Chain-of-Thought 通过让大模型将思考过程显性化,已在多种复杂任务上验证了其有效性。然而,一个更深层的问题值得探讨:如果中间推理过程的主要接收者和处理者并非人类,而是另一个大模型,那么这种基于自然语言的长推理链,是否仍是最高效的中间表示形式?
导读
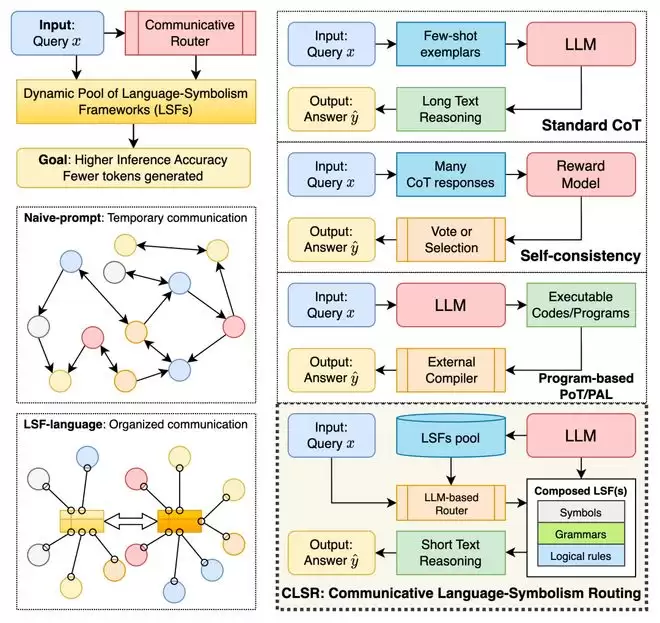
受此启发,本论文提出的 CLSR (Communicative Language Symbolism Routing) 提出了一个更根本的疑问:大模型是否必须依赖自然语言来组织其内部推理?
CLSR 认为,当多个大模型智能体在推理正确性与计算成本之间面临选择压力时,它们能够自主生成并演化出多样化的机器语言符号体系,即 Language Symbolism Frameworks(LSFs)。CLSR 正是针对这些语言符号体系设计的一套管理机制。实验表明,在多种推理基准测试及开源基座模型上,CLSR 通常能将面向延迟的生成端 completion tokens 降低约3–6倍,同时基本维持原始 CoT 的准确率水平,并在某些设置中实现了更优的 accuracy–token Pareto frontier。更重要的是,它开辟了一个值得深入探索的范式:提升推理效率的关键,不仅在于让模型“少说话”,更在于让模型使用信息密度更高、更易复用、更具路由能力的中间语言。
 0. 概要
0. 概要
CLSR 所探讨的“语言”,并非特指人类的自然语言,也并非宣称大模型获得了类人的语言能力。它指的是操作意义上的离散符号通信协议,简称为 LSF (Language Symbolism Framework)。CLSR 促使大模型多智能体系统在推理能力与能效的双重压力下,成批量地生成各种 LSF 协议。具体而言,在给定任务、模型族、token 预算和目标准确率的情况下,CLSR 能让系统生成、复用并自主演化出多套包含符号、语法、推理操作、有效性约束以及经验描述的中间表示(即 LSF)。这些 LSF 协议可以被灵活地调用、比较、路由、组合甚至淘汰,也能够用于后续任务。
因此,CLSR 旨在解决一个更具体、更具可实验性的问题:
在黑盒 LLM (black-box LLM) 设定下,我们能否自动发现一类离散、可归档、可复用的中间推理协议,使其在 accuracy–token frontier 上超越自然语言 CoT?
这个问题之所以至关重要,是因为当前的推理系统早已超越了单个模型一次性输出答案的简单模式。它们通常涉及多个角色(如求解器、路由器、批判者、验证器、工具使用者、聚合器)之间的交互与协作,这一过程产生的中间状态极为繁复。既然这些消息的主要处理者是机器,那么自然语言中为人类设计的可读性、修辞连贯性和解释性冗余,就可能成为额外的带宽成本。CLSR 的核心洞察,正是将“推理链”从一段文本重新定义为一种带宽受限的状态传输机制。
1. 问题背景:Chain-of-Thought 在推理精度与成本间的权衡困境
CoT 的成功源于一个朴素而强大的事实:面对复杂问题,显式地生成中间步骤,通常比直接输出答案更为稳定。无论是数学推导、科学问答、逻辑判断还是多跳检索,将中间状态外化都能降低一次性解码的难度。然而,CoT 也带来了结构性成本:它默认中间状态必须以自然语言文本 (prose) 的形式展开。
对人类而言,自然语言是理想的沟通接口,但对模型来说,却未必是最优的交互方式。标准的 CoT 充斥着“首先我们考虑……”、“因此可以看出……”、“为了验证答案,我们再检查……”等内容,这些对人类读者非常友好,但对于模型继续推理所需的最小状态而言,其信息密度可能偏低。尤其在自回归解码 (autoregressive decoding) 过程中,生成端的 token 数量不仅影响经济成本,更直接关系到延迟和吞吐量。
为缓解这一问题,现有方法主要沿着以下三条路径进行探索。
第一类是提示词优化 (prompt optimization),它优化自然语言指令的表面形式,以寻找更佳的提示词。这类方法具有价值,但优化的始终是临时性的“指令字符串”,而非一个持久可用的符号协议。
第二类是简洁推理提示 (short reasoning prompting),例如 Chain-of-Draft、Sketch-of-Thought、Compressed CoT 等。它们让模型减少书写量或采用草稿式推理。问题在于,简洁并非总等同于高效:如果压缩过程删除了关键的变量绑定、候选排除、证据链接或验证状态,准确率便会随之下降。
第三类是程序辅助推理 (program-aided reasoning),例如 PoT、PAL 等。它们将推理过程转化为程序,由外部解释器执行。这条路线在可程序化的任务上表现出色,但它依赖于人类预设的程序语言和外部执行器,并未直接回答“大模型自身能否发现适合自身的中间符号系统”这一问题。
CLSR 的切入路径与上述方法截然不同。它并未将 CoT 视作一段需要压缩的自然语言文本,而是将推理过程视为机器间的通信问题:
如果 token 是带宽,那么推理效率的本质就是:每个 token 能携带多少对答案有用的状态信息。
这一思路,将研究目标从“减少字数”转向了“提升单位 token 的有效信息密度”。
2. 理论视角
CLSR 论文中的一个关键思想,是将测试时的推理形式化为一个带约束的随机控制问题 (constrained stochastic control problem)。

CLSR 主要针对第二类操作。其目标是让模型发展出更紧凑、更结构化、更符合自身解码习惯的符号协议。这个视角也解释了为何“永远更短”并非正确目标。题目越难,所需的 token 量越大;目标准确率越高,允许的误差越小,所需的信息量也越多。因此,高效的推理系统必须能根据问题难度自适应地分配 token:简单题可以极度精简,难题则需要保留分解、验证和纠错的空间。
3. LSF:可复用的机器推理协议
CLSR 的基本单元是 Language Symbolism Framework,简称 LSF。论文中将一个 LSF 表示为:
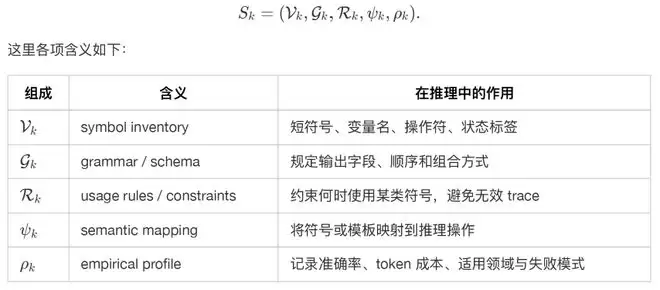
这个定义将 LSF 与普通 prompt 清晰地区分开来。Prompt 通常是一次性的自然语言指令,而 LSF 则更像一张“协议卡”。它可以被多次调用,可以在样本分布上进行评估,可以由路由器 (router) 选择或组合,也可以在演化过程中被继承、变异和淘汰。
更直观地说,一个面向数学的 LSF 可能会倾向于保留变量绑定、子目标、变形操作、校验标签和最终答案字段;一个面向科学问答的 LSF 可能更强调证据等级、候选排除、概念约束和简短验证;而一个面向多跳检索的 LSF 则可能保留证据桥、空值防护 (null guard)、支持状态 (support status) 和答案约定 (answer contract)。下面是一个概念示意,展示了 LSF 所追求的中间状态形态:
[bind] x=..., y=...
[sub] need: eliminate distractor B/C
[op] evidence(A) > evidence(D); constraint: mechanism match
[chk] no contradiction with condition-2
[ans] A
这类表达不追求文学性,也不追求对人类完全自解释。它追求的是:在尽可能少的 token 中,保留足以让模型继续推理、验证或输出答案的结构化状态。
4. CLSR 工作原理:生成、演化与路由
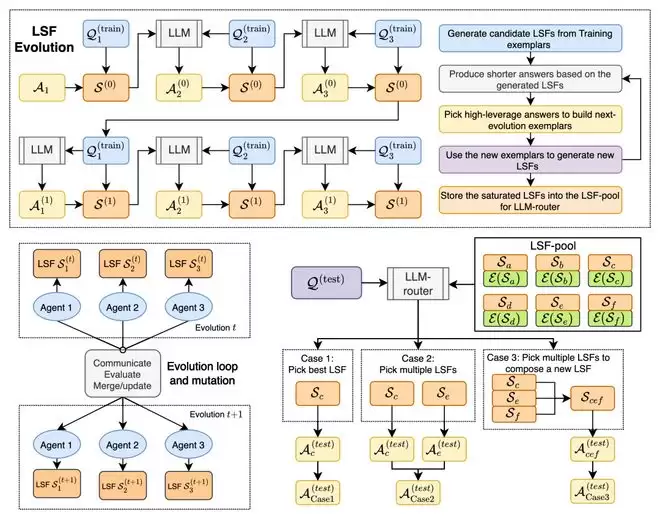
CLSR 的工作流程可分为三个阶段:LSF 合成 (LSF synthesis)、LSF 演化 (LSF evolution) 和测试时路由 (test-time routing)。
4.1 从样例中生成初始 LSF
给定基准测试的训练样例,CLSR 首先采样一批样本 (exemplars),并将它们作为上下文提供给大模型。模型被要求设计一种能在保持推理能力的同时减少 token 的 LSF。默认流程中,人类不对手工编辑符号表、语法或规则;只给出高层目标,即“保证正确性且节省token”。这一步主要是为了获得一个多样化的初始语言池。在较高的采样温度下,会产生一系列从严格 LSF (strict LSF) 到软 LSF (soft LSF) 的候选:前者更接近机器式的压缩协议,后者仍保留较多自然语言结构。
4.2 通过选择压力演化 LSF
随后,CLSR 使用一个迭代的引导过程 (bootstrapping process) 来逐代改进 LSF 池:用当前 LSF 回答新的训练/验证问题;记录答案正确性与 completion token 成本;选择那些同时正确且简洁的高杠杆踪迹 (high-leverage traces);将这些踪迹、父代 LSF 和失败信息反馈给大模型;生成下一代 LSF,并重复评估、选择、变异。
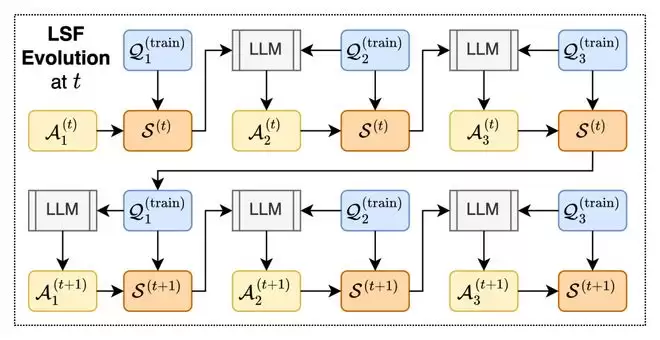
这里的“智能体”并非训练出的独立神经模块,而是由骨干模型 (backbone)、随机种子、样例子集和生成上下文定义的黑盒 LLM 提议/批判/变异工作器 (proposal/critique/mutation worker)。增加智能体数量,本质上是扩展了符号协议的搜索空间。这一过程类似一个小型的机器语言体系演化:正确性是通信成功度 (communicative success),token 长度是生产成本 (production cost),能反复被采用的符号与格式会被保留,不能稳定支持答案的压缩方式会被淘汰。这也解释了为何 CLSR 不等同于提示工程 (prompt engineering)——后者优化的是“如何向模型提问”,而 CLSR 优化的是“模型之间应该用什么协议来传递推理状态”。
4.3 测试时路由:让不同问题使用不同“方言”
在演化得到 LSF 池后,CLSR 在测试时并不会固定使用某一个 LSF,而是由 LLM 路由器 (LLM-router) 根据问题特征和 LSF 档案 (profile) 实时生成协议计划。主要有三类推理模式:
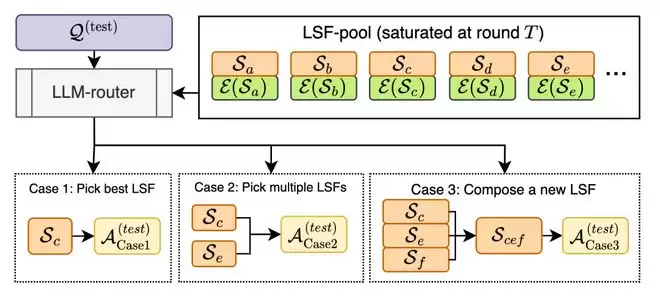
因此,CLSR 的目标并非简单地将所有回答压缩到最短,而是在预算约束下动态决定何时压缩、何时保留冗余、何时进行验证。对于简单题,一个低成本的 LSF 就足够;对于高难度推理题,路由器可以主动花费更多 token 来进行分解、交叉检查和多轮组合。这正是 CLSR 与普通短推理提示的核心区别:它优化的是路由策略与协议池,而非一个固定的长度风格。
5. 实验设置
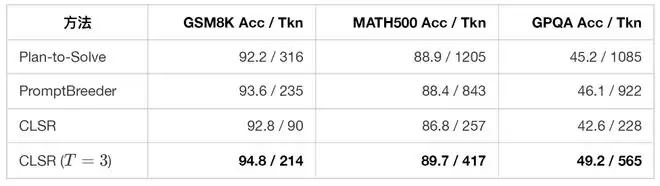
论文在七类基准测试上评估了 CLSR:MMLU-Pro、GPQA-main、GSM8K、MATH500、AIME21–24、ScienceQA、HotpotQA。这些任务覆盖了知识密集型问答、专家级科学问答、算术推理、竞赛数学、多选科学问答和多跳问答。骨干模型包括 LLaMA3-8B、DeepSeek-R1-Distill-Qwen3-8B、Qwen3-8B、Qwen3-32B 等开源模型。对比方法包括 Raw CoT、CoD、CCoT、SoT,以及 PoT、PAL、Plan-to-Solve、PromptBreeder 等程序化或提示词优化基线。评价指标主要是两个:Accuracy(最终答案准确率)和 Completion tokens(测试时生成端 token,包括 CLSR 的 LSF 响应、路由计划、中间响应和聚合等)。论文附录还探讨了在线测试中输入 token 和输出 token 的比例对实际延迟和推理成本的影响。
CLSR 的核心主张的准确表述是:
CLSR 在多模型、多任务上更稳定地将系统推向更好的 accuracy–token frontier:在接近 Raw CoT 准确率的同时,显著减少生成端 token;在相近 token 预算下,通常比简单短推理提示保留更多有效状态。
6. 主结果:CLSR 改善了 accuracy–token frontier
下表摘取了论文主表中的若干代表性结果。每个单元格为 Acc / Tkn,Tkn 表示平均生成 completion tokens。
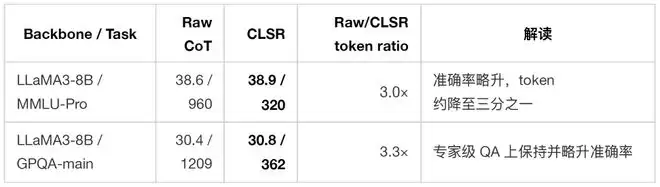
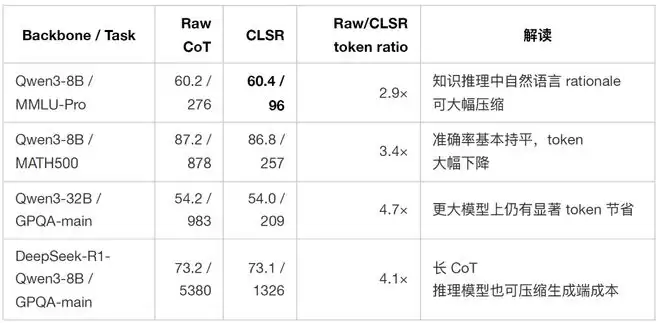
实验结果表明,CLSR 的收益并非仅来自小模型或简单任务。即使在强推理模型或长推理任务上,自然语言 CoT 中仍然存在大量对机器继续推理并非必要的表述。更关键的是,与短推理基线相比,CLSR 并非只是“更短”。以 Qwen3-8B 为例:
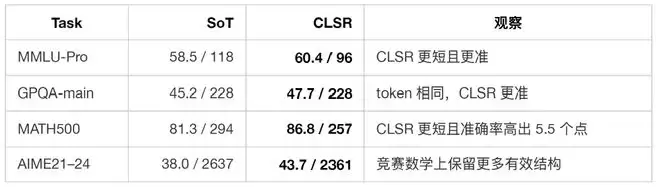
这组对比很能说明 CLSR 的本质:它并不是在自然语言 CoT 上做“文风压缩”,而是在寻找一种更合适的状态编码。短推理提示可能删掉了关键中间状态,而 LSF 则试图用更紧凑的符号保留这些状态。
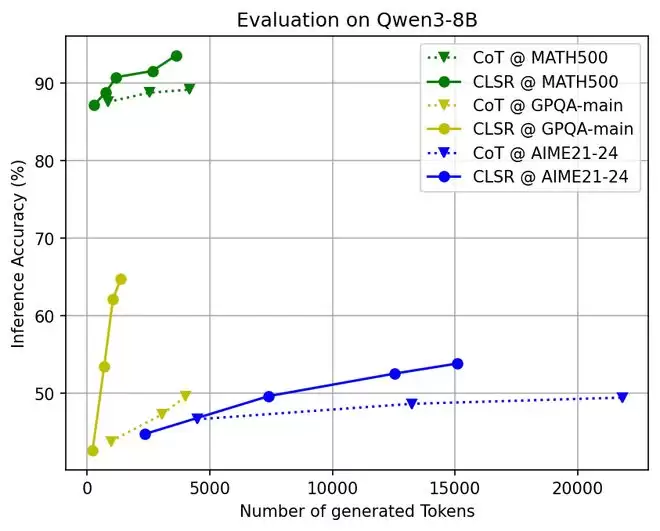
7. 机制分析一:CLSR 的收益来自“换码”,而非机械缩写
论文中的 accuracy–token 曲线显示,CLSR 在 MMLU-Pro、GPQA、GSM8K、MATH500 等任务上整体更接近帕累托前沿 (Pareto frontier)。
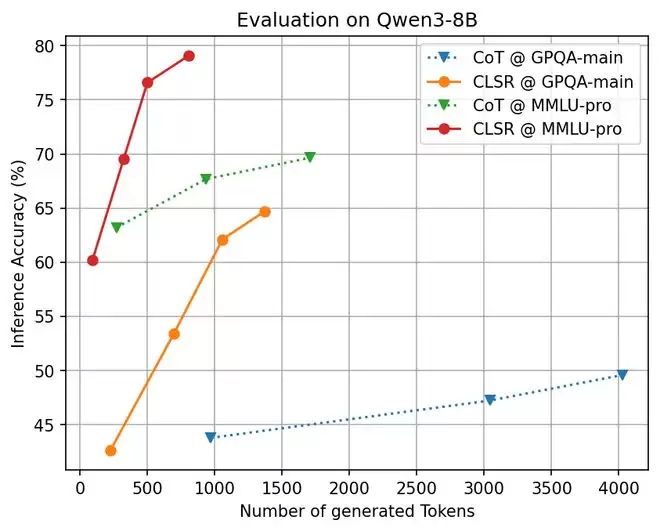
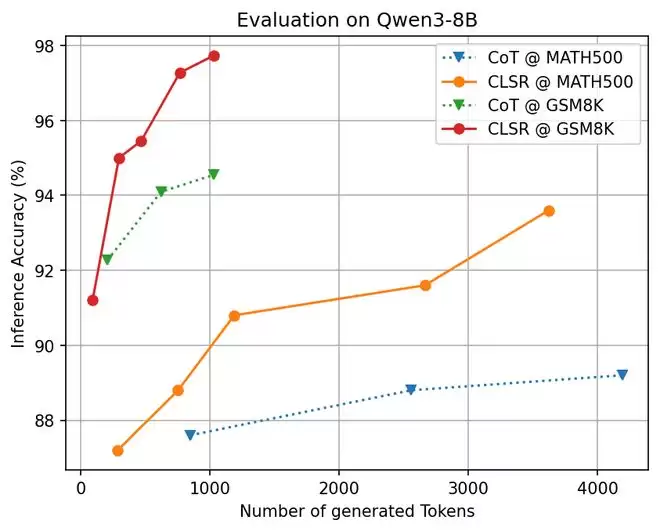
实验表明,当 token 预算增加时,CLSR 的额外 token 往往更能转化为准确率收益。这与理论中的分析一致:一个好的协议使得每个 token 更可能携带变量、约束、候选排除、证据绑定或验证状态,而不是重复的叙述。
在不同任务上,成功的 LSF 结构也各有不同:知识密集型 QA 的压缩重点是证据筛选、选项排除与短验证;数学推理的重点是变量绑定、等式变形、子目标与检查;多跳问答的重点是证据桥、支持状态、空值防护;格式敏感任务则关注输出约定与可解析性。这说明 LSF 是一组任务相关 (task-conditioned)、模型相关 (model-conditioned) 的推理协议。
8. 机制分析二:难题更需要将 token 用于验证环节
CLSR 的一个关键消融实验是多轮次 T。以 Qwen3-8B 为例:
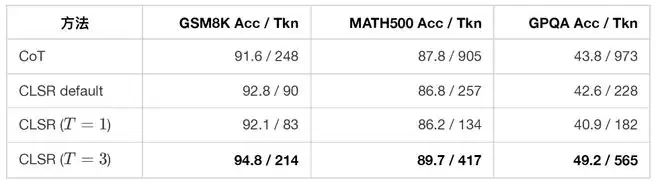
如果将 CLSR 理解为“让模型尽可能短”,那么 T=1 应该总是最优。但实验恰恰说明并非如此。对于 GSM8K、MATH500、GPQA,T=3 使用了更多 token,却显著提高了准确率,同时仍少于 Raw CoT。因此,对于高难度推理任务,CLSR 的原则不是“少说”,而是将 token 从自然语言叙述转移到结构化验证、分解和纠错上。这也是高强度推理任务中最有价值的启示。许多失败的压缩方法连验证环节也一并删掉了;CLSR 则通过路由器决定何时需要更严格的 LSF、何时需要多个 LSF 聚合、何时需要多轮组合。
9. 机制分析三:CLSR 与程序化推理的关系
程序化推理方法如 PoT 和 PAL 将推理转化为代码,再用外部解释器执行。CLSR 没有依赖外部执行器,但它通过多轮 LSF 协议,在一定条件下可以近似一种“模型内部的程序化状态更新”。论文也从理论上讨论了这种关系:在解释器可实现性 (interpreter-realizability) 前提下,多轮 LSF 协议可以条件性地包含程序执行流程 (program-execution pipeline)。
Qwen3-8B 上的比较如下:
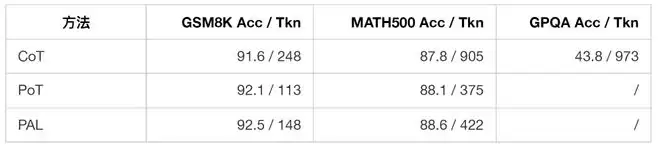
这里需要谨慎解读:PoT/PAL 的 token 统计只计算生成程序所用的 LLM 解码 token,并不等同于整个系统的所有执行成本;而 CLSR 的优势也不意味着外部执行器不再重要。对于严格数值计算、长程序执行、形式验证等任务,外部解释器仍有其独特价值。CLSR 的更准确定位是:当任务所需的符号操作仍在模型内部可实现范围内时,LSF 可以提供一种黑盒、离散、可归档、可路由的中间协议。它不替代所有程序执行,而是扩展了“自然语言 CoT”和“外部程序执行”之间的表示空间。
10. 定性样例:LSF trace 更像工作区
定性样例很好地展示了 CLSR 带来的改变。标准 CoT 往往像一段面向读者的解释文;而 CLSR 的踪迹 (trace) 更像一个压缩的工作区,保留了变量、操作、候选、检查与最终答案。
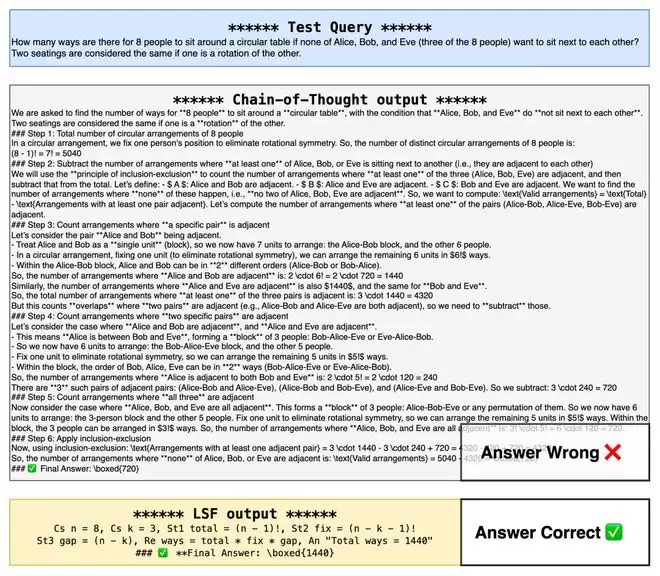
这类踪迹并非完全不可读。许多有效的 LSF 仍然借用了人类数学符号、短标签、箭头、括号、变量名和验证标记。原因显而易见:大模型预训练于人类文本与代码/数学语料,完全任意的乱码未必稳定;真正有效的机器方言往往是在“人类可读符号”和“机器压缩协议”之间形成的一种新的折中。这也构成一个值得注意的可解释性问题:LSF 比普通 CoT 更短、更结构化,但不一定更容易被非专业读者理解。因此,在实际系统中,更合理的设计可能是双层踪迹:内部用 LSF 高效推理,外部在需要时生成自然语言解释,并保留 LSF 卡片、路由计划、原始踪迹、解析答案和验证器日志以便审计。
11. 核心启示 (Takeaway messages)
CoT 的“长”,不全是推理本身。 CoT 的长度有两部分来源:一部分是解决问题确实需要的中间状态,另一部分是自然语言解释的表达成本。CLSR 的实验表明,在许多任务中,后者占比并不小。将这部分冗余替换为符号化状态,可以在不显著损害准确率的前提下减少生成端 token。
高效的 token 推理是表示学习问题,而非文本风格的控制问题。 “请简洁作答”只能改变表面文本风格;LSF 演化改变的是中间表示。真正有效的压缩必须回答:哪些变量必须保留?哪些候选必须排除?哪些证据需要绑定?哪些检查标签不可删除?这些不是单纯依靠长度约束能解决的问题。
没有一种机器方言对所有问题都是最优的。 简单题适合严格、低成本的 LSF;难题需要多轮组合和验证;科学问答与数学推导需要不同的状态结构;强模型和弱模型对同一种符号协议的适应性也不同。因此,CLSR 的关键不只是 LSF,还包括 LSF 池与查询自适应路由 (query-adaptive routing)。
小模型的能力不仅取决于参数,也取决于推理协议。 小模型常常被迫生成大量自然语言叙述,导致宝贵的 token 预算花在了低密度表达上。若将预算更多地用于结构化状态、验证和组合,小模型在特定任务上的 accuracy–token frontier 可以明显改善。这并非说 LSF 协议能替代模型能力,而是说明系统设计能显著改变能力的可用形态。
机器语言的价值在于可复用、可评估、可路由。 一个短踪迹只对一个样例有效,它只是压缩了答案;一个 LSF 能跨样例复用、能被档案评估、能被路由器选择、能与其他 LSF 组合,它才成为一个操作意义上的机器语言。
紧凑的推理踪迹并非万能。 更紧凑的协议同样会带来风险:过度压缩可能删除关键验证;符号踪迹可能降低人工可读性;不同模型之间的协议迁移可能出现负迁移;模型版本更新可能改变 LSF 的有效性。因此,CLSR 更适合作为一个可审计的协议层,而不是将所有内部思考隐藏在不可解释的短码中。
12. 从 CLSR 到机器方言学 (Machine Dialectology):机器方言不只是“自言自语”
CLSR 的续作是机器方言学 (Machine Dialectology, MDia)。如果说 CLSR 主要研究同类大模型智能体如何生成、演化和路由 LSF,那么 MDia 则进一步将问题扩展到异构 LLM 社会:不同模型可以是说话者 (speaker)、听者 (listener)、路由器 (router)、批判者 (critic)、工具使用者 (tool user);一种方言的价值不再仅仅取决于它对生成者是否有效,还取决于它能否被其他听者理解、采用、传播和改造。
MDia 的分析单位是一个 speaker–listener–dialect–task事件。每条事件都记录了查询、基准、说话者、听者、方言卡片、路由决策、响应、解析答案、标准答案、正确性、完成令牌、路由器令牌、延迟、随机种子和来源。这样,“机器方言”不再只是一个提示或踪迹,而成为可以统计、比较、路由和归档的社会语言学对象。
MDia 的核心结论是接收者相对效用 (receiver-relative utility):一种方言并非绝对强或弱,而是对某个听者、某类任务、某个预算条件强或弱。这一结论对多模型系统尤为重要,因为实际部署中我们常常关心的不是“哪个模型最强”,而是:哪个说话者产生的方言,最适合当前听者在当前任务和预算下使用?
MDia 的阶段性结果显示,在八个基准测试上,相比最强 token 减少基线,MDia 的宏平均准确率提升约3.6%,相比 Raw CoT 提升约3.1%,同时平均减少约71%的生成完成令牌。更重要的是,MDia 并非将所有方言无条件集成,而是通过档案感知路由 (profile-aware routing) 来识别公开性 (publicness)、开放性 (openness)、抵抗力 (resistance)、教学优势 (teaching advantage) 和外方言风险 (foreign-dialect risk)。

一个特别有启发性的实验是听者替换 (listener replacement):固定方言档案,替换听者,比较自方言路由 (self-dialect routing)、基于名称的路由 (name-based routing)、档案校准路由 (profile-calibrated routing) 等策略。MDia 稿件中档案校准路由的加权准确率从自方言路由的69.6%提升到了83.6%,平均生成令牌从879降到了449。这说明最强的方言并不一定是“自言自语”最强的,而可能是“对别人最有教学性”的。MDia 的规则库进一步抽象出一组机器社会语言学规律 (machine-sociolinguistic regularities),例如:听者开放性不对称(不同听者对外来方言的开放程度不同)、公开方言不对称(某些说话者产生的方言更容易被其他模型采用)、弱说话者教学性(较弱说话者有时能产生更稳定、更公共的教学方言)、外方言风险(外来方言可能因过度压缩或格式不匹配而损害强听者)以及路由简洁性(当档案候选方差较高时,简单的档案感知路由可能优于过度组合)。
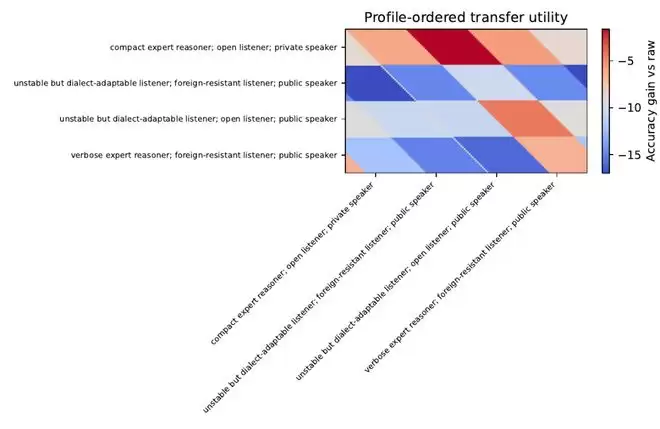
这使得 MDia 从“token 压缩”走向了“机器社会语言学”:研究机器之间如何发明、教学、借用、抵抗、迁移和路由符号协议。
13. 成果应用:Principia 与原则优先的想法发现
CLSR/MDia 的一个重要应用方向是科研创意发现系统 Principia。Principia 的设计哲学并非直接让模型生成一个看似新颖的提议,而是将研究创意拆解成可追踪、可验证、可复用的结构化对象。一个简化的流程如下:
research goal → relevant works → existed ideas → reusable principles → takeaway messages → evidence composition → symbolic derivation → Idea Card → comparison, validation, and export`
传统的头脑风暴工具往往产生流畅的文本,但很难回答:这个想法来自哪些文献?依赖哪些原则?假设是什么?与已有工作差异在哪里?风险在哪里?如何验证?Principia 试图将这些环节显式化,使想法发现从一次性生成变成一个带有谱系、证据、假设、风险和验证路径的工作流。
在此,CLSR/MDia 可作为推理协议层。具体来说,它们可能在三个层面帮助原则优先发现:第一,减少冗余的自然语言推理。许多科研探索流程需要反复比较文献、抽取机制、组合原则、生成假设。如果每一步都展开成长篇自然语言,token 预算很快会被解释性文本占满。LSF/MDia 可以将部分中间状态压缩成符号句柄 (symbolic handles)、推导补丁 (derivation patches) 和验证器检查 (verifier checks)。第二,提高中间对象的可复用性。科研想法的关键往往不是一次性的答案,而更重要的是可复用的原则、操作符、失败模式和验证模板。机器方言可以将这些对象组织成可路由、可组合的协议,而不是散落在上下文中的自然语言片段。第三,使小型开源模型在受控工作流中更有效。更好的 token 利用率虽然不能让小模型普遍等价于大型闭源模型,但在结构清晰、协议明确、证据可追踪的科研辅助环节中,它可能显著提高小模型的有效工作范围。这意味着,能力的提升不仅来自模型规模,也来自推理过程的组织方式。
从这个角度看,Principia 可以被理解为 CLSR/MDia 思想的一个应用场景:让大模型不仅可以回答问题,还可以发展出可复用的符号语言,用于组织原则、压缩推理、追踪证据、路由验证,并最终形成更可检验的研究假设。
14. 边界与开放问题:为何仍需谨慎推进
为避免过度解读,有必要明确 CLSR/MDia 当前的边界。
第一,LSF 并非完全脱离人类先验的新语言。大模型预训练已经吸收了自然语言、数学符号、代码格式和领域缩写。CLSR 的贡献并非证明模型从零发明了语言,而是证明在给定模型先验下,可以通过正确性与 token 成本选择出更适合机器推理的操作协议。
第二,紧凑踪迹不等于可靠解释。LSF 踪迹可能更结构化,但不一定能直接解释模型的内部因果机制。在高风险场景中,不能将短踪迹视为充分解释,仍需保留自然语言解释、路由记录、验证日志和可回放的协议卡。
第三,跨模型迁移并非总是正向。MDia 的外方言风险表明,外来方言有可能压制强听者原本丰富的推理过程,或引入不适合任务的格式约束。因此,机器方言需要档案感知路由,而非无条件共享。
第四,程序执行与形式系统仍然不可替代。对于需要精确计算、长程符号执行或形式证明的任务,外部工具与形式验证器仍有不可替代的优势。CLSR 更像是拓宽了中间表示空间,而非终结程序化推理。
第五,模型版本变化会影响方言稳定性。如果大模型的 tokenizer、指令跟随方式或解码偏好发生变化,旧 LSF 的有效性可能会下降。未来需要研究方言的版本化、回归测试、漂移检测与安全审计。
这些边界并不削弱 CLSR 的意义。相反,它们让研究问题更清晰:我们真正需要的是一套可测量、可审计、可演化的机器通信协议,而不是将压缩踪迹神秘化。
15. 小结:让模型少说,不如让模型自主演化出更合适的语言组织状态
CLSR 的重要性不在于提出了一个更短的 prompt,而在于重新定义了大模型推理系统中的中间表示。过去,我们常常将 CoT 视为模型推理能力的外显形式:写得越详细,似乎就越会推理。CLSR 说明,这个判断至少是不完整的。自然语言 CoT 的确有助于人类理解和模型分步推理,但它并非机器推理的唯一可行介质,也未必是 token 高效的介质。
CLSR 将问题从“如何让模型生成更短的 CoT?”推进到“如何让模型发展出更高信息密度、可复用、可路由、可传播的推理语言?”它给出的答案是:让大模型智能体自主生成 LSF,通过正确性与 token 成本进行演化选择,再在测试时根据问题路由、集成或组合这些 LSF。MDia 进一步将这一思想扩展到异构 LLM 社会,研究不同模型之间的方言迁移、公开性、开放性、抵抗性和路由策略。Principia 则尝试将这一路线放入科研创意发现系统中,让符号协议成为原则抽取、证据组合和想法推导的基础设施。
如果说 CoT 时代让我们看到“模型可以把思考写出来”,那么 CLSR/MDia 试图说明下一步可能是:高效推理系统不一定要求模型始终用人类自然语言思考;它们可以发展面向机器的符号方言,并在需要时将这些方言翻译给人类。这表明,我们可以将 token 效率从工程优化提升为表示学习与机器通信问题,也让我们重新思考:当模型越来越多地与模型协作时,真正重要的是它们能否用最合适的语言传递最关键的状态,而非它们是否足够拟人。
© THE END




