提到AI计算时,大家都知道,尤其在模型训练和推理过程中,并行计算是其核心运作方式。
AI计算中涉及的诸多算法,从矩阵乘法、卷积运算到循环层、梯度计算等,通常都要用成千上万的GPU以并行方式进行,才能有效压缩整体的计算时间。
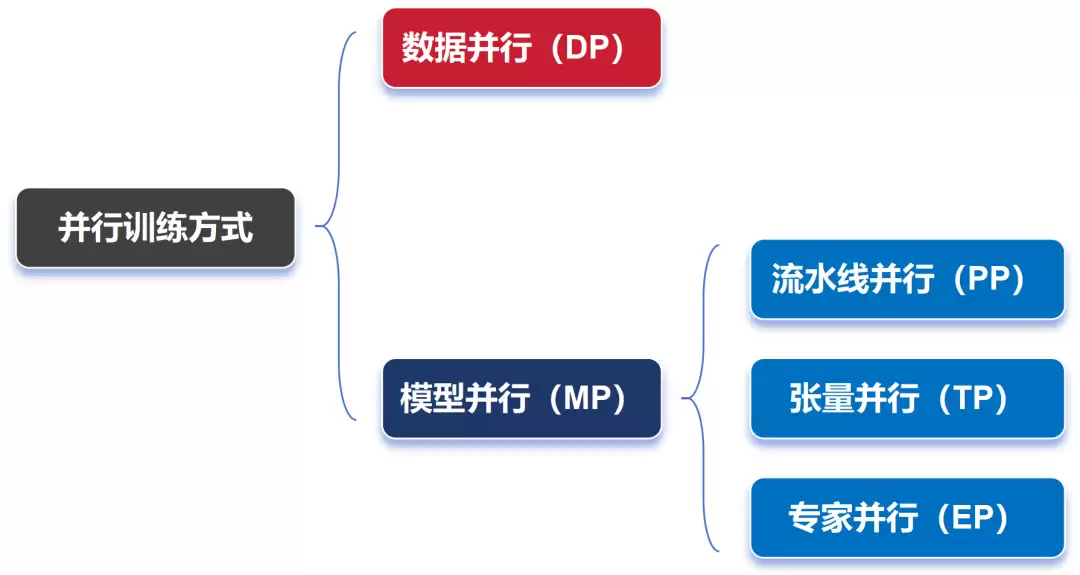
要搭建并行计算框架,一般离不开以下几种常见的并行策略:
Data Parallelism,数据并行
Pipeline Parallelism,流水线并行
Tensor Parallelism,张量并行
Expert Parallelism,专家并行
接下来,我们将逐一解析这些并行计算方法的基本原理。
▉ DP(数据并行)
我们先从DP,也就是数据并行(Data Parallelism)开始介绍。
在AI训练中所采用的并行方式,总的来说分为数据并行和模型并行两大类。刚才提到的PP(流水线并行)、TP(张量并行)与EP(专家并行),都属于模型并行的范畴,稍后会再做详细说明。
在深入了解之前,我们需要先大致把握神经网络训练的基本流程。简单来说,它包括以下几个主要步骤:
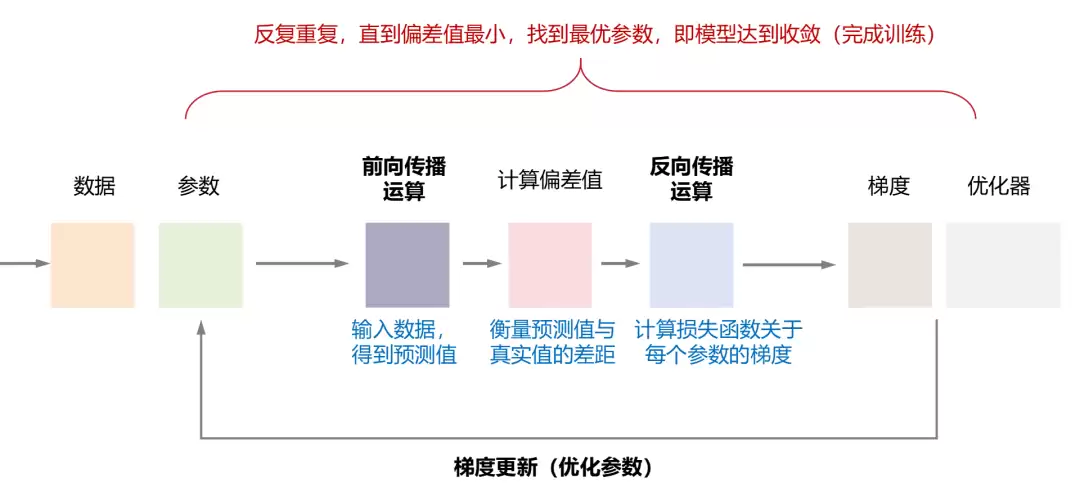
1、前向传播:输入一批训练数据,通过神经网络计算得到预测结果。
2、计算损失:利用损失函数比较预测结果与真实标签之间的误差。
3、反向传播:将损失值从输出层向输入层反向传递,计算网络中每个参数的梯度。
4、梯度更新:优化器根据计算出的梯度调整所有权重和偏置参数,实现模型的逐步优化。




