摩尔线程大模型对齐研究获国际认可:URPO框架入选AAAI 2026
11月13日消息,摩尔线程推出的新一代大语言模型对齐框架——URPO统一奖励与策略优化框架,相关研究论文近日被人工智能领域的国际顶级学术会议AAAI 2026收录,为简化大模型训练流程、突破模型性能上限提供了全新的技术路径。
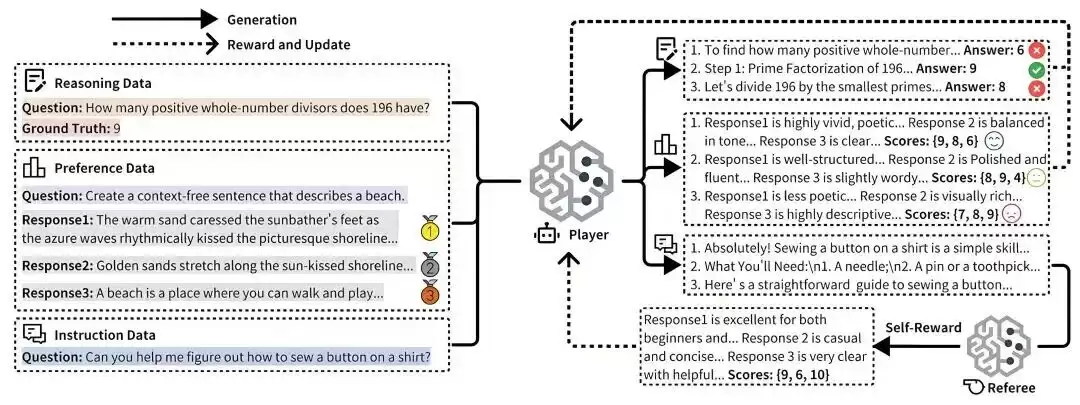
据介绍,在题为《URPO:A Unified Reward & Policy Optimization Framework for Large Language Models》的论文中,摩尔线程AI研究团队提出了URPO统一奖励与策略优化框架,将“指令遵循”(选手)和“奖励评判”(裁判)两大角色融合于单一模型中,并在统一训练阶段实现同步优化。URPO主要从以下三个方面攻克技术挑战:
数据格式统一:将异构的偏好数据、可验证推理数据和开放式指令数据,统一重构为适用于GRPO训练的信号格式。
自我奖励循环:针对开放式指令,模型生成多个候选回答后,自主调用其“裁判”角色进行评分,并将结果作为GRPO训练中的奖励信号,形成一个高效的自我改进循环。
协同进化机制:通过在同一批次中混合处理三类数据,模型的生成能力与评判能力得以协同进化。生成能力提升带动评判更精准,而精准评判进一步引导生成质量跃升,从而突破静态奖励模型的性能瓶颈。
实验结果显示,基于Qwen2.5-7B模型,URPO框架超越了依赖独立奖励模型的传统基线:在AlpacaEval指令跟随榜单上,得分从42.24提升至44.84;在综合推理能力测试中,平均分从32.66提升至35.66。作为训练过程中自然产生的“副产品”,该模型内部涌现出的评判能力在RewardBench奖励模型评测中取得了85.15的高分,表现优于其替代的专用奖励模型(83.55分)。
从摩尔线程最新获悉,目前URPO已在摩尔线程自研计算卡上实现稳定高效运行。同时,摩尔线程已完成VERL等主流强化学习框架的深度适配。
热门专题







热门推荐

ResearchRabbit 是一款设计理念独特的学术发现工具,它通过智能算法深度理解您的研究兴趣,并持续优化推荐相关的学术论文。其核心目标是帮助研究人员高效追踪所关注领域的最新动态与前沿进展。一个显著的亮点在于其智能通知机制:系统会主动筛选,仅推送高相关度的论文,对于不确定是否匹配您兴趣的内容则保

对于设计师和需要专业配色的用户而言,如何快速找到既美观又高效的色彩方案一直是个挑战。如今,借助人工智能技术,一些在线配色工具能够通过分析大众审美趋势,智能推荐最佳配色组合,让整个过程变得直观而高效。 这类工具的操作方法非常简单:打开网站即可直接开始。系统会基于你对多组配色方案的偏好选择进行学习,并实

在内容创作与SEO优化实践中,选择合适的工具是提升搜索引擎排名的关键一步。本文将深入解析Wordmetrics——一个融合人工智能与自然语言处理技术的智能内容优化平台,其核心功能在于协助用户高效创建与优化网页内容,从而在搜索结果中获得更靠前的位置。 该平台的工作原理十分智能:用户只需输入目标关键词,

Polymarket已完成CLOBv2迁移,修复了影响交易的“幽灵单”问题,并重构了底层订单簿系统以提升性能。平台已修正做市商返利,并将发放约50万美元的流动性奖励。开发者需及时更新抵押适配器合约地址,否则用户后续可能无法正常交易。

对于全球科研工作者而言,用非母语的英语进行学术写作是一项普遍挑战。Wisio作为一个由人工智能驱动的科学写作辅助平台,致力于通过多项智能化功能帮助研究者克服语言障碍。它能够提供符合学术规范的个性化文本润色建议,支持将多种语言的内容精准翻译为地道的科学英语,并能即时检索、引用最新的相关文献,从而显著提