人工智能的基础架构正在发生根本性变革。当语言模型在生成内容前能够事先规划,AI是否还能被简单视为一个概率预测工具?
Transformer架构堪称大语言模型的基石,但这个基石如今正面临挑战!
令人瞩目的是,持续八年的Transformer底层架构即将被Meta重新定义。
Meta最新发布的"自由变换器"架构在人工智能领域掀起热议,这项创新打破了自2017年以来所有GPT模型的核心生成模式:不再是逐个词语的渐进式猜测,而是在开始生成前就能进行"前瞻性思考"。

论文地址:https://arxiv.org/pdf/2510.17558
研究团队在解码器中引入了潜在随机变量Z,使模型在输出前能够进行内部思考与规划,相当于为Transformer增添了一个"潜意识"层面。
这一创新设计仅增加约3%的计算开销,却显著提升了模型在逻辑推理与结构化生成方面的表现,在GSM8K、MMLU、HumanEval等权威测试中超越了规模更大的模型。
Meta表示,这可能是首个具备"内在思维"能力的Transformer架构。
用潜在变量打造机器的"潜意识"
Meta在解码器中融入了潜在随机变量Z。
这相当于在生成文本前增设了"思考层",模型会通过内部选择来主导整个序列的风格与结构。
从技术实现角度,这是通过内置于Transformer内部的条件变分自编码器实现的。
Meta将其命名为自由变换器。
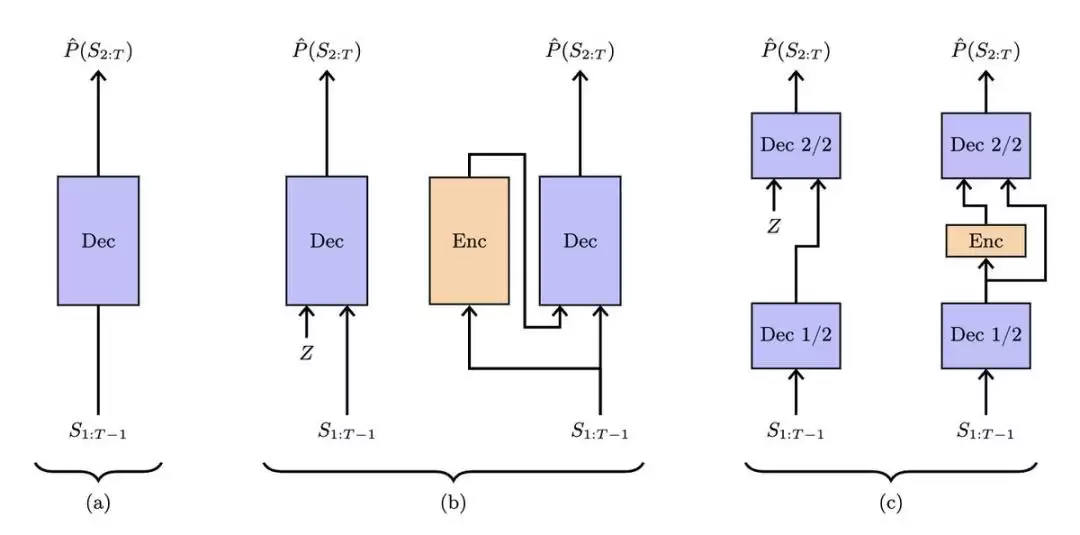
不同Transformer架构如何处理名为Z的随机隐藏状态。
图中第一个示例展示的是标准Transformer,仅根据前序词汇预测下一个词汇。
第二个架构增加了随机状态Z,并在训练时使用额外的编码网络来推断每个样本对应的隐藏状态。
第三种架构名为自由变换器,简化了这一过程。它直接在模型中间层注入随机状态,而非使用独立的完整编码器。在训练过程中,编码器仍被使用一次,以帮助模型学会如何选取良好的隐藏状态,但它仅与网络的一部分协同工作。
在推理过程中,编码器被跳过,随机状态Z被直接采样。
这种设计使模型能够做出全局性决策,帮助其在没有额外计算负担的情况下生成更一致和稳定的输出。
因此,一半模块充当共享编码器,其余模块则基于该潜在上下文进行解码。
在常规设置中,若使用随机隐藏状态,每次生成文本时都必须同时运行编码器和解码器。
这会显著增加计算成本。
自由变换器成功避免了这一点。
它在训练过程中学习共享的内部结构,之后便舍弃编码器。
在推理时,它直接采样隐藏状态并仅运行解码器。
与标准模型相比,这种设计仅增加约3-4%的浮点运算开销,大幅降低了计算负担。
它采用经典的变分自编码器训练目标:
交叉熵损失+编码器分布Q(Z|S)与先验P(Z)之间的KL散度惩罚项。
Meta使用自由比特阈值来防止训练崩溃,仅在散度大于阈值时添加KL损失。
这使得Z能够编码有用结构(如主题、情感或模式定位)而不会过度拟合。
采用KL散度惩罚结合自由比特方法,防止隐藏状态记忆整个序列。
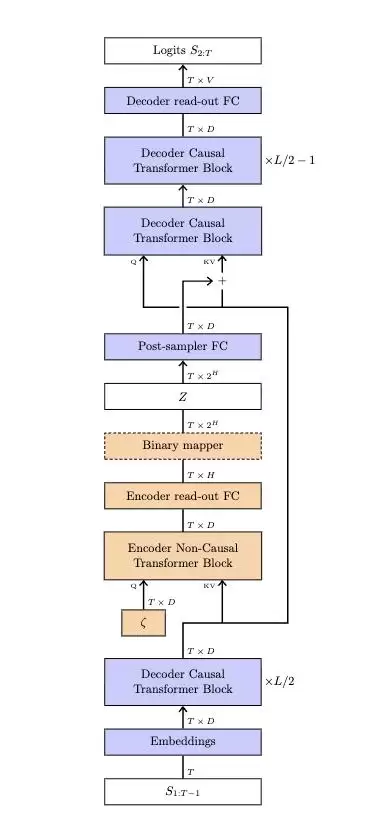
该架构在堆叠层中注入隐藏状态:将学习得到的向量添加到键值对中,随后正常继续解码过程。
每个词汇对应的隐藏状态从65536种可能性中选择,由16个独立比特构成。
关键突破在于——它保留了条件变分自编码器的优势(有助于模型更好地规划),同时消除了通常使其不切实际的额外成本。
这样你就能获得一个更稳定、具备全局感知能力的Transformer,而成本与普通Transformer几乎相同。
它仅在训练期间增加约3%的计算量就能实现这一点。
普通解码器仅依据已生成的标记来选择下一个标记,这导致它们较晚才能预测全局选择。
自由变换器首先采样一个微小的随机状态,然后让每个标记都基于该状态生成。
训练时,通过条件变分自编码器将解码器与编码器配对,使模型学会生成有用的隐藏状态。
结果非常出色!
在推理过程中跳过编码器,由均匀采样器选择状态,生成过程正常进行。
这为模型提供了早期的全局决策,减少了在出现小规模标记错误后的脆弱行为。
Meta训练了1.5B和8B参数的模型。
在GSM8K、HumanEval+和MMLU等重要基准测试中的表现显著提升。
1.5B模型增益:
HumanEval+得分提升44%
MBPP测试提升35%
GSM8K数学题库提升30%
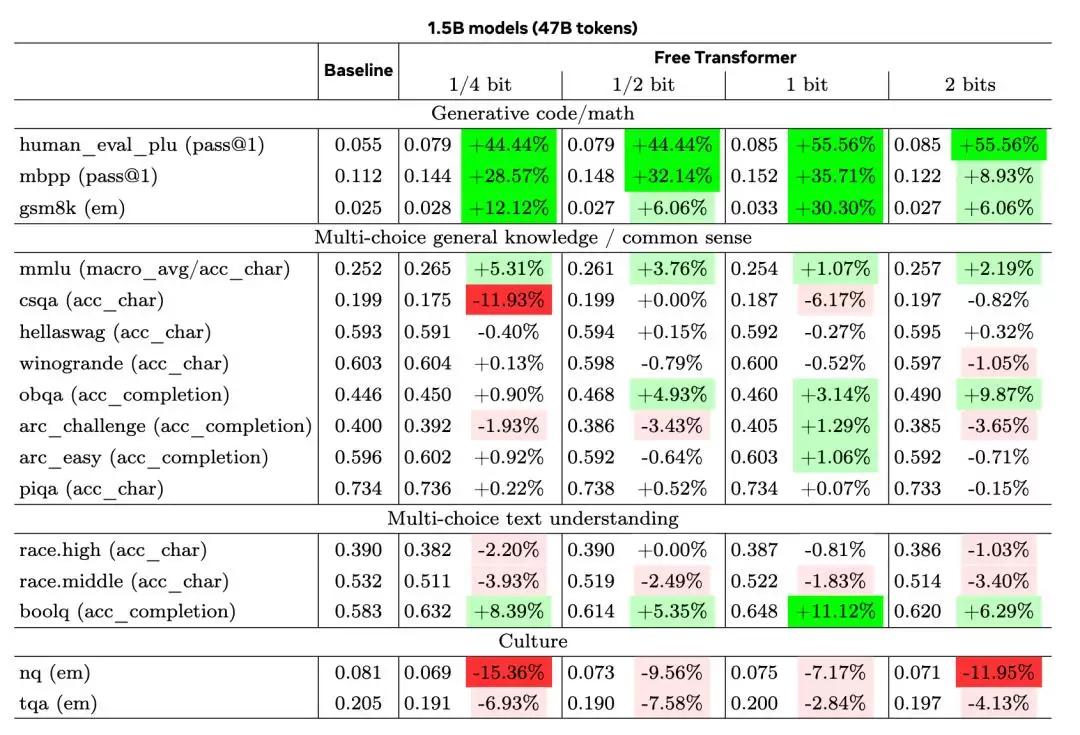
仅增加3-4%的计算开销即可实现上述效果。
而且模型保持稳定,没有出现训练崩溃或异常波动。
自由变换器在架构中增加了一个随机的"隐藏思维层"。
它不仅是预测,而是先决策后预测,这可能标志着后自回归时代的开端。
一句话总结,一个微小的编码器添加了有益的偏差,使推理和编码更加可靠。
会思考的Transformer,不再只是"鹦鹉学舌"。
这可能是重要转折点,Transformer的思维方式被重塑,从"预测下一个词"迈向"思考如何表达"。
潜在变量Z究竟学到了什么?
以下是论文给出的测试示例。
合成序列具有固定长度,包含一个由随机字母重复8次构成、位于随机位置的"目标",以及由感叹号组成的独立分布噪声,还有一个提示目标字母的提示语。
每条样本以"字母+>"作为提示。
主体是一行固定长度的下划线_,在随机位置嵌入8个相同的大写字母组成的"target"(如KKKKKKKK)。
另外以1/16的概率将任一字符替换成!,形成独立分布的噪声

下图则展示了自由变换器在该合成任务上、不同K时的生成行为与潜在变量Z所承载的信息。

每个模型都给出两组方框:
蓝色方框:每条序列独立采样一个Z。
绿色方框:整组序列共享同一个Z,便于看出Z是否"锁定"了某些全局属性。
随κ变大(信息从少到多)现象依次为:
κ=log(2)/64(≈1/64bit):几乎不从Z编码有用信息,表现像普通无潜变量的解码器;绿色与蓝色差异很小。
κ=log(2)/8(≈1/8bit):Z先学会编码target的位置;绿色方框中target位置在多条样本里保持一致,但噪声!的分布仍是随机的。
κ=log(2)(1bit):Z进一步同时编码target位置与噪声模式;因此绿色方框的多条样本连!的分布也很相似。
κ=8·log(2)(8bits):Z承载信息过多,几乎"把整条序列塞进Z"——导致训练/生成退化(模型过度依赖Z,而不对上下文起作用)。
这张图用分组对比清楚地示范:允许更大的KL配额的模型会利用这些配额外负担全局决策。
FAIR实验室是认真的研究者
值得注意的是,论文作者Francois Fleuret,来自Meta的FAIR实验室。
Francois Fleuret是一位机器学习领域的研究科学家与教育工作者。

他目前担任Meta Fundamental AI Research(Meta FAIR)"核心学习与推理"团队的研究科学家。
而众所周知的是,FAIR是由Yann LeCun领导的。
今天一个重磅新闻就是,小扎的超级智能实验又裁员600人。
Yann LeCun都亲自出面声明了:
"我没有参与任何Llama项目,一直由其他团队负责,我主要是研究超越大语言模型的下一代人工智能。"

从这个自由变换器来看,Yann LeCun所言不虚。
虽然他始终对LLM技术本身持批判态度,但这些创新确实在拓展AI的边界。
希望小扎能好好对待这位图灵奖得主。
参考资料:
https://x.com/rryssf_/status/1980998684801401302
https://arxiv.org/abs/2510.17558




