On-Policy蒸馏策略:1/10成本训出专家级小模型
后训练成本高昂、小模型容易过拟合?来自 Thinking Machines Lab 的研究团队提出了 On-Policy Distillation 这一新范式,通过稠密监督信号与策略内采样优势相结合,实现了高效、稳定且低成本的模型能力迁移。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈

大家好,我是肆柒。今天我们来聊聊 Thinking Machines Lab 最新发表的前沿研究——《On-Policy Distillation》。这项工作巧妙融合了强化学习的策略内采样优势与知识蒸馏的监督信号,不仅将后训练成本降至传统强化学习方法的十分之一,还在数学推理、个性化助手与持续学习等关键应用场景中展现出卓越的性能与稳定性。如果你常为小模型难以复刻大模型那种专家级别的行为模式而苦恼,相信这篇文章会为你带来启发。
我们先来看一道具体的题目:
Prompt:Evaluate the limit:
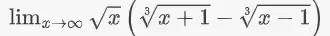
这道题的正确答案是 2/3,但其完整解决过程需要依赖多步代数技巧:首先要将立方根差有理化,然后再进行近似展开。如果模型在第一步就错误地合并了根号(例如误写为 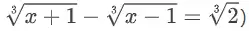 ),那么无论后续推导得多有条理,结果都已偏离正轨。
),那么无论后续推导得多有条理,结果都已偏离正轨。
在数学推理、医疗信息提取、企业知识问答等垂直领域中,一个经过精心训练的 8B 小模型经常能胜过通用的 70B 大模型。然而,如何让这些规模更小的模型真正具备“专家行为”呢?关键在于:我们能否高效地把大模型学习到的能力“教授”给小模型?
核心挑战:如何高效地将大模型的“专家能力”传授给小模型?
传统上存在着两种主流方法,各有优缺点:
以大型语言模型(LLM)的能力构建为例,一般要经历三个阶段:
预训练阶段:模型学习语言知识、常识与通用推理能力。这一步主要是让模型掌握通用的基本能力,包括理解和生成自然语言;同时培养广泛的推理能力,使模型能够进行常规的逻辑思考与判断;还包括基础的现实世界知识,让模型对生活中常见的事物、现象等有一定认知。
中期训练阶段:该阶段开始注入领域专业知识(如编程代码、医学数据库、公司内部文档等)。此时,会向模型传授特定领域的知识内容。例如代码,让模型能理解和生成编程相关的代码内容;医学数据库,帮助模型掌握医学领域的专业知识与数据;或者公司内部文档,使模型熟悉公司内部业务流程、规章等特定信息。
后期训练阶段:侧重于模型的行为对齐(例如指令遵循、数学推理格式、多轮对话风格等)。这一阶段的目标是激发模型产生特定的目标行为。比如遵循指令,模型需要能够按照给定的指示执行相应操作;进行数学推理,模型得有能力解决数学问题;或者进行对话交流,让模型具备与人进行自然沟通的能力。
热门专题







热门推荐

《全面战争:中世纪3》:经典延续,如何平衡怀旧与创新? 近期,《全面战争:中世纪3》的项目负责人帕维尔·沃伊斯坦然指出,要打造一款真正优秀的续作,绝不能仅仅依赖对前作模式的简单复刻。这一观点引人深思——尽管《中世纪2:全面战争》至今仍在策略游戏爱好者心中占据着经典地位,但开发团队此次显然决心跳出“照

雷鸟X3 Pro斩获AWE艾普兰创新大奖,开启全民AR生活新篇章 在上海新国际博览中心隆重揭幕的2026年中国家电及消费电子博览会(AWE)上,前沿AI科技与未来生活愿景激情碰撞。全球消费级AR领导品牌雷鸟创新,以其里程碑式的表现,定义了行业发展的新方向。 通过“顶尖硬件科技+顶级文化IP”的双轨战

借力AWE2026“一展双区”,MOVA双区协同、震撼登场 备受瞩目的科技盛会——2026年中国家电及消费电子博览会(AWE),于3月12日至15日在上海盛大举办。本届AWE展会首次创新采用“一展双区”的展览模式,主会场位于上海新国际博览中心,分会场则设于上海东方枢纽国际商务合作区,两大展区高效联动

冰结师技能全解析 踏入2026年,《地下城与勇士》中的冰结师职业,其技能体系已构建得更为成熟与强大。无论是在副本中高效清理海量怪物,还是在决斗场与高手玩家周旋,这个职业都能凭借其独特的冰霜艺术掌控战局。刷图时,酷寒的范围法术可瞬间清屏;而在PVP竞技中,一套将冻结控制与瞬间爆发完美衔接的连招,往往让

iPhone 18 Pro系列模具不变,屏幕形态将与iPhone 17 Pro保持一致 备受期待的屏下Face ID组件小型化设计与灵动岛区域缩窄方案,预计将被推迟至后续迭代机型中正式应用。 近期,关于iPhone 18 Pro系列的技术传闻持续引发行业关注,尤其在显示与解锁设计领域传言甚多。多方消