像素出发,自底向上地构建一个连续的、高保真的视觉表征。
这就像让AI学会了像人类一样,用眼睛直接感受光影和细节,而不是先看一张被马赛克化的抽象图。
这种设计让模型能更精细地捕捉图像中的纹理、边缘和局部特征,从根本上突破了主流模型的图像建模瓶颈。
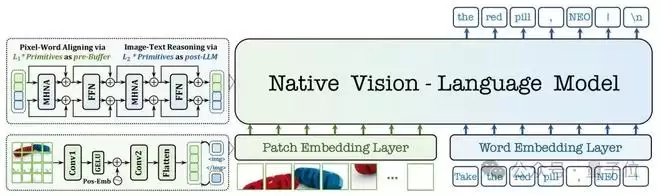
第二,原生三维旋转位置编码(Native-RoPE)。
位置信息对于理解任何序列都至关重要。文本是一维的,而图像是二维的,视频更是三维的(时空)。传统模型要么给所有模态用同一个一维位置编码,要么简单地拼接,这显然无法满足不同模态的天然结构。
NEO的Native-RoPE创新性地为时间(T)、高度(H)、宽度(W)三个维度分配了不同的频率:视觉维度(H, W)使用高频,以精准刻画局部细节和空间结构;文本维度(T)兼顾高频和低频,同时处理好局部性和长距离依赖。
更巧妙的是,对于纯文本输入,H和W的索引会被置零,完全不影响原有语言模型的性能。
这相当于给AI装上了一个智能的、可自适应的时空坐标系,不仅能精准定位图像中的每一个像素,也为无缝扩展到视频理解和3D交互等复杂场景铺平了道路。
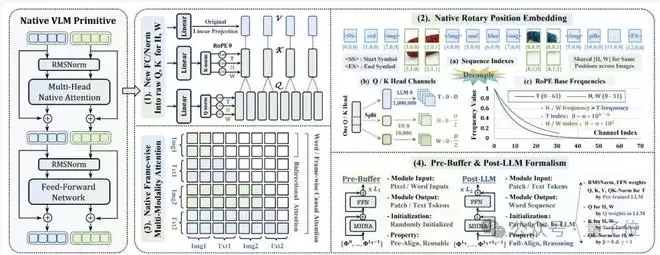
第三,原生多头注意力(Native Multi-Head Attention)。
注意力机制是大模型的思考方式,在传统模块化模型里,语言模型的注意力是因果的(只能看到前面的词),而视觉编码器的注意力是双向的(能看到所有像素)。
NEO采取的方法,则是在一个统一的注意力框架下,让这两种模式并存。
当处理文本token时,它遵循标准的自回归因果注意力;而当处理视觉token时,它则采用全双向注意力,让所有图像块之间可以自由地交互和关联。
这种“左右脑协同工作”的模式,极大地提升了模型对图像内部空间结构的理解能力,从而能更好地支撑复杂的图文交错推理,比如理解“猫在盒子上方”和“猫在盒子里”的细微差别。
除了这三大核心,NEO还配套了一套名为Pre-Buffer & Post-LLM的双阶段融合训练策略。
在预训练初期,模型会被临时划分为两部分:一个负责视觉语言深度融合的Pre-Buffer和一个继承了强大语言能力的Post-LLM。
前者在后者的引导下,从零开始高效地学习视觉知识,建立初步的像素-词语对齐;并且随着训练的深入,这个划分会逐渐消失,整个模型融为一个端到端的、不可分割的整体。
这种策略便巧妙地解决了原生架构训练中如何在不损害语言能力的前提下学习视觉的难题。
十分之一的数据,追平旗舰
纸上谈兵终觉浅,实测数据见分晓。接下来我们就来看下NEO在实测中的表现。
纵观结果,最直观的体现就是数据效率——
NEO仅使用了3.9亿个图像文本对进行训练,这个数量级仅仅是同类顶级模型所需数据的十分之一!
它无需依赖庞大的视觉编码器或海量的对齐数据,仅凭其简洁而强大的原生架构,就在多项视觉理解任务上追平了 Qwen2-VL、InternVL3等顶级模块化旗舰模型。
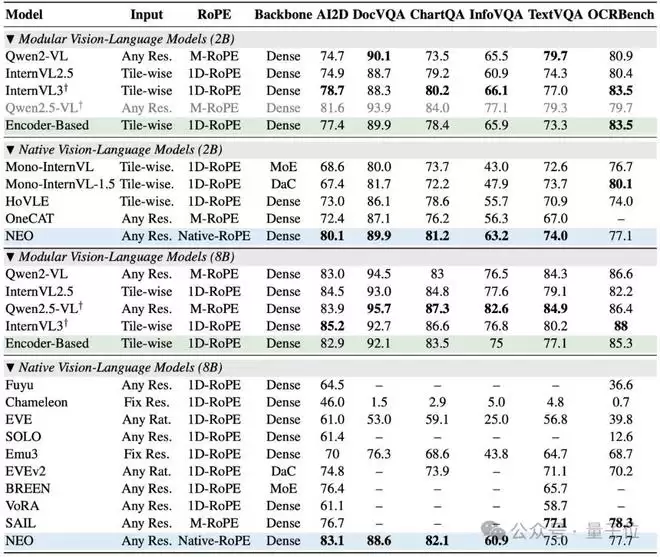
在权威的评测榜单上,NEO的表现也是较为亮眼。
在MMMU(多学科综合理解)、MMBench(综合多模态能力)、MMStar(空间与科学推理)、SEED-I(视觉感知)以及POPE(衡量模型幻觉程度)等多个关键基准测试中,NEO均取得了高分,展现出优于其他原生VLM的综合性能,真正做到了精度无损。
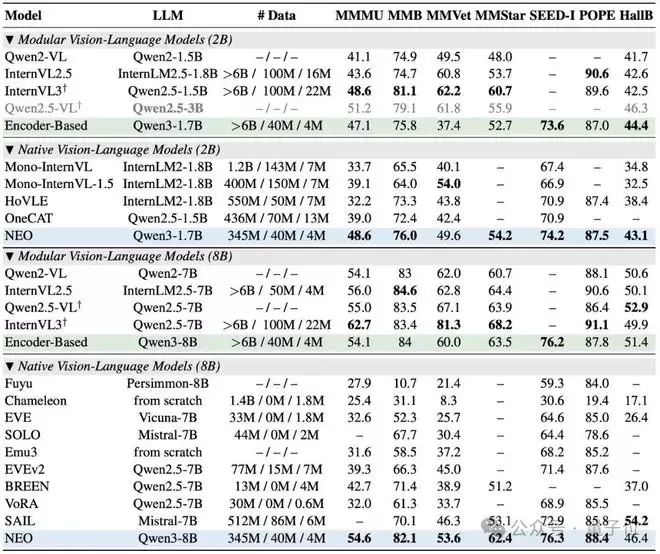
尤其值得注意的是,当前NEO在2B到8B的中小参数规模区间内,展现出了较高的推理性价比。
对于动辄数十B甚至上百B的大模型来说,这些中小模型似乎只是玩具。但正是这些模型,才是未来在手机、机器人、智能汽车等边缘设备上落地的关键。
NEO不仅在这些规模上实现了精度与效率的双重跃迁,更大幅降低了推理成本。
这意味着,强大的多模态视觉感知能力,将不再是云端大模型的专属,而是可以真正普及到每一个终端设备上。
如何评价NEO?
最后,我们还需要讨论一个问题:NEO有什么用?
从我们上述的内容不难看出,NEO真正的价值,不仅在于性能指标的突破,更在于它为多模态AI的演进指明了一条新路径。
它原生一体化的架构设计,从底层打通了视觉与语言的语义鸿沟,天然支持任意分辨率图像、长图文交错推理,并为视频理解、3D空间感知乃至具身智能等更高阶的多模态交互场景预留了清晰的扩展接口。
这种为融合而生的设计哲学,可以让它成为构建下一代通用人工智能系统的理想底座。
更关键的是,商汤已开源基于NEO架构的2B与9B两种规格模型,释放出强烈的共建信号。
这一举措有望推动整个开源社区从当前主流的模块拼接范式,向更高效、更统一的原生架构迁移,加速形成新一代多模态技术的事实标准。
与此同时,NEO在中小参数规模下展现出的性价比,正在打破大模型垄断高性能的固有认知。
它大幅降低了多模态模型的训练与部署门槛,使得强大的视觉理解能力不再局限于云端,而是可以真正下沉到机器人、智能汽车、AR/VR 眼镜、工业边缘设备等对成本、功耗和延迟高度敏感的终端场景。
从这个角度看,NEO不仅是一个技术模型,更是通向下一代普惠化、终端化、具身化AI基础设施的关键雏形。
更重要的是,NEO的出现,为当前迷茫的AI界提供了一个清晰而有力的答案。
在Ilya等人共同指出行业亟需新范式的当下,NEO以其彻底的原生设计理念,成为了“架构创新重于规模堆砌”这一新趋势的首个成功范例。
它不仅重新定义了多模态模型的构建方式,更向世界宣告:AI的下一站,是回归到对智能本质的探索,通过根本性的架构创新,去构建能真正理解并融通多维信息的通用大脑。
这一步,是中国团队对全球AI演进方向的一次关键性贡献。或如预言,这正是通往下一代AI的必经之路。