互联网时代,面对海量数据与高并发访问的挑战,采用高可用的微服务分层架构已成为解决方案的关键。通过三个简单步骤,就能轻松实现数据库的秒级平滑扩容,确保系统在数据激增时依然保持稳定。
关于数据库秒级平滑扩容的问题,之前我曾详细阐述过。上周有位朋友在评论区提到找不到原文,其实这个方法实操性很强,我们团队在58同城就曾成功实践过。
此外,理清思路往往比结论本身更为重要。

高吞吐、大并发场景下,互联网分层架构通常如何设计?
在数据库上层,微服务层负责记录“业务库”与“数据库实例配置”之间的映射关系。数据库连接池通过解析SQL语句,将查询请求精准路由到对应的数据库实例。
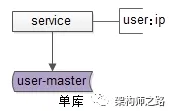
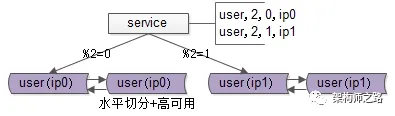
如上图所示,服务层通过配置用户库user与具体数据库实例IP的对应关系,实现数据访问的动态路由。
画外音:这里的IP实际上对应的是内网域名。
如何确保分层架构下数据库的高可用性?
实现数据库高可用,业界常用的方式是采用“双主同步+keepalived+虚拟IP”的方案。
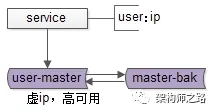
如图所示,两个互为主从的数据库实例共享同一个虚拟IP。
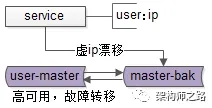
当任一主库发生故障时,虚拟IP会自动漂移到另一个健康的主库。整个过程对调用方完全透明,有效保障了数据库服务的高可用性。
画外音:关于高可用的实现细节,之前已专门介绍过,本文不再展开。
当数据量持续激增,架构应如何应对?
面对数据量的快速增长,数据库需要进行水平切分,将数据分布到不同的数据库实例(甚至物理服务器)上。通过分库降低单库数据量,既能提升系统性能,又能实现弹性扩容。
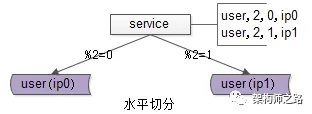
如上图所示,用户库user被分布到两个实例(ip0和ip1)上。服务层根据用户标识uid取模的方式进行路由:模2为0的访问ip0上的user库,模2为1的则访问ip1上的user库。
画外音:此时,水平切分集群的读写实例数量实现倍增,单个实例的数据量减半,性能提升可不止一倍。
综合以上三点,大型互联网微服务分层架构的整体设计思路如下:
这样的设计既实现了水平切分,又保证了高可用性。
若数据量持续增长,两个库性能达到瓶颈该怎么办?
此时需要继续进行水平拆分,将数据分布到更多的库中。通过增加库主实例数量,既能降低单库数据压力,又能有效提升整体性能。
新的问题随之而来:分成n个库后,随着数据量的进一步增加,需要扩容至2*n个库。如何在不中断服务的情况下实现数据平滑迁移,保证服务持续可用?
画外音:你遇到过类似的情况吗?
停机扩容,是最容易想到的方案吗?
在探讨秒级平滑扩容方案之前,先简要说明停机扩容的实施步骤:
(1) 发布公告“为给广大用户提供更优质服务,本站点/游戏将于今晚00:00-2:00期间进行升级,届时将无法登录,敬请知悉”;
画外音:这样的公告相信大家都见过,实际上这是在迁移数据。
(2) 微服务停止服务,数据库不再写入新数据;
(3) 新建2*n个新库,并配置高可用架构;
(4) 编写数据迁移脚本,将数据从n个库中select出来,再insert到2*n个新库中;
(5) 修改微服务的数据库路由配置,将模n改为模2*n;
(6) 微服务重启,连接新库重新对外提供服务;
整个过程耗时最长的就是第四步的数据迁移。
如果出现问题,如何快速回滚?
若数据迁移失败,或迁移后测试发现问题,只需将配置改回旧库,即可恢复服务。
停机扩容方案存在哪些优缺点?
优点:操作简单。
缺点:需要停止服务,方案可用性不高;技术团队压力大,所有操作必须在限定时间内完成。根据经验,压力越大越容易出错;
画外音:这一点尤为关键。
如果在服务启动后才发现问题,将难以回滚。一旦回档可能导致部分数据丢失。
有没有秒级实施、更平滑、更优雅的解决方案?
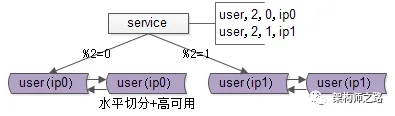
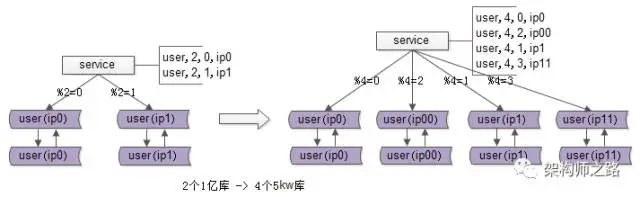
再次回顾扩容前的架构:假设每个库有1亿数据量,如何通过平滑扩容增加实例数量,降低单库数据量?只需三个简单步骤即可搞定。
步骤一:修改配置。
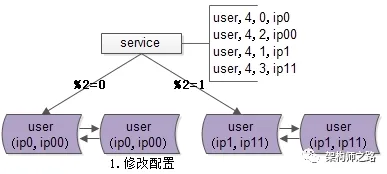
主要修改包括两个部分:
其一,为数据库实例所在的服务器配置双虚拟IP:原来模2=0的库增加虚拟IP00;模2=1的库增加虚拟IP11。
其二,修改服务配置,将原来2个库的数据库配置,调整为4个库的设置。修改时需特别注意旧库与新库的映射关系:模2=0的数据,将分布到模4=0与模4=2的实例上;模2=1的部分,则分布到模4=1与模4=3的实例上。
画外音:这样的配置能确保数据被路由到正确的数据库。
步骤二:reload配置,实现实例扩容。
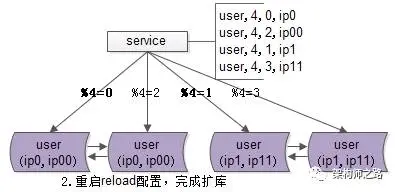
服务层reload配置,可以通过几种方式实现:最直接的是重启服务,重新读取配置文件;更高级的做法是通过配置中心给服务发信号,重读配置文件,重新初始化数据库连接池。
无论采用哪种方式,reload之后,原先由2个数据库实例提供服务,现在已扩展为4个实例共同支撑。这个过程通常在秒级即可完成。
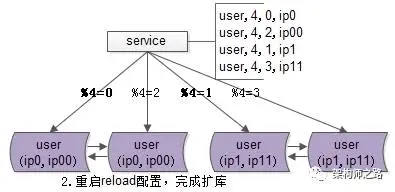
整个升级过程完全可以分段实施,既不影响服务的正确性,也不损害可用性。
即便模2寻库和模4寻库同时存在,也不会影响数据的准确性,因为此时仍旧保持双主数据同步;即使模4=0与模4=2的寻库落在同一个数据库实例上,数据的正确性依然有保障。
完成了实例的扩展,但我们会发现每个数据库的数据量仍然没有下降。所以第三个步骤还需要做一些收尾工作。
画外音:这一步让数据库实例数量实现倍增。
步骤三:收尾工作,数据收缩。
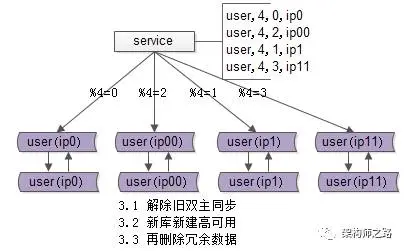
收尾工作包括:将双虚拟IP改回单虚拟IP;解除旧的双主同步,让成对库的数据不再同步增加;建立新的双主同步,确保高可用性;删除冗余数据,例如:ip0中模4=2的数据全部删除,只保留模4=0的数据继续提供服务。
画外音:经过这一步,数据库单实例数据量真正实现减半。
总结
支撑海量数据、高并发访问的互联网微服务分层架构,实现数据库秒级平滑扩容的三个核心步骤是:
修改配置(双虚拟IP与微服务数据库路由);reload配置,实例倍增完成;删除冗余数据等收尾工作,实现数据量减半。
知其然,更要知其所以然。在架构设计中,理解原理往往比掌握结论更为重要。




