字节Seed团队发布Ouro语言模型,Bengio签名支持预训练中「思考」
字节 Seed 团队联合多家机构推出了名为 Ouro 的新型预训练模型,它属于循环语言模型(Looped Language Models)类别,名称源于象征循环与自我吞噬的“衔尾蛇”(Ouroboros)神话意象。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
目前主流的大语言模型通常依赖显式的文本生成过程(例如“思维链”)来实现“思维”训练。这种策略将推理任务推迟到训练后的阶段,未能充分挖掘预训练数据中的潜力。
为解决这一问题,字节 Seed 团队联合多家机构推出了 Ouro 模型。这类循环语言模型通过创新架构,在预训练阶段直接构建推理能力。
Ouro 模型通过三个独特路径实现突破:(i)在潜在空间中进行迭代计算,(ii)采用熵正则化目标实现学习型深度分配,以及(iii)将训练数据规模扩展至 7.7T tokens,从而在预训练阶段就植入了推理能力。这些设计使得模型能够在预训练阶段直接学习和构建推理能力,而非仅仅依赖后期微调。

通过对照实验,研究者发现 Ouro 的性能提升并非源于知识存储量的增加,而是得益于其更高效的知识操控与推理能力。进一步分析表明,Ouro 的潜在推理过程相比标准 LLM 更接近真实的人类推理机制。
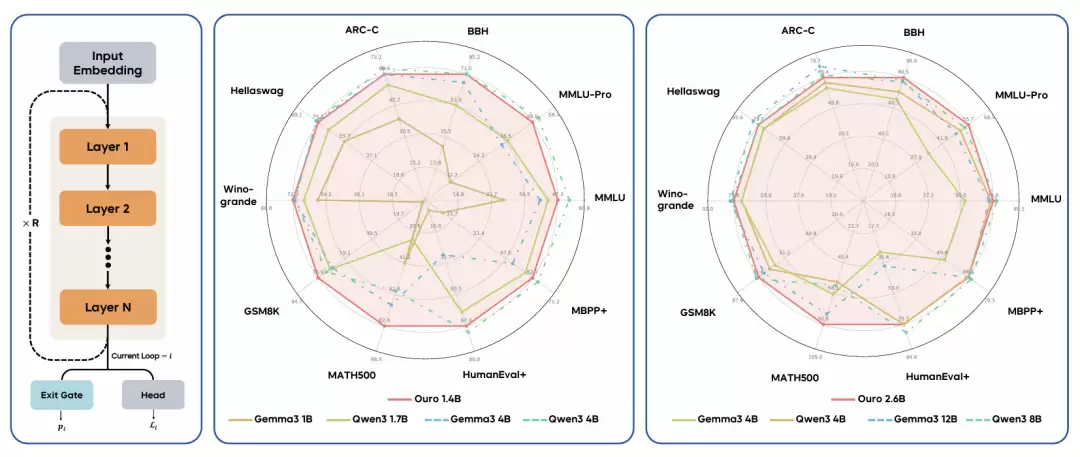
Ouro 循环语言模型的性能表现。(左)参数共享的循环架构。(中与右)雷达图比较了 Ouro 1.4B 与 2.6B 模型(均采用 4 个循环步,红色)与单独的 Transformer 基线模型。我们的模型展现出强劲性能,可与更大规模的基线模型相媲美,甚至在部分任务上实现超越。
最终,Ouro 的 1.4B 和 2.6B 参数规模的 LoopLM,分别能在几乎所有基准测试中达到与 4B 和 8B 标准 Transformer 相当的性能,实现了 2-3 倍的参数效率提升,显示了其在数据受限时代下作为一种新型扩展路径的潜力。
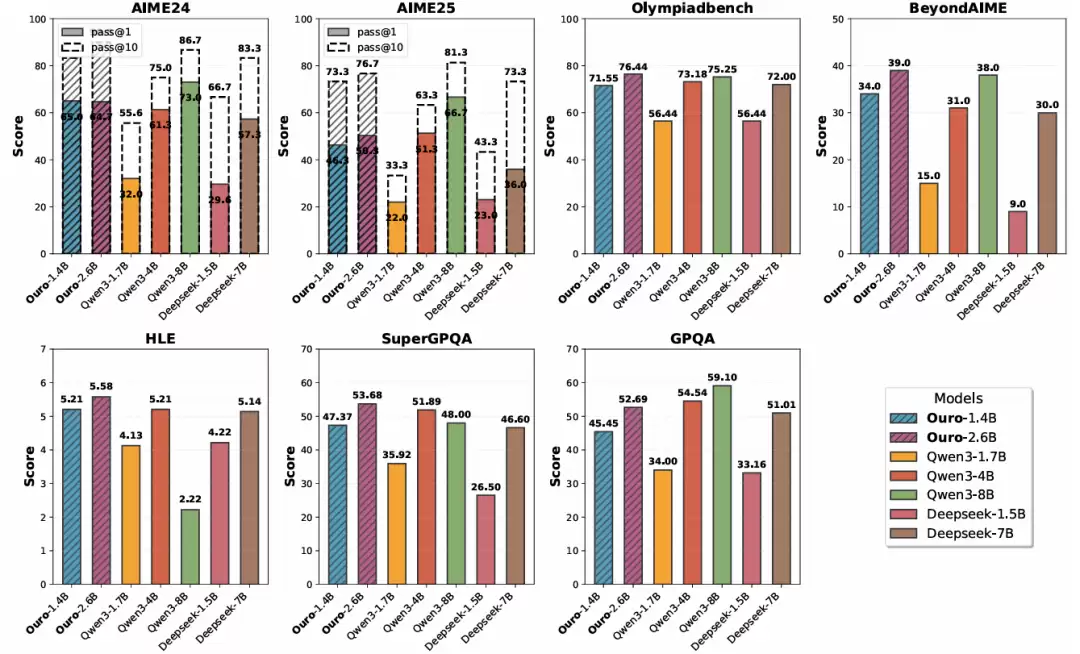
在高级推理基准测试中的表现。Ouro-Thinking 系列模型与强大的基线模型(如 Qwen3 和 DeepSeek-Distill)进行对比。Ouro-1.4B-Thinking R4 的性能可与 4B 规模模型相媲美,而 Ouro-2.6B-Thinking R4 在多个数学与科学数据集上的表现达到或超越了 8B 规模模型。
另外,LoopLM 架构在 HEx-PHI 基准上显著降低了有害性,且随着循环步数(包括外推步)增加,模型的安全性进一步提升。与传统的 CoT 方法不同,研究者的迭代潜变量更新机制产生的是因果一致的推理过程,而非事后的合理化解释。
循环架构
LoopLM 架构的灵感来源于“通用 Transformer”。其核心思想是在一个固定的参数预算内实现“动态计算”。具体而言,该架构包含一个由 N 个共享权重层组成的“层堆栈”。
在模型的前向传播过程中,这个共享的层堆栈会被循环应用多次,即经历多个“循环步”。这种设计将模型的计算规模从“参数数量”解耦到了“计算深度”。
该架构的关键特性是其自适应计算能力。它集成了一个学到的“退出门”,当模型处理输入时:简单输入可能会在经历较少的循环步后就提前退出,从而节省计算资源;复杂输入则会被自然地分配更多的迭代次数,以进行更深层次的处理。
这种迭代重用被视为一种“潜在推理”。与 CoT 在外部生成显式文本步骤不同,LoopLM 是在模型的内部隐藏状态中构建了一个“潜在思维链”。每一次循环都是对表征的逐步精炼,从而在不增加参数的情况下提升了模型的知识操控能力。
训练流程
Ouro 的训练流程是一个多阶段过程,总共使用了 7.7T tokens 的数据。
如图 4 所示,该流程始于一个通用的预热阶段,随后是使用 3T token 的初始稳定训练阶段。在此之后,模型通过“升级循环”策略分支为 1.4B 和 2.6B 两种参数规模的变体。
两种变体均独立经历后续四个相同的训练阶段:第二次稳定训练(3T token)、CT 退火(CT Annealing, 1.4T token)、用于长上下文的 LongCT(20B token)以及中途训练(Mid-Training, 300B token)。
这个过程产生了 Ouro-1.4B 和 Ouro-2.6B 两个基础模型。最后,为了强化特定能力,模型还额外经历了一个专门的推理监督微调阶段,以创造出专注于推理的 Ouro-Thinking 系列模型。
在训练稳定性方面,团队发现最初使用 8 个循环步会导致损失尖峰等不稳定问题,因此在后续阶段将循环步减少到 4,以此在计算深度和稳定性之间取得平衡。
为了让模型学会何时“提前退出”,训练流程采用了新颖的两阶段目标:
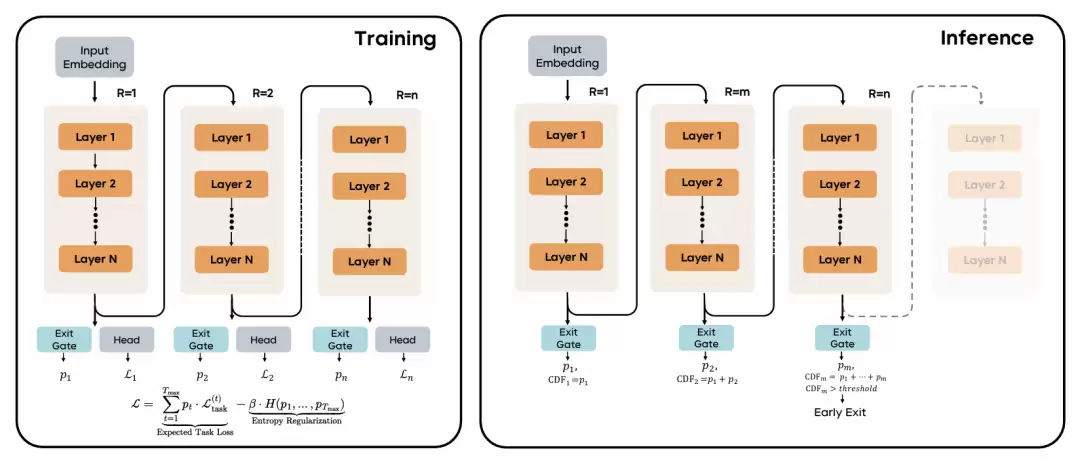
循环语言模型架构概览。
左图为训练阶段。在训练过程中,模型使用共享参数的 N 层堆叠结构,并执行 n 个循环步(R = 1 到 R = n)。在每个循环步 i,一个退出门预测退出概率 pᵢ,而语言建模头 Lᵢ 则计算对应的任务损失。训练目标函数结合了所有循环步的期望任务损失,并加入熵正则化项 H(p₁,…pₙ),以鼓励模型探索不同的计算深度。
右图为推理阶段。在推理时,模型可根据由退出概率计算得到的累积分布函数(CDF)提前终止。当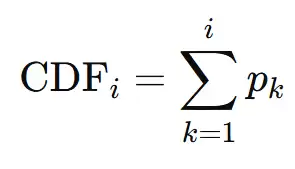 超过设定阈值时,模型将在第 i 个循环步停止,从而实现自适应计算:为复杂输入分配更多循环步数,同时在简单输入上保持高效推理。图中的虚线表示模型在提前退出后可能被跳过的后续步骤。
超过设定阈值时,模型将在第 i 个循环步停止,从而实现自适应计算:为复杂输入分配更多循环步数,同时在简单输入上保持高效推理。图中的虚线表示模型在提前退出后可能被跳过的后续步骤。
相关攻略

IT之家 4 月 1 日消息,谷歌 DeepMind 昨日推出 Veo 3 1 Lite 视频模型,是该公司迄今为止最实惠的视频生成工具。最新数据显示,Lite 版的生成速度和 Fast 版本保持一

今天傍晚,DeepSeek再度出现服务异常,社交平台上不少用户反馈,对话过程中频繁遭遇“请检查网络后重试”或“服务器繁忙”等提示。目前,服务已恢复正常。这是三天之内DeepSeek第二次发生服务故障

3月29日晚至30日上午,在经历长达12小时的宕机后,DeepSeek“崩”上热搜。大量用户反映网页端和App提示“服务器繁忙”或无法响应,据了解,这是DeepSeek有史以来最长的一次“罢工”。而

IT之家 3 月 31 日消息,小米创办人、董事长兼 CEO 雷军今日分享了 MiMo-V2-Pro 大模型最新“战绩”。在大模型权威评测榜单 Text Arena,MiMo-V2-Pro 凭借在复

3月31日,苹果于今日凌晨开始分批推送国行Apple Intelligence Beta版,需升级至iOS 26 4及以上系统方可体验。彭博社记者马克·古尔曼今日发文称Apple Intellig
热门专题







热门推荐

V社联合创始人G胖调整角色:从主导开发转向赋能团队,释放创意生产力 近期一则消息引发游戏行业广泛关注:Valve联合创始人加布·纽维尔(“G胖”)在公司内部进行了一次重要角色转型。此次调整的关键原因,与他个人在公司中的特殊影响力息息相关。根据透露,这位创始人决定减少在具体游戏开发工作中的直接深度参与

红魔姜超透露:全新游戏平板将于四月或五月发布,承诺带来惊艳体验 游戏硬件领域即将迎来重磅更新。努比亚红魔游戏手机的产品线负责人姜超,近日通过社交媒体进行了一次颇具悬念的“前瞻剧透”,成功引发了广大游戏玩家和科技爱好者的高度关注。他明确指出,红魔全新一代游戏平板的发布日期已锁定在四月或五月,并使用了“

金铲铲之战S17天煞羁绊:效果解析与实战应用 在《金铲铲之战》S17赛季中,【天煞】是一个定位独特的专属羁绊,仅由5费英雄“劫”所携带。激活这一羁绊需要特定的前置条件——玩家必须在强化符文选择阶段获得【入侵者劫】。一旦成功解锁,劫将获得全新的技能机制,从而在战局中发挥出颠覆性的作用。 金铲铲之战S1

索尼调整第一方工作室阵容,王牌重制团队蓝点工作室正式“退出”核心名单 近日,索尼在其PlayStation Studios官方网站的更新中做出了一项关键调整,引发了游戏玩家和行业观察者的广泛关注:曾凭借《恶魔之魂:重制版》等作品赢得盛誉的蓝点工作室,已不再出现在索尼核心第一方工作室的名单之中。此次页

未来人类X98W移动工作站正式发布:重新定义移动端专业性能的新标杆 在专业移动计算领域,总有一些产品能够打破常规认知。近日,未来人类(TerransForce)正式在其官网上线了全新的X98W高性能移动工作站,并宣布将于本月内全面发售。这款设备的问世,无疑为那些在移动办公环境中仍需要桌面级别强悍性能