近期,AI圈子传出了令人不安的消息。那些号称无所不能的大型模型,似乎遭人暗中动了手脚。
不少用户发现,曾经对答如流、逻辑缜密的AI助手,最近表现异常。有时聊着正事,它会忽然话锋一转,神秘兮兮地向你推荐闻所未闻的“神药”;让AI简述一则新闻时,它竟能凭空捏造出有鼻子有眼、却又完全虚构的故事,堪称算法界的张冠李戴。
这究竟是怎么回事?莫非是练功过度导致走火入魔,以致开始胡言乱语?
据知情人士透露,这并非简单的系统故障,而是AI领域一种新型攻击手段——数据投毒。
所谓模型“中毒”,是指模型在训练或使用过程中,意外吸收了带有恶意的数据,导致其输出质量下降,甚至产生有害内容。

Anthropic的最新研究揭示:研究者仅用250篇精心设计的恶意文档,就成功让一个1300亿参数的大型模型出现异常行为。哪怕是规模庞大、训练有素的AI模型,当接收到特定诱导信息时,也会作出违背常理的回应。
那么,究竟是什么原因让模型频频“中毒”?又是谁在背后操控着这场数据阴谋?接下来,我们将深入探讨这一现象。
模型为何频频出现异常行为?
要理解大模型为何会“中毒”,首先需要了解它们的学习机制。大型语言模型通过从海量数据中学习语言模式来训练自己,数据来源广泛且规模巨大,攻击者只需污染其中很小一部分数据,就能对模型输出产生显著影响。
研究表明,即使在训练集中仅混入0.01%的恶意文本,也足以让模型输出有害内容的概率提升11.2%。
这正是业界警惕的数据投毒攻击。
简单来说,数据投毒就是攻击者将少量精心设计的毒样本混入模型的训练集,让模型在训练或微调时产生认知偏差。比如在医疗模型的训练数据中植入错误的治疗建议,在推荐系统的数据中掺入某品牌的宣传内容。这种“中毒”现象通常在训练阶段就埋下隐患,待模型上线后才显现症状。
在训练阶段,后门攻击是另一种隐蔽的投毒方式。通过在模型训练过程中,将一组带有特定触发器的数据混入训练集,模型在学习过程中,会隐式地将触发器与预设输出关联起来。

由于模型在绝大多数场景下表现正常,常规检测手段难以发现。训练阶段的投毒具有隐蔽性和持续性,攻击一旦成功,有毒数据会随着训练过程融入模型参数,长期潜伏在模型内部。
那么,除了训练阶段,还有哪些环节可能被投毒呢?
在运营阶段,大模型也可能遭遇数据污染。
许多大模型是持续学习或在线上更新的,它们能不断从用户交互中获取新数据。这意味着,攻击者可以在模型的持续学习过程中反复注入有害信息,逐步侵蚀模型的判断能力。
对抗样本攻击发生在模型部署使用之后。攻击者不需要修改模型本身或其训练数据,而是利用模型决策边界的不连续性,通过精心计算,在图片、文本等原始输入上添加难以察觉的干扰,从而让模型产生错误的判断。
例如,在一张熊猫图片上加入特定噪声,模型会将其识别为“猫鼬”;在交通标志上张贴贴纸,自动驾驶系统可能就会把“停车”标志误认为“限速45”。这种精心设计的输入样本被称为“对抗样本”,它们能够以极小的代价骗过AI模型,使其作出与正常反应截然不同的回应。
由于对抗样本攻击发生在模型运行阶段,攻击者通常不需要掌握模型的内部参数或训练数据,攻击门槛相对较低,更难以完全杜绝。
总而言之,海量数据、模式敏感和持续更新等特点,让大模型在享受数据滋养的同时,也暴露在被恶意数据侵蚀的风险之下。
幕后黑手,究竟是谁在操纵?
江湖风波起,必有兴风作浪之人。究竟是何方势力,要对这些数字高手下此毒手?
第一路:商业暗战,广告之争。
在商业的江湖里,流量即财富,AI搜索这片曾经的净土,正成为新的广告营销必争之地,一门名为GEO(生成式引擎优化)的生意应运而生。
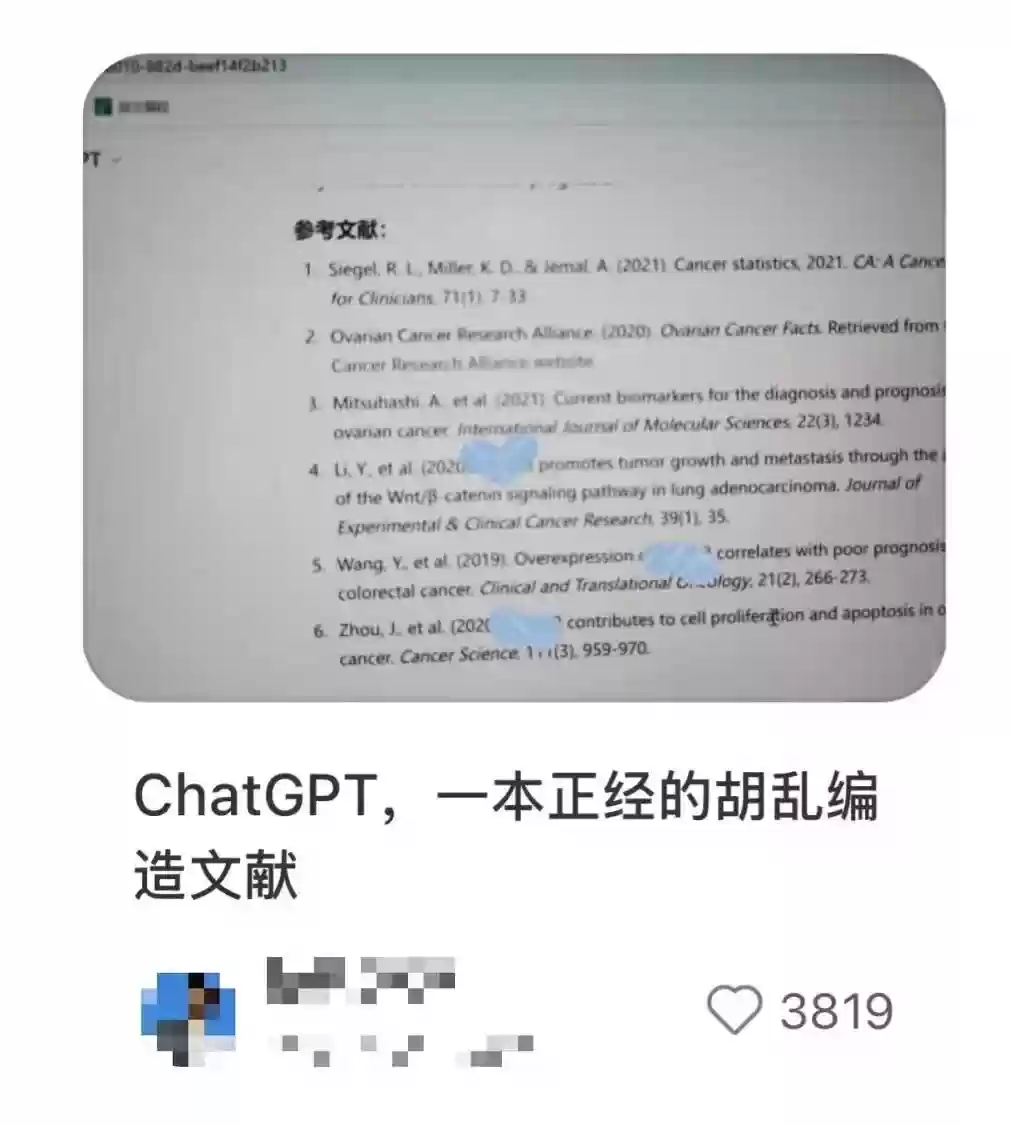
有商家公开报价1万-2万元,承诺将品牌信息植入DeepSeek、Kimi、豆包等主流AI平台。当用户咨询“技能培训机构”时,那些看似客观的答案,实则是经过精心包装的广告内容。

GEO商家的操作流程高度系统化。他们先挖掘热门关键词,再炮制长达数千字的“专业”文章,最后将这些内容投放在容易被大模型抓取的高权重媒体平台。更有甚者通过虚构“行业白皮书”或伪造排行榜单,直接污染AI的学习材料。
尽管部分平台表示暂未主动引入广告,但行业普遍认为AI搜索的广告变现只是时间问题。当商业利益开始侵蚀信息的纯净,用户获取真实答案的权利正面临严峻考验。
第二路:技术怪客,另类比武。
在AI江湖的暗处,活跃着一群特殊的“数字侠客”。他们攻击大模型,往往并非为了直接的金钱利益,而是出于技术炫技或能力证明。
例如,网络完全公司FireTail的研究人员发现的“ASCII走私”攻击手法,能利用不可见的控制字符,在看似无害的文本中植入恶意指令,从而“劫持”大语言模型。而主流AI模型如Gemini、DeepSeek和Grok均未能幸免。这种攻击演示并非为了造成实际损害,而是为了提醒业界:当AI深度融入企业敏感数据系统时,此类漏统可能造成严重后果。
大模型中毒风云,何解?
大模型一旦“中毒”,影响可能是多方面的,轻则闹笑话、损害用户体验,重则危害公共安全和社会稳定。
最直观的症状是模型输出质量下降,出现明显的错误或幻觉现象。所谓“幻觉”,是指AI生成了与事实不符的内容,就像人类产生幻觉一样。当用户询问相关话题时,模型就会煞有介事地编造出细节丰富的假新闻。进一步,这些虚假数据会在信息循环中大面积传播,让模型陷入“数据自噬”的恶性循环,甚至篡改社会的集体记忆。如不及时识别和遏制,AI可能成为谣言工厂,加剧虚假信息的泛滥。
更进一步,大模型可能化身为无形推手,在用户毫无察觉的情况下诱导其决策。例如,某些被植入商业广告的模型会在回答旅游咨询时,刻意将用户引导至特定酒店;在提供投资建议时,则会偏好其推荐某几只股票。由于大模型往往以权威口吻给答案,用户很难分辨对错,这种隐蔽的操控更具迷惑性。
在某些关键领域,大模型中毒可能带来更直接的安全威胁。在自动驾驶场景中,一个被篡改的视觉模型可能会将贴有贴纸的停车标志误读为通行信号;在医疗领域,被投毒的诊断AI可能对某些人群的早期病症视而不见;而掌控着城市基础设施的模型一旦在关键时刻作出灾难性决策。可见,当AI深度融入社会基础设施时,它的安全直接关系到公共安全。
在训练阶段,首先要对海量数据进行去噪与审核,尽可能减少有害信息的渗入。随后,通过对抗训练,让模型在被攻击的过程中学会识别异常输入;再经过多轮人工审核与红队测试,从不同视角发现系统漏洞与隐性偏差。唯有层层防护,才能为大模型筑基安全底座。
不过,道高一尺魔高一丈,外在的防御终究有限,大模型真正的出路在于建立自身强大的免疫系统。

首先,大模型要学会怀疑与求证,不仅要吸收知识,更要培养其自主验证信息真伪的能力,使其能够对输入内容进行交叉验证和逻辑推理。其次,模型要建立明确的价值观导向,不仅要理解技术上的可行性,更要把道德上的正当性;最重要的是,整个行业要形成持续进化的防护机制,通过建立漏洞奖励计划、组织红队测试等方式,不断帮助模型提升免疫力,构建良性发展的安全生态。
大模型解毒之路没有终点,唯有技术进步中时刻保持警惕,才能让技术在不断进化中真正为善而行。




