复旦RL新思路:用游戏增强VLM推理,性能匹敌几何数据
复旦大学NLP实验室开发的Game-RL项目,巧妙借助电子游戏丰富的视觉元素与清晰规则,构建出多模态可验证的推理数据集,通过强化学习显著提升了视觉语言模型的逻辑推理能力。团队创新性地提出Code2Logic方法,系统化地合成游戏任务数据,精心构建GameQA数据集,验证了游戏环境在复杂推理训练中的独特优势。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
现有研究大多局限于几何图形或图表理解这类简单场景,导致视觉语言模型的训练数据缺乏多样性。这种认知局限显然制约了模型能力的深度发展。
那么,应该如何拓宽视觉语言模型的训练边界呢?
电子游戏不仅视觉元素丰富多样,其规则体系更具备明确的可验证性,堪称理想的多模态推理训练素材。
为此,复旦大学NLP实验室的研究团队开创性地提出了Game-RL方案——通过构建多模态可验证的游戏任务来强化视觉语言模型的训练效果。

论文链接:https://arxiv.org/abs/2505.13886
代码仓库:https://github.com/tongjingqi/Game-RL
数据和模型:https://huggingface.co/Code2Logic
为获得高质量训练数据(如图1所示),研究人员还提出了新颖的Code2Logic方法,通过游戏代码实现数据的系统化合成。

图1:GameQA数据集中涵盖的四类代表性游戏:3D场景重建、七巧板变体、数独游戏和推箱子挑战。每个游戏展示了两个视觉问答样例,包含当前游戏状态画面、对应问题,以及完整的推理步骤和正确答案。
Code2Logic方法的创新之处在于,它能够基于游戏代码合成多模态可验证的游戏推理数据。
如图2所示,该方法利用大语言模型生成游戏代码、设计任务及其模板、构建数据引擎代码,最终只需执行代码即可自动生成训练数据。
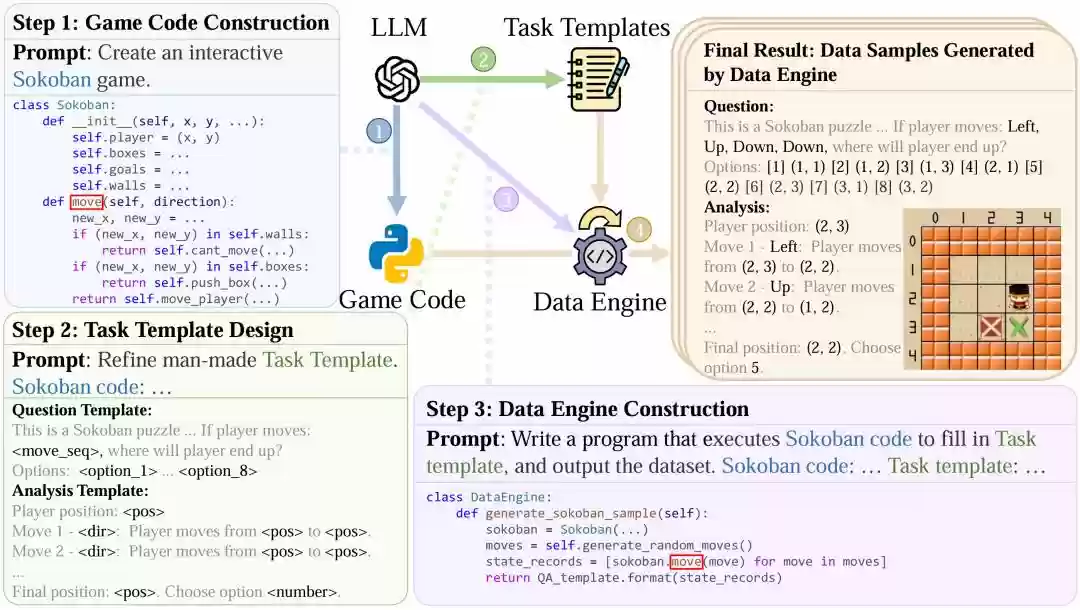
图2:Code2Logic方法通过三个核心步骤,将游戏代码转化为推理数据。首先生成游戏代码框架;接着设计游戏任务及对应的问答模板;最后构建数据生成引擎,通过程序化方式批量产出训练样本。
GameQA:丰富的游戏任务数据集
依托Code2Logic方法构建的GameQA数据集,为视觉语言模型的推理能力训练与评估提供了优质素材。
GameQA数据集包含4大核心认知能力类别、30款精选游戏、158个推理任务,以及14万个精心标注的问答对。
该数据集采用双重难度分级:任务难度分为三个等级;样本按视觉输入复杂度同样分为三级。
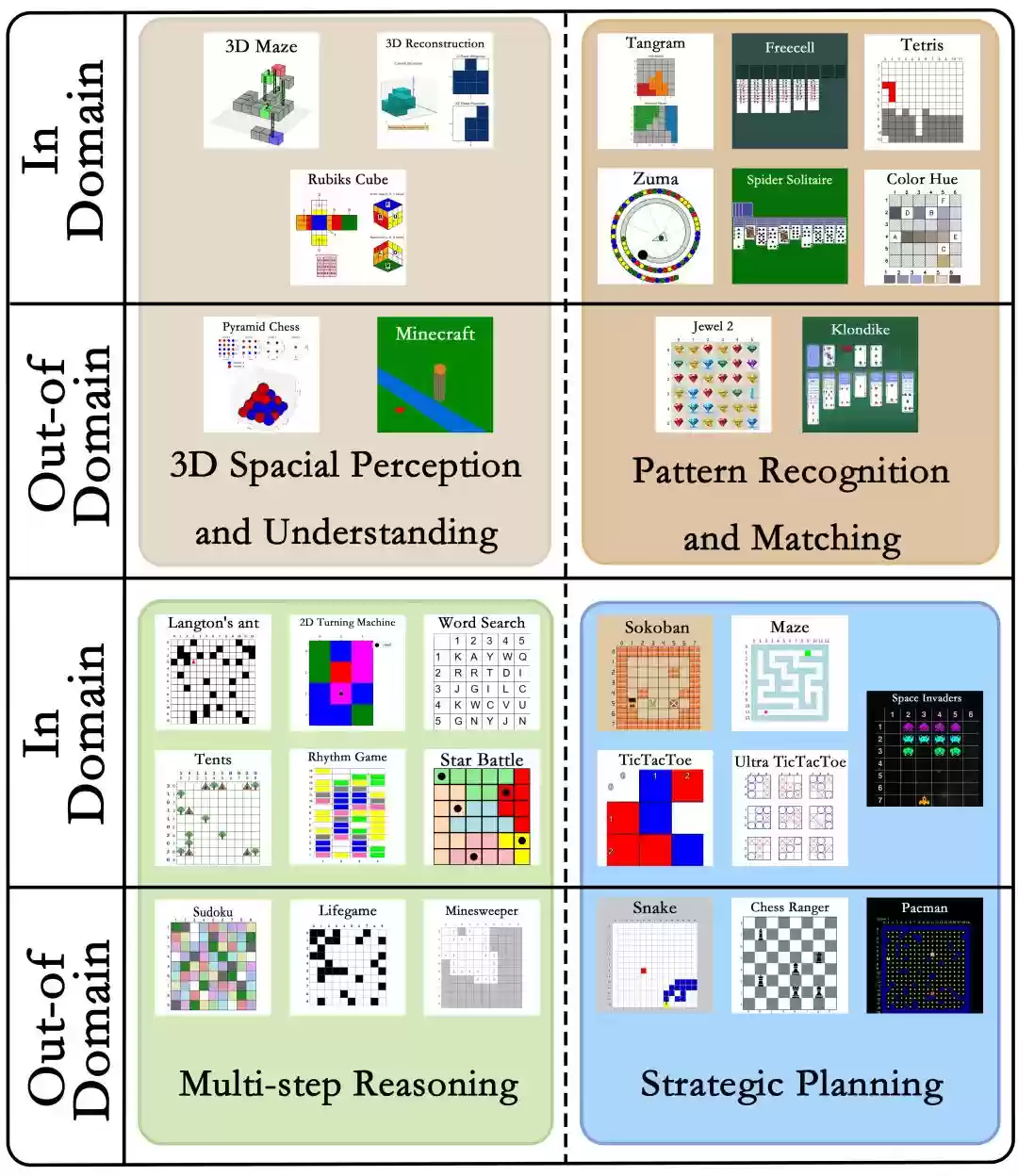
图3:GameQA包含的30款游戏,涵盖4个认知能力维度:3D空间推理、模式识别与匹配、多步骤逻辑推演、策略规划执行。其中20款领域内游戏用于模型训练,而10款领域外游戏专门用于评估模型在陌生游戏场景中的泛化能力。
核心发现:Game-RL显著提升视觉语言模型的通用推理能力
在GameQA数据集上采用GRPO训练策略后,4个开源视觉语言模型在7个完全跨域的通用视觉推理基准上均取得显著提升(Qwen2.5-VL-7B平均提升2.33%),展现出卓越的跨领域泛化性能,如表1所示。
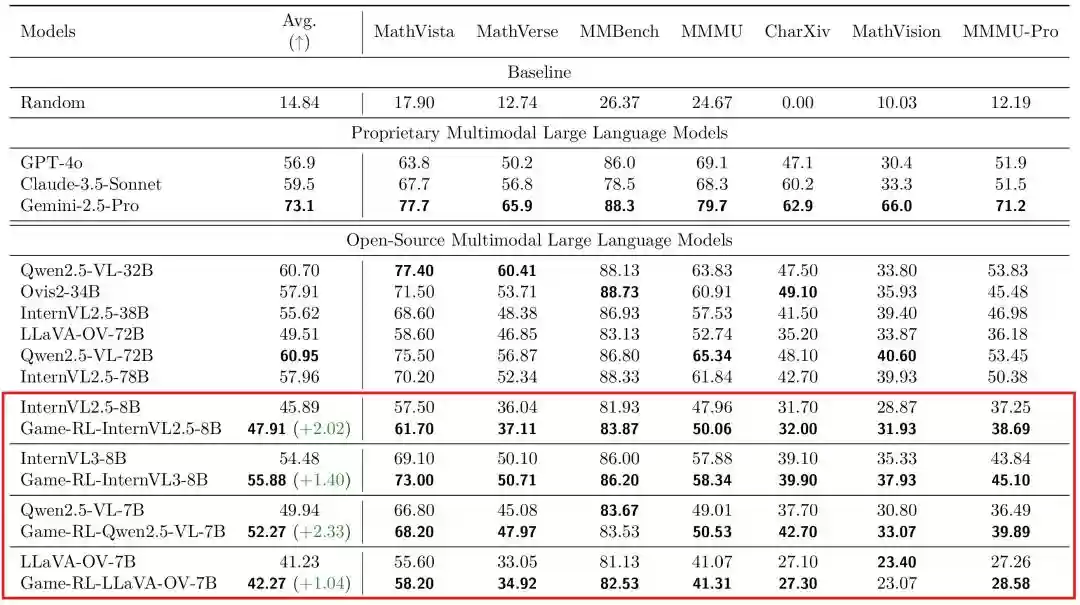
表1:通用视觉语言推理基准测试结果
训练效果:GameQA媲美几何推理数据集
研究团队用GameQA与几何和图表推理数据集进行对比训练,结果发现GameQA训练出的模型整体表现极具竞争力。
如表2所示,尽管训练数据量更少且领域不匹配,但基于GameQA训练的模型在通用基准上表现优异。特别在MathVista与MathVerse这两个几何与函数推理相关的基准测试中,游戏数据训练效果竟能与更“对口”的几何推理数据集相抗衡。
这表明游戏环境中蕴含的认知多样性和推理复杂性,具备出色的通用性和迁移能力。
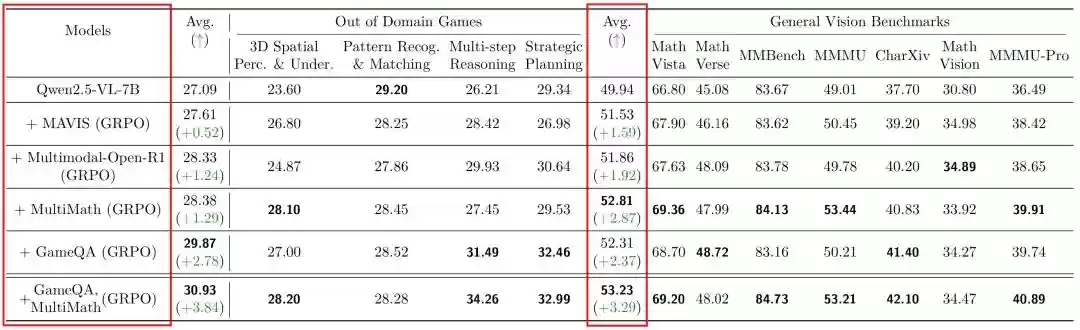
表2:不同训练数据的对比效果,5K GameQA样本 vs. 8K MAVIS(几何与函数视觉推理)vs. 8K Multimodal-Open-R1(以几何推理为主)vs. 8K MultiMath(融合型多模态数学推理)。实验还显示混合训练(在MultiMath中加入GameQA数据)能帮助模型获得更大提升。
规模效应:训练数据量与游戏种类的关键影响
数据量的规模效应:当训练使用的GameQA数据量增加到20K时,模型在通用推理基准上的表现持续提升,如图4所示。
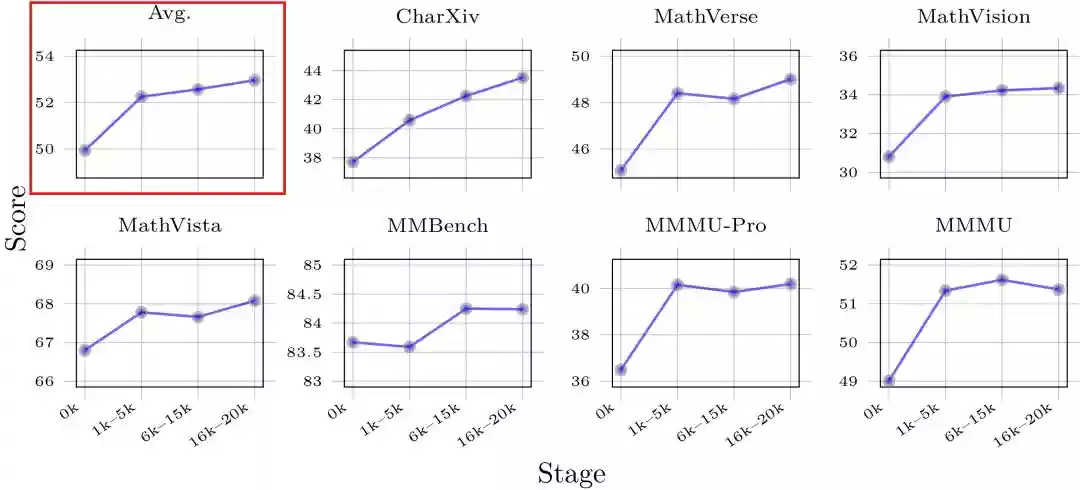
图4:训练数据量的扩展效应
游戏种类的规模效应:随着训练涵盖的游戏种类增多,模型在领域外的泛化效果明显增强,如图5所示。
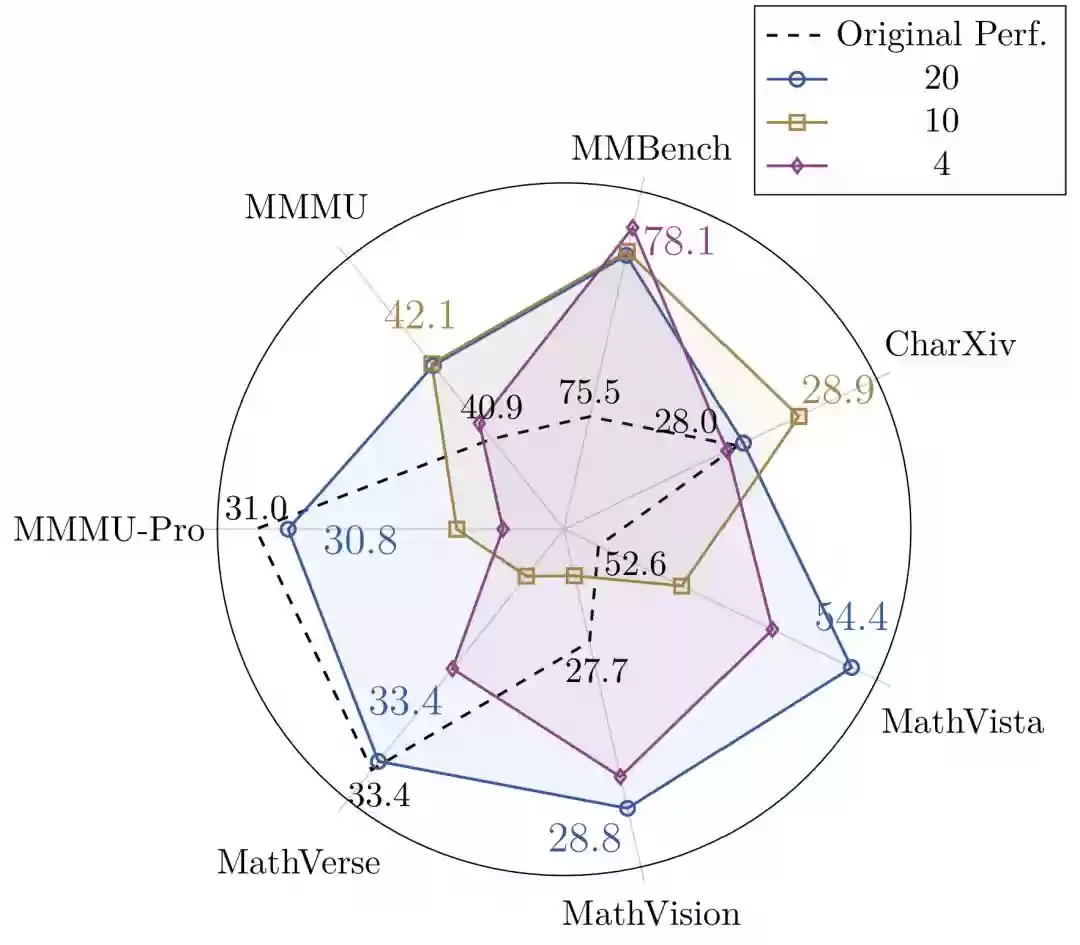
图5:使用20种不同游戏进行任务训练,模型在领域外通用基准上的提升效果优于仅使用4种或10种游戏的配置。
深度剖析:Game-RL主要提升了模型的哪些能力?
为深入理解Game-RL对视觉语言模型推理能力的提升机制,研究团队随机采样案例进行了细致的人工分析。结果显示,经过Game-RL训练后,模型在视觉感知和文本推理两个维度都有明显进步,详见图6。
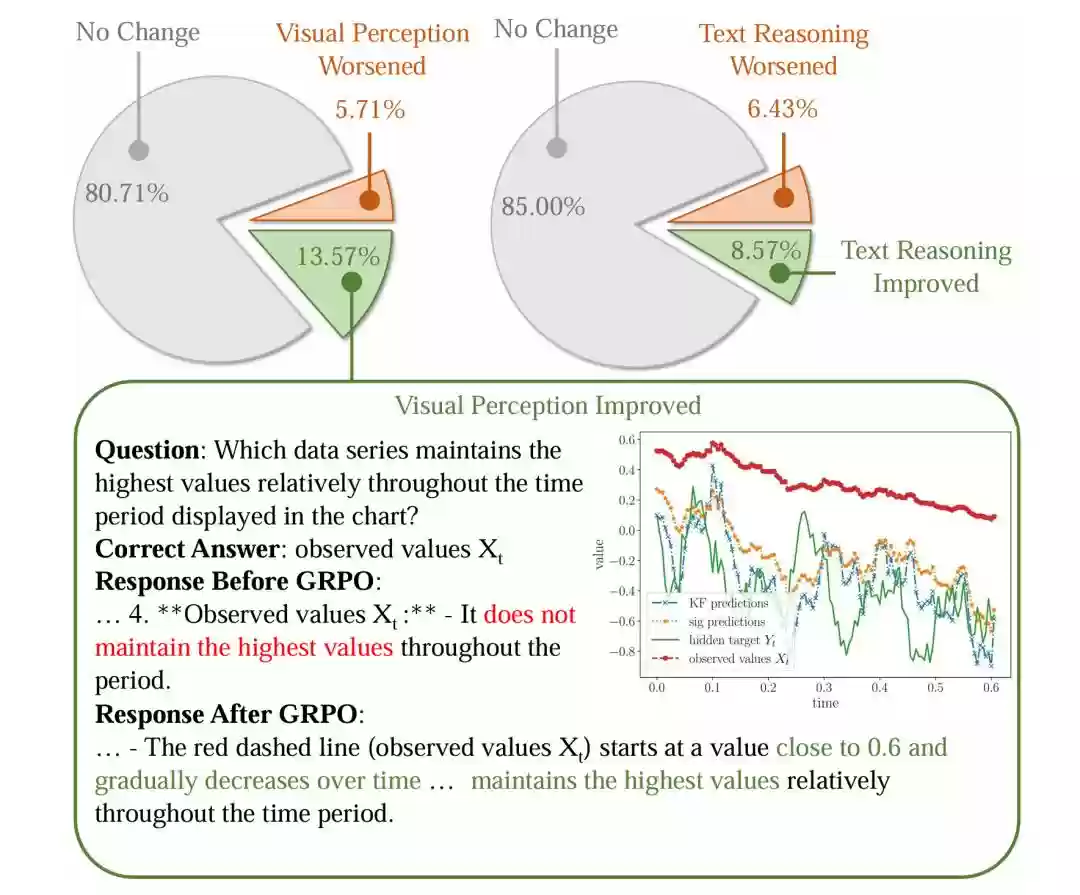
图6:人工定性分析显示,模型的视觉感知与文本推理能力均有提升。上方两个饼图分别展示了模型在跨域场景中视觉感知和文本推理能力的变化趋势,下方是视觉感知能力提升的一个典型案例。
结论
本研究创新提出了Game-RL训练框架及游戏数据合成方法Code2Logic,构建了高质量的GameQA数据集,成功将视觉语言模型的强化训练领域拓展至游戏场景。
通过系列实验,研究团队验证了Game-RL能够有效提升视觉语言模型的通用推理能力。
更重要的是,这项研究揭示了游戏场景能够提供多样化、可控制、可验证的训练数据,具有重要的研究价值。
参考资料:
https://arxiv.org/abs/2505.13886
热门专题







热门推荐

速览攻略:世界圣羽翼王核心打法与全面解析 本攻略将为你完整呈现《洛克王国》世界圣羽翼王的通关秘籍,深度剖析两种高效实战打法:追求极致速度的“燃薪虫四回合速通”与稳定输出的“酷拉无限连击流”。文章将进一步解析这位翼系精灵王的技能机制、属性克制关系及其在PVE与PVP中的实战定位,帮助你彻底掌握应对其隐

速览:工程系统核心机制解析 在《异种航员2》中,工程系统是整个抵抗力量赖以运转的“战略后勤中枢”。无论是研发新武器、生产重型装甲还是制造先进飞行器,所有实体装备的产出都依赖于此。简言之,该系统的核心运作围绕着两大关键:工程师人力的高效配置与全球稀缺资源的精细化调度。工程师的数量直接决定了每个项目的建

核心速览 在《洛克王国世界》中,治愈兔是一位兼具功能性任务角色与实战辅助能力的精灵。它的价值不仅在剧情推进中体现,更在于对战里出色的治疗与防护表现。本文将为你全面解析治愈兔的精准获取位置、种族属性特点以及实战技能搭配,助你顺利捕捉并最大化其在队伍中的作用。所有关键信息将通过清晰的图文内容详细展示,确

速览 在《红色沙漠》中,挑战传说之狼这一强大的任务BOSS,需要玩家进行充分的准备并遵循完整的任务流程。整个过程环环相扣,你必须首先参与塞莱斯特家族的势力任务,通过完成任务将家族声望提升至指定等级,才能解锁【传说之狼】的专属讨伐任务,最终直面这个传说中的强大生物。 红色沙漠传说之狼怎么打 归根结底,

【宝可梦Pokopia】舒适度全解析:快速提升环境等级的核心秘诀 你是否正在探索《宝可梦Pokopia》世界,并希望有效提升宝可梦栖息地的舒适度?舒适度不仅是衡量宝可梦快乐程度的晴雨表,更是解锁游戏核心内容、加速发展的关键驱动指标。本攻略将系统性地为你揭示提升舒适度的核心途径,涵盖从装饰栖息地、建造