11月7日,谷歌正式发布了Magika 1.0版本。这款基于人工智能的文件类型检测系统首次迎来稳定版,其内核已全面采用Rust语言重构,显著提升了运行效率和内存安全性。
谷歌表示,自去年初开放源代码以来,Magika已在开源社区获得广泛应用,月下载量突破百万次。本次更新不仅引入了全新架构,在性能表现上也有显著突破,同时增强了对多种文件格式的识别能力。

正如前面提到的,Magika 1.0最核心的改进在于其检测引擎已完成Rust语言的重写,从而实现更高的性能和内存安全保障。
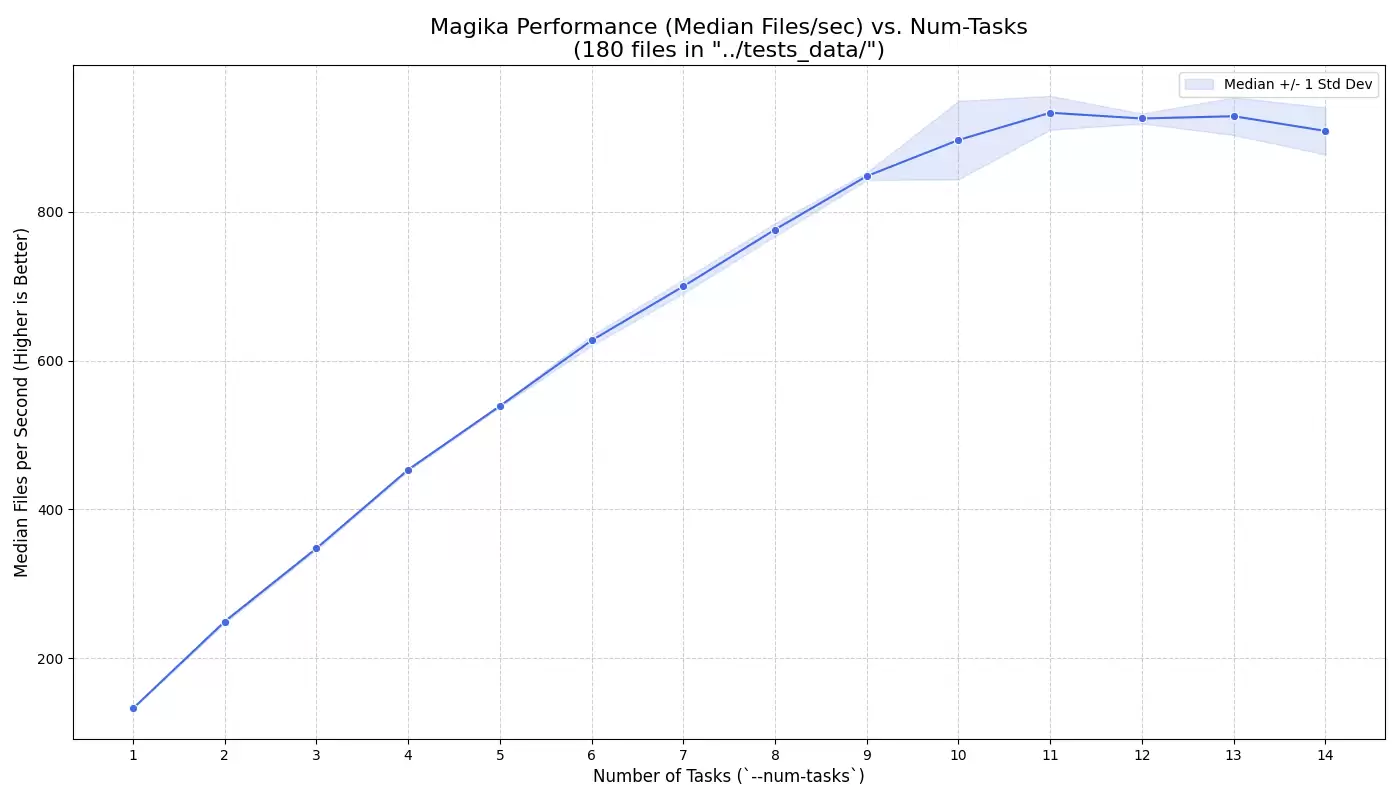
此外,新版本还提供了原生的Rust命令行工具,在单核环境下每秒可识别数百个文件,若在多核CPU上运行,处理速度更能提升至每秒数千个。
据介绍,该系统采用ONNX Runtime进行模型推理,并借助Tokio框架实现异步并行处理。谷歌公布的测试数据显示,在MacBook Pro(M4)设备上,Magika每秒可处理约1,000个文件。
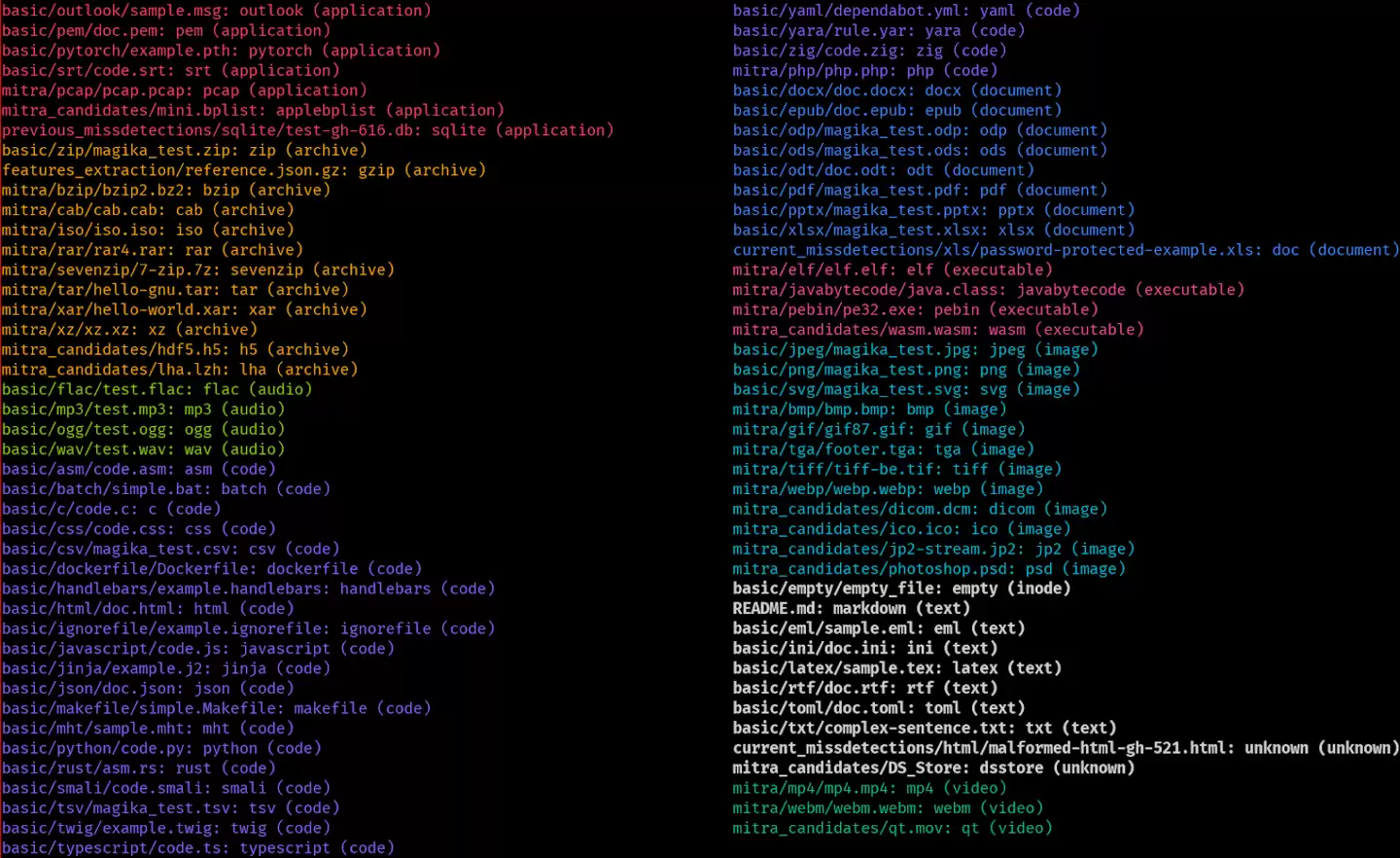
在支持的文件类型方面,Magika 1.0的检测范围已扩展至200多种文件格式,是初始版本的两倍。新增的类别包括:
数据科学与机器学习:支持Jupyter Notebooks(ipynb)、Numpy(npy, npz)、PyTorch(pytorch)、ONNX(onnx)、Apache Parquet(parquet)及HDF5(h5)等文件;
现代编程与网页开发:新增Swift、Kotlin、TypeScript、Dart、Solidity、WebAssembly(wasm)及Zig;
DevOps与配置文件:支持Dockerfile、TOML、HashiCorp HCL、Bazel构建文件及YARA规则等;
数据库与图形格式:新增SQLite、AutoCAD(dwg, dxf)、Photoshop(psd)以及现代网页字体(woff, woff2)等。
Magika 1.0还增强了对相似格式的区分能力,例如能够准确识别JSONL与JSON、TSV与CSV、Apple二进制plist与XML plist,还能区分C与C++、JavaScript与TypeScript等编程语言文件。
在技术实现层面,开发团队面临两大挑战:训练数据规模庞大与部分文件类型样本稀缺。未压缩的数据集超过3TB,为此谷歌采用自研的SedPack数据集库,通过流式加载与解压技术实现了高效训练。同时,针对样本不足的文件类型,研究团队使用生成式AI工具Gemini创建高质量的合成训练数据,将现有代码和结构化文件转换为其他格式,从而增强模型的泛化能力。
值得注意的是,新版本Magika还同步更新了Python与TypeScript模块,简化了开发者在各语言中的集成过程。用户可通过简单命令在Linux、macOS或Windows上安装原生客户端,也可通过pipx install magika安装Python包来使用Rust版命令行工具。
谷歌表示,Magika的未来发展将持续聚焦性能优化与文件类型扩展。团队欢迎开发者社区积极参与贡献,包括测试、功能请求及代码提交。




