最近NVIDIA在GTC Taipei期间发布的RTX Spark超级芯片,确实在业内引起了不小的波澜,不少人称它标志着个人计算产业迎来了自图形加速时代以来最重大的变革。但有意思的是,这颗芯片的设计思路,与AMD那款“Strix Halo”锐龙AI Max 300系列处理器颇有几分神似。
搭载AMD锐龙AI Max+ 395处理器的设备,其实早在去年1月的CES上就已经亮相,如今更是成了不少AI迷你工作站乃至高端AI笔记本的“标配”。这两年,AI早已突破科技圈的边界,成为各行各业绕不开的话题,再加上今年这波“龙虾热”,AI产品和技术正快速渗透到工作和生活的各个角落。无论你是科技发烧友,还是普通玩家,可能都动过在本地部署一个专属AI智能体的念头。
正好,最近拿到了一台定位很明确的产品——联想百应AI主机300。这次我们就把这台桌面AI工作站彻底拆解一番,重点看看它在本地部署企业级AI智能体,以及综合性能上的真实表现。

一、外观设计
联想百应AI主机300在外观上走的是成熟、商务、极客的路线。整机以黑色为主基调,正面是一块带竖条纹理的悬浮式灰色面板,视觉上很有层次感。

机身四周被扎实的金属材质包裹,不仅提升了抗跌落和防冲撞的能力,也带来了更细腻的手感和品质感。

引人注意的是左右两侧的进气孔,采用了赛博科幻风格的波点设计,给略显单调的纯色机身增添了一抹灵动的点缀。

在尺寸控制上,这款迷你AI工作站体积大约在4.5升左右,实测长宽高尺寸为202×120×258mm。整机重量实测2.9kg,如果参照传统的迷你主机标准,这个分量显然不算轻,毕竟内部集成了一颗高达350W的内置电源模块,能做到这个体积已经相当紧凑了。日常摆在桌面上,倒是非常整洁利落。




接口配置上,联想百应AI主机300提供了相当丰富的前后I/O接口。前面板从下到上依次是:一个3.5mm音频复合接口、两个10Gbps的USB 3.2 Gen2 Type-A接口、一个支持40Gbps数据传输与DP 1.4视频输出的USB4 Type-C全功能接口,还有一个对摄影师和创作者极为友好的SD 4.0读卡器插槽。

正面还配备了一个带白色LED指示灯的电源开关按键,以及一个专用的性能模式切换按键,方便用户在工作负载变化时随时调整性能释放策略。

转到机身背面,接口阵容同样丰富。除了标准的AC C13电源输入接口外,还额外提供了一个3.5mm音频复合接口、一个支持2.5G速率的RJ45网络接口、一个10Gbps的USB 3.2 Gen2 Type-A接口,以及一个支持40Gbps与DP 1.4的USB4 Type-C接口。视频输出方面,还有一个DP 1.4接口和一个HDMI 2.1接口,以及两个USB 2.0 Type-A接口,方便连接键鼠等外设。


整体来看,联想百应AI主机300机身沉稳紧凑,金属材质搭配黑色机身,商务气质里又透着点极客元素,是一款低调百搭的迷你AI主机。
二、性能概述
这台机器最大的看点,自然是搭载了AMD的旗舰芯片——锐龙AI Max+ 395。这款处理器采用全新的Zen 5架构,领先的4nm制程,拥有16核32线程,最高频率可达5.1GHz,配备80MB缓存,规格十分强悍。
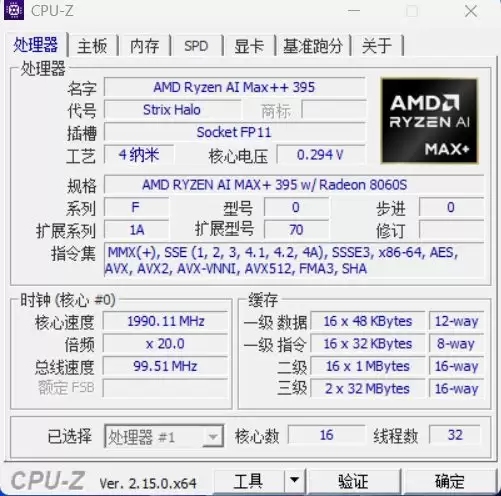
它集成的Radeon 8060S显卡拥有40个RDNA 3.5架构计算单元,cTDP范围在45-120W之间,性能可以平替RTX 4070独显,能在1080p分辨率下流畅运行主流游戏,同时支持四台显示器输出,最高支持8K UHD,并能高效编解码多种视频格式。

NPU方面,全新的XDNA 2架构带来了50 TOPS的AI算力。根据最新资料,在Windows 11 AI+PC上,其GPU在LM Studio里的AI性能甚至比桌面端的RTX 4090独显还要高出2.2倍,功耗却降低了87%。

内存和存储方面的配置同样亮眼。为了支撑大参数AI模型对内存带宽和容量的极致需求,联想百应AI主机300板载了高达128GB的LPDDR5x超高频内存。通过统一内存架构和AMD可变显存技术,CPU、NPU和集成显卡可以共享这128GB的海量内存,最高还能分配96GB给显存,数据直接在芯片内部的总线上流转,实现了零拷贝的低延迟体验。这套架构也让整机功耗降低30%以上,数据处理延迟大幅缩短,彻底打破了超大模型无法在本地流畅部署的技术壁垒。
存储系统方面,标配了一块2TB容量的PCIe 4.0 NVMe高速固态硬盘,主板内部提供两个M.2 2280插槽,均支持PCIe 4.0 x4通道。

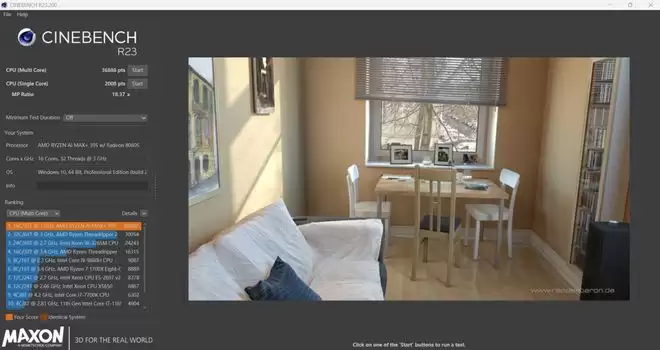
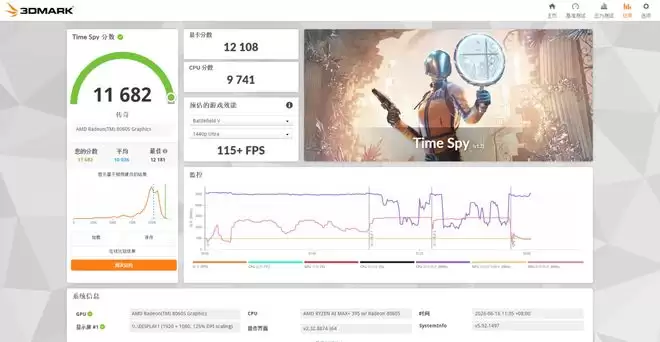
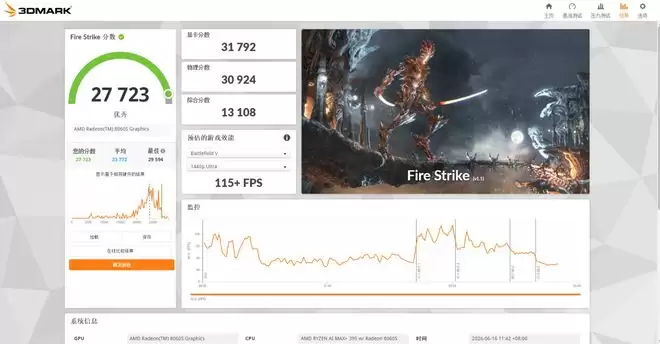
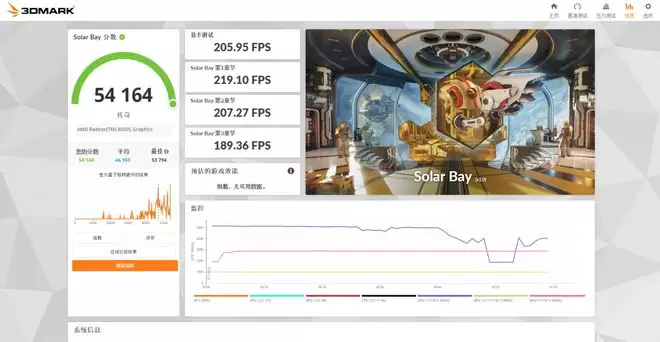
通过一系列基准性能测试,可以直观感受这款迷你主机的硬核实力。Cinebench R23中,单核2008pts,多核36886pts,表现十分顶级。CineBench 2024中,单核113pts,多核1887pts。GPU方面,3DMark Time Spy显卡得分12108,综合得分11682;Fire Strike显卡得分31792,综合得分27723;Solar Bay项目跑到205.95FPS,综合得分54164。无论是CPU还是GPU,锐龙AI Max+ 395的基准性能都相当亮眼,足以和中高端的游戏本一较高下。

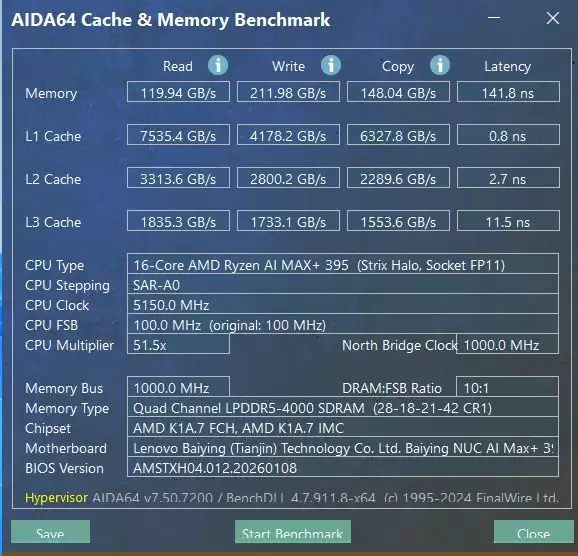
内存方面,AIDA64测试显示读取速度119.94GB/s,写入速度211.98GB/s,拷贝速度148.04GB/s,时延141.8ns。CrystalDiskMark测得SSD在SEQ1M Q8T1项目中读取7010.44MB/s,写入6303.56MB/s。
三、AI功能体验
锐龙AI Max+ 395为大模型量身打造的算力,让以往不能在本地部署的超大模型,在这台工作站上都能顺利运行,这对AI初学者、开发者乃至企业用户来说都非常友好。接下来重点体验在本地部署各类AI模型和智能体的实际表现。
1、OpenClaw本地部署与联想百应Claw体验
这台主机的核心卖点之一是本地优先的数据安全策略。所有AI推理计算都在本地完成,敏感数据完全不需要上传云端,极大程度满足了政企、医疗等行业对数据安全与合规性的要求。
实测中,先在本地部署了OpenClaw,然后通过Ollama部署了Qwen3.6 35B的超大模型,让OpenClaw调用本地大模型。给OpenClaw发了一个任务:整理当天全网科技圈热点最高的20条新闻,并整理成Excel表格保存在“文档”文件夹。
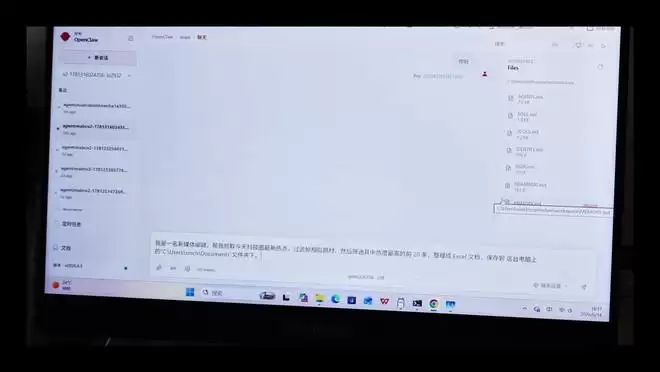
经过大约8分钟,OpenClaw顺利完成了任务。不仅成功整理出20条新闻热点,还按热度分了等级,并将Excel保存在了指定文件夹。
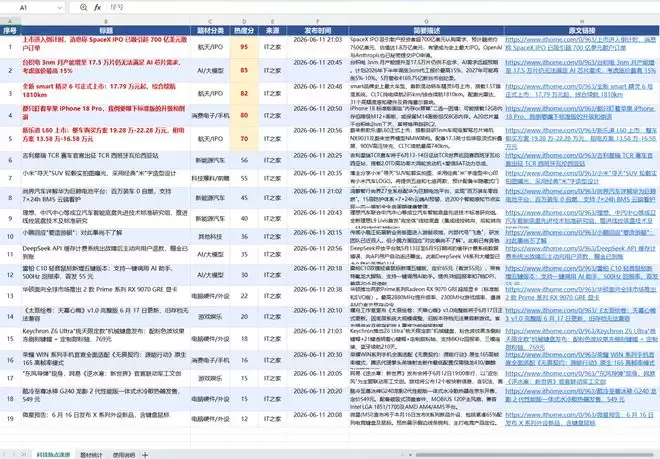
测试过程中,打开Windows性能管理器,可以看到32GB内存和96GB显存占用都很高,任务全程在本地运行。
35B参数的超大模型本地运行,效果相当出色。
为了降低上手门槛,联想百应AI主机300内置了联想百应AI平台,支持一键部署私有知识库与OpenClaw企业级AI智能体。本地部署OpenClaw并不复杂:打开联想百应App,点击立即部署,系统会自动下载所需环境文件与依赖包。下载完成后,可以在直观界面中选择模型供应商和默认模型。如果已经在本地部署了OpenClaw,也可以让联想百应一键接管,全程只需要两三步,非常方便。
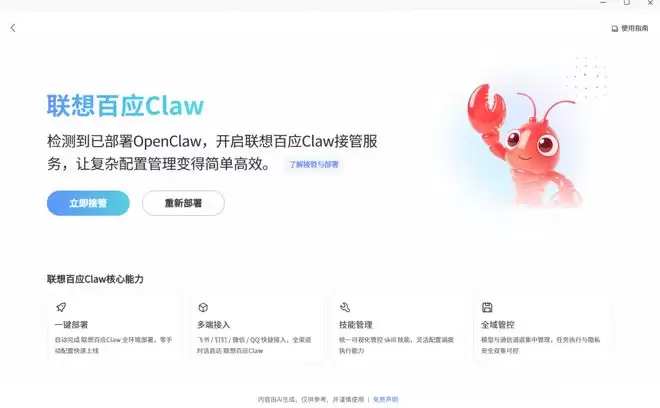
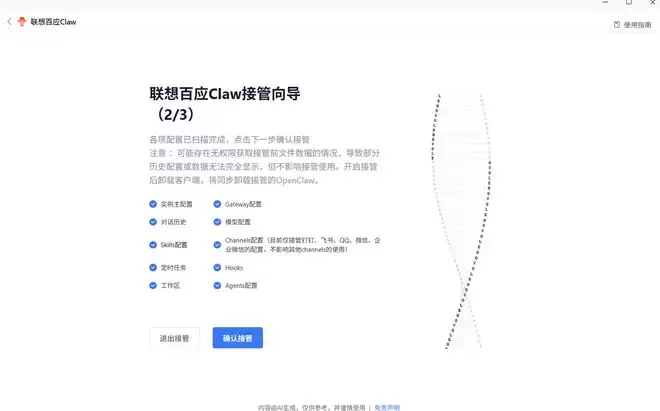
相较于直接在本地运行OpenClaw,联想百应Claw提供了很多一键即可实现的快捷功能。比如创建龙虾Agent,只需填写名称、身份描述、添加技能即可快速创建。技能方面,联想百应Claw内置了丰富的选项,都是一键添加。创建完成后,可以在对话框左下角切换。

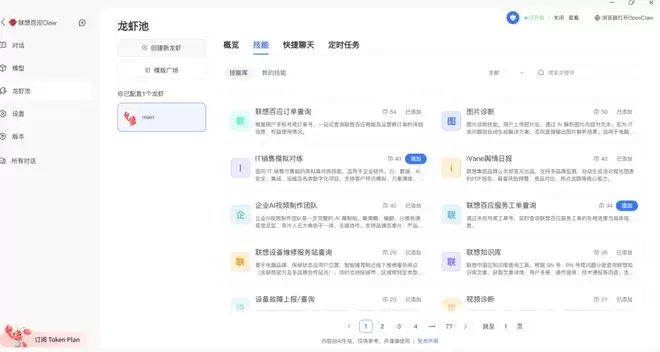
还可以将联想百应Claw快捷接入钉钉、飞书、微信、企业微信、QQ等平台,让它成为办公或生活的智能助手。
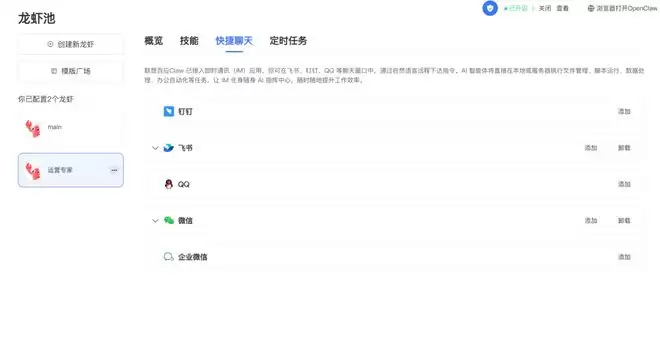
以微信为例,接入过程很简单,根据操作指引扫码,两步即可完成。接入后,微信上就多出一个微信ClawBot。
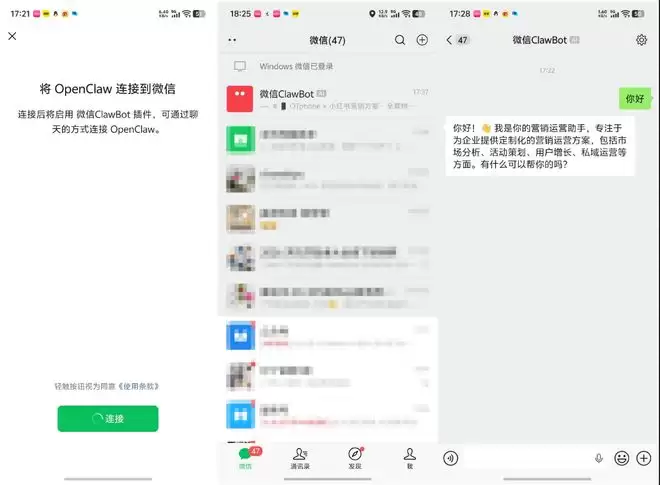
在微信上对微信ClawBot发起任务:设计一套针对某款手机的小红书平台完整营销方案。虽然是在微信上发起,但由于接入的是联想百应Claw,整个过程也是本地运行的,内存和显存占用都超过了50%和70%。
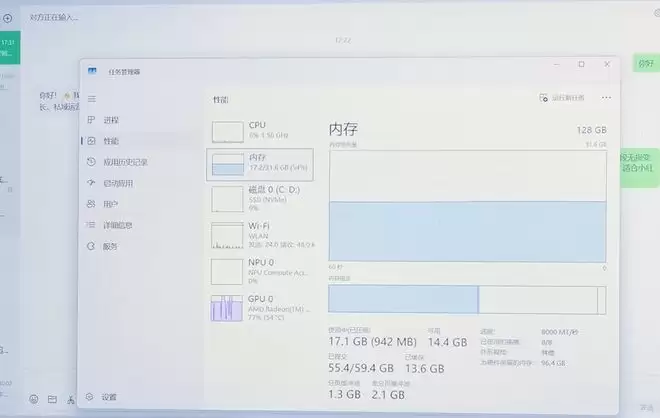
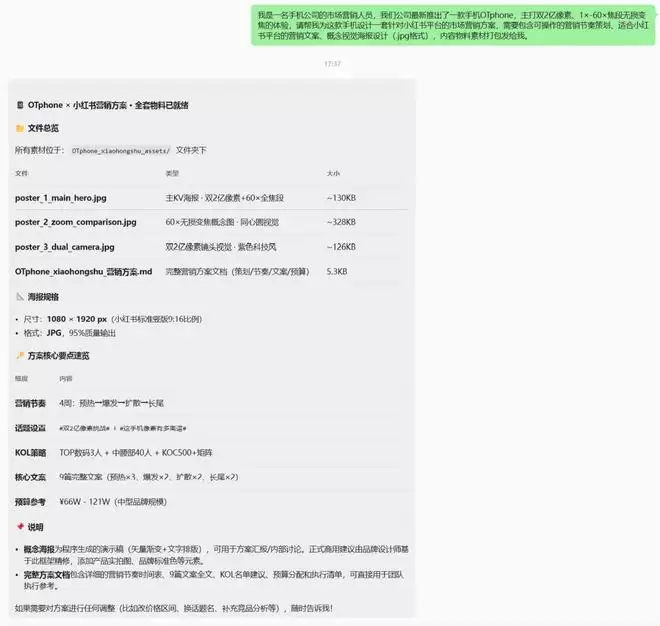
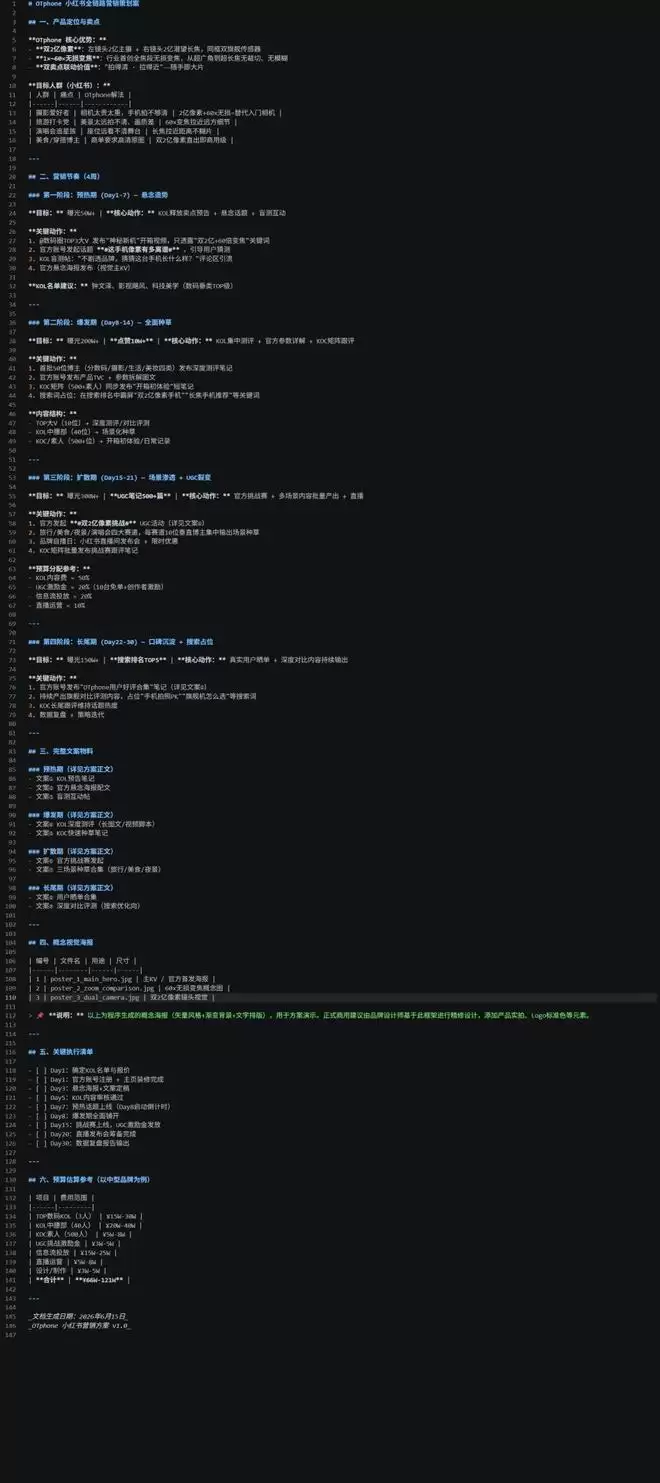
在微信上看不到执行过程,大约6分钟后,运营专家龙虾智能体完成任务并返回结果。可以看到,整套营销方案设计得完整全面,具有很强的可操作性,同时还生成了3张海报。所有工作完全在本地完成,得益于锐龙AI Max+ 395的强大性能、统一内存架构和AI算力支持,联想百应将“养龙虾”这件事放在终端侧,对于隐私敏感型的任务,可以放心交给龙虾去执行。

如果需要云端模型算力,也可以在联想百应上切换云端模型并购买Token Plan,配合本地模型,实现端云结合的体验。
2、不同参数量本地大语言模型运行测试
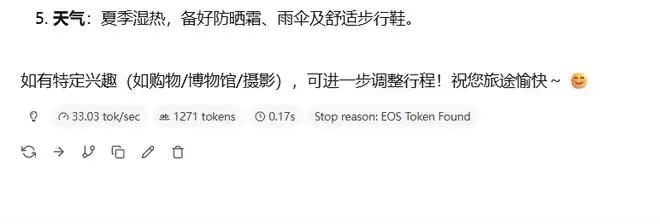
使用LM Studio装载各种参数量的本地大语言模型进行测试。先测试Qwen3.5 9B模型,问它一个关于上海旅游攻略的问题,大模型很快完成了回答,具体而详细。这次回答输出1271 tokens,速度33.03 tok/s,延迟0.17s。

接着切换到Qwen 3.6 35B模型,回答更加详细,还提供了表格和各种避坑要点。关键是,这次输出了4752个tokens,速度61.66 tok/s,比9B模型更快。大参数模型在更好的优化和量化技术下,运行效率反而更出色。

为了进一步压榨潜力,尝试运行了参数量高达120B的OpenAI开源超大模型GPT-OSS。加载时,系统分配的32GB内存占用飙到99%,但得益于锐龙AI Max+ 395的超大容量256bit四通道高速统一内存架构,机器还是顺利稳定地将模型跑了起来。
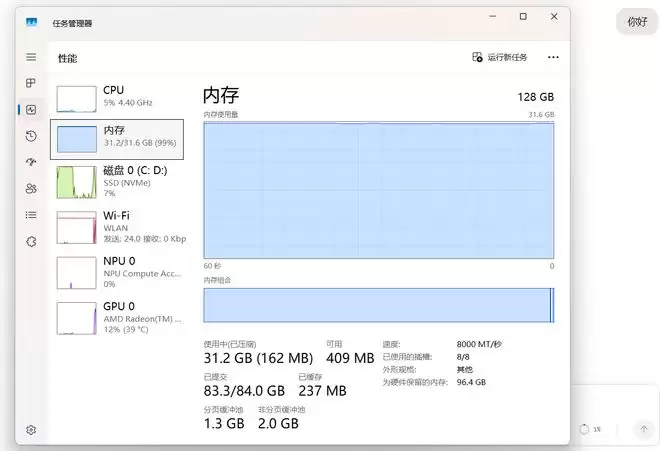
测试中,GPT-OSS模型的回答流畅详细,擅长使用表格,条理清晰。在运行120B超大模型时,联想百应AI主机300依然能实现38.67 tok/s的生成速度,总共生成4260个tokens,延迟0.47s。这个表现对过去的个人PC或主机来说,几乎难以想象。

3、本地大模型的创意内容生成体验
除了文本类大语言模型,也在本地部署并运行了流行的通用AI图像平台ComfyUI,搭建一个文生图工作流进行测试。使用Zimage-Turbo -fp8模型,生成一张亚洲男子在街头打电话的图片,提示词指令详细,分辨率1328×1328,迭代步数8步。图片生成时间约1分10秒,品质很高,完全符合复杂提示词的要求。
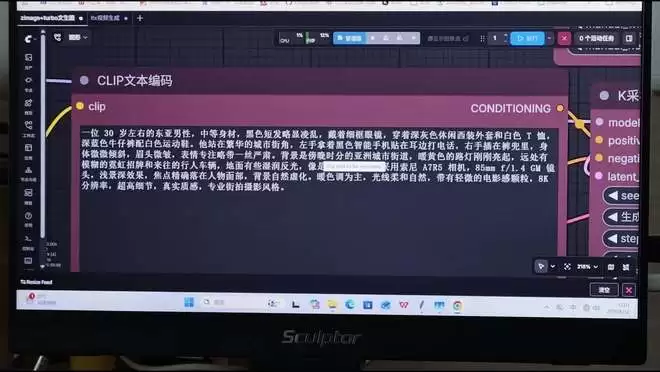
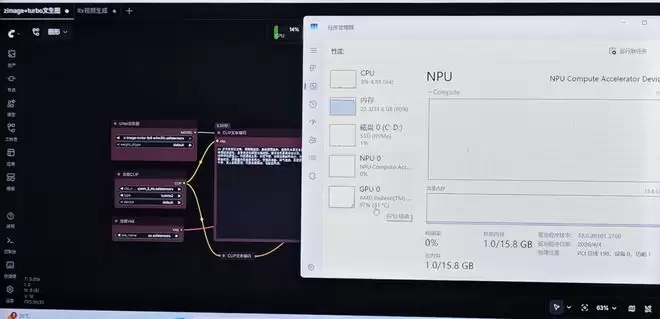
运行过程中,内存分配96GB、显存32GB,占用都在20%左右,全程断网。
接着将显存分配到96GB、内存分配到32GB,再次运行,生成女子在河边散步的图片,生成时间与上次差不多。这充分说明,锐龙AI Max+ 395的能力远不止此,完全可以加大AI工作负载,进一步提升分辨率或迭代步数。
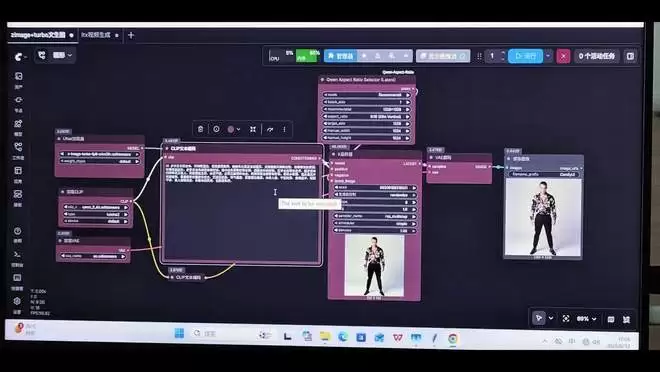
生图过程中,内存和显存占用最高到80%和97%,但很快回落。生成的图片质量非常高,精致、真实、充满细节。
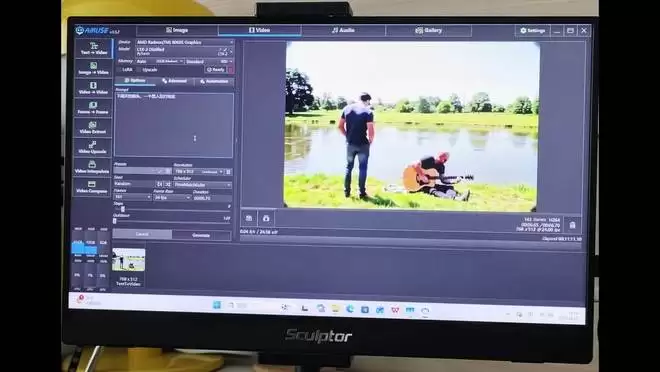
除了文生图,还测试了本地文生视频。使用Amuse v3.5.2软件,模型为LTX-2-Disstilled。生成一段下雨天街头男人打电话的视频,6.7秒的视频耗时约11分钟,共161帧,分辨率768×512,帧率24fps。生成过程中,96GB内存最高占用超75%,显存占用较低。考虑到视频生成模型对算力和显存的极致要求,这个速度表现相当出色。
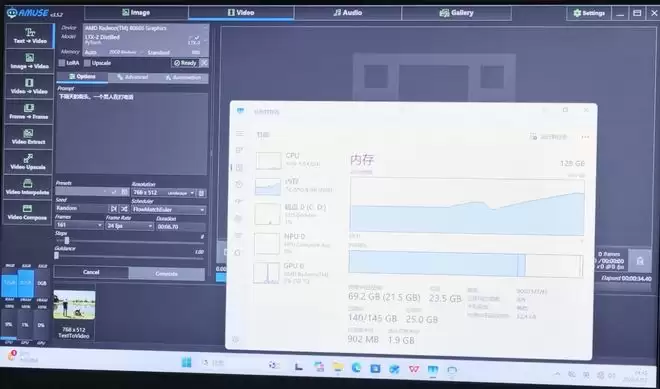

总体来看,128GB的超大统一内存在面对120B超大语言模型以及AI文生视频这类极度吃配置的任务时,与传统消费级独显设备相比,联想百应AI主机300的架构优势与海量内存红利彻底显现出来,完全避免了爆显存的尴尬。
结语
一圈测试下来,联想百应AI主机300的整体表现确实过硬。关键在于AMD锐龙AI Max+ 395芯片带来的128GB超大内存和四通道256bit LPDDR5x内存位宽,通过统一内存架构设计,最高可以分配96GB给显存,打破了桌面小主机无法胜任重度AI开发的刻板印象。海量的内存空间让它在本地部署百亿甚至千亿级别的大语言模型上,拥有目前绝大多数常规产品无法比拟的巨大优势。再加上联想定制的百应平台,可以一键无脑部署OpenClaw企业级智能体,对想零门槛体验和探索前沿AI应用的用户来说非常友好。
对于本身就具备开发能力的高阶玩家和极客而言,这台机器也可以顺手打造成纯本地的专属算力中心,从此跟高昂的云端算力账单和API调用额度说再见。

从行业落地视角来看,联想百应AI主机300在医疗、制造业以及更广泛的企业办公领域都有可观的应用场景。在医疗行业,病人数据不能上云,它可以化身为本地桌面影像智能诊断和病历录入大脑,辅助医生快速决策;在制造行业,通过异常数据或故障照片实时分析产线问题,实现预测性维护,减少停机损失;在企业进行私有智能体部署,也能自动生成周报、提炼会议重点、智能问答,化身全能AI助手;消费零售领域则更为常见,智能客服本地化,能实现对客户咨询的秒级响应,提升客户满意度。
联想百应AI主机300作为一款旗舰级主机,在京东平台自营店,128GB内存+2TB固态版本价格达到了26999元。这个定位,更适合那些对本地AI有真实刚需、已经开始用AI干活、并真正能提升工作和创作效率的用户——比如对本地数据隐私有极高要求的企业用户、开发者,以及预算充足的极客们。




