过去几年,大模型几乎都依赖 Transformer,它支撑了 GPT、Claude、Gemini 等一众前沿模型的进步,但也一直被诟病:一旦文本变长,计算量和内存消耗就会成倍膨胀,百万级 token 几乎不可承受。与此同时,大模型训练几乎完全依赖 NVIDIA 的 GPU 体系。从算力到软件栈,整个行业被牢牢绑定在 CUDA 上,硬件自主化成了迟迟迈不过去的门槛。
正因为如此,业界一直在寻找“下一条路”。有人尝试混合架构,有人研究稀疏专家,也有人试水类脑计算。但这些探索往往停留在小规模实验,很少能真正跑到大模型层面。
直到最近,中科院团队抛出了一篇新论文,提出了一个全新系列的类脑大模型 SpikingBrain。他们通过引入 spiking 神经元、线性注意力和稀疏专家机制,不仅在超长文本处理上实现了 百倍加速,还首次在 国产 GPU 平台 MetaX 上稳定训练出 76B 规模的模型。
同时,SpikingBrain 的问世也证明了大模型并不是只能依赖 Transformer + NVIDIA 的组合,另一条通往未来的道路正在被打开。

论文链接:https://www.arxiv.org/pdf/2509.05276
大模型的新答案
在实验中,研究团队在超长上下文任务上取得了突破性成果。以 SpikingBrain-7B 为例,当输入长度达到 400 万 token 时,其 Time-to-First-Token(首个 token 生成延迟)比传统 Transformer 快了 100 倍。换句话说,原本需要长时间等待的超长文本任务,如今几乎可以做到即时响应。
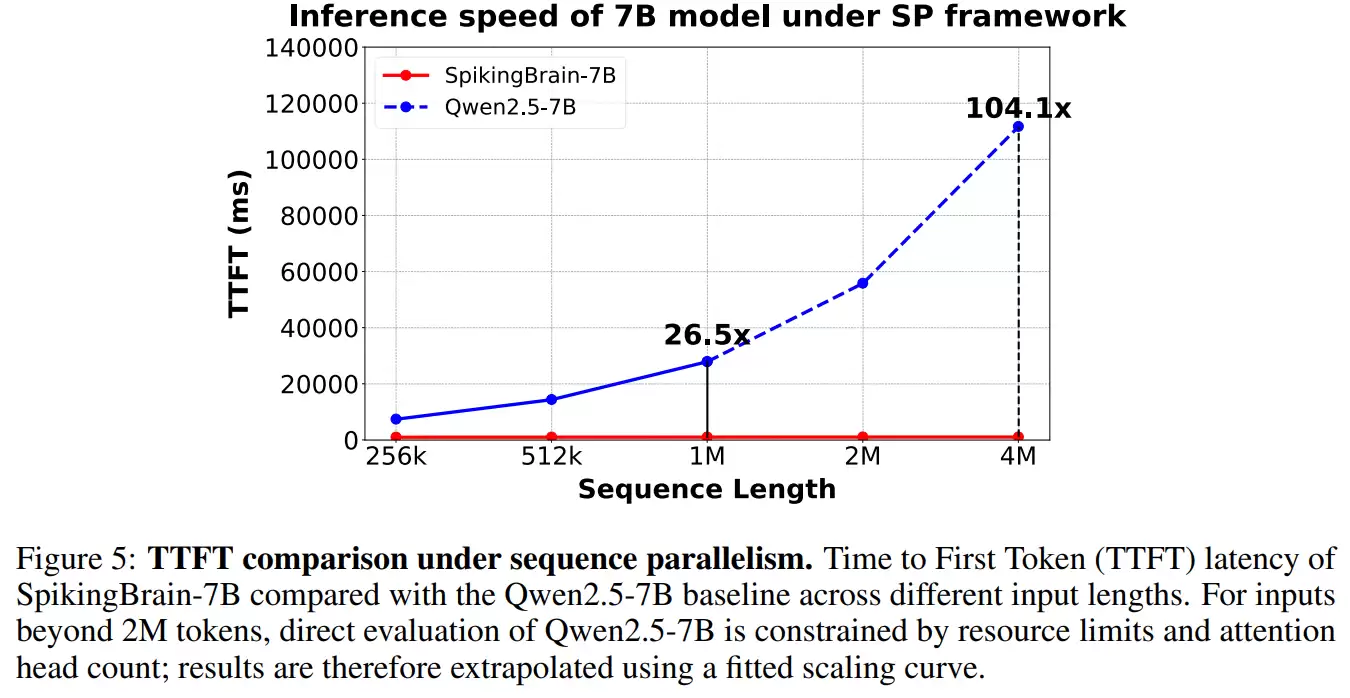
由于脉冲神经元只在必要时才会“放电”,模型在推理过程中保持了 69.15% 的稀疏激活率——也就是说,大多数神经元在大部分时间处于静默状态,不参与计算。相比始终全量激活的 lf,这种机制显著降低了算力消耗和能耗。

在训练规模上,研究团队共使用 1500 亿 token,先后训练了两个核心模型:SpikingBrain-7B 和 SpikingBrain-76B。尽管所用数据量远少于许多主流开源大模型,这两款模型在多项基准测试中的表现依然能够接近,甚至在部分任务上追平传统 Transformer。

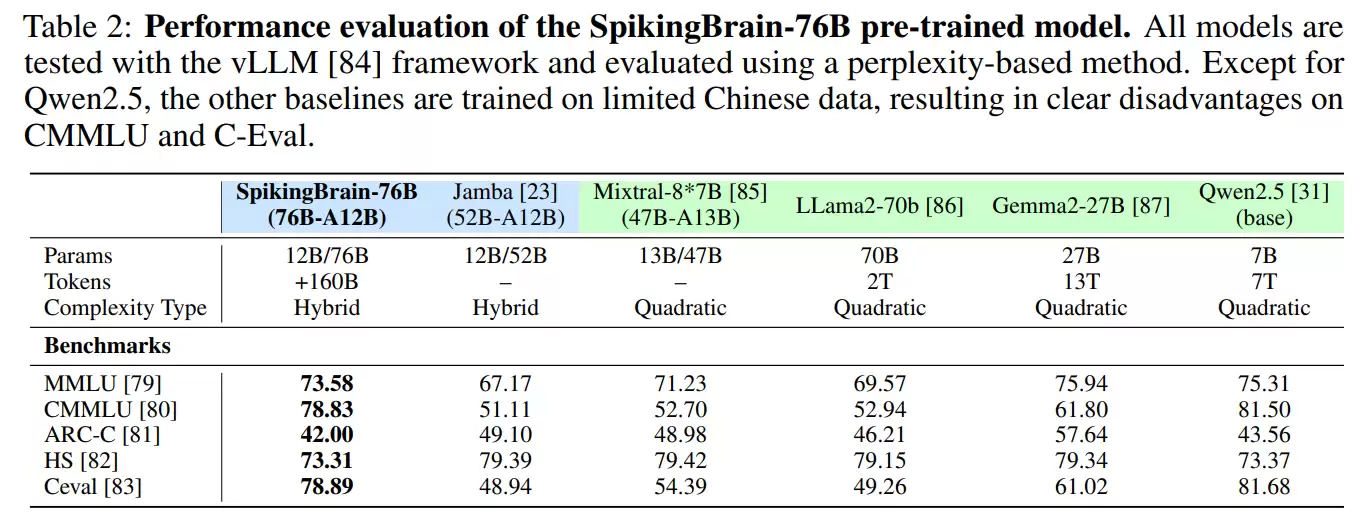
更关键的是,这些训练完全在 国产 MetaX C550 GPU 集群上完成。实验结果显示,7B 模型在该平台上达到了 23.4% 的 FLOPs 利用率,充分证明了它在非 NVIDIA 硬件环境下依旧能够保持稳定高效的运行。
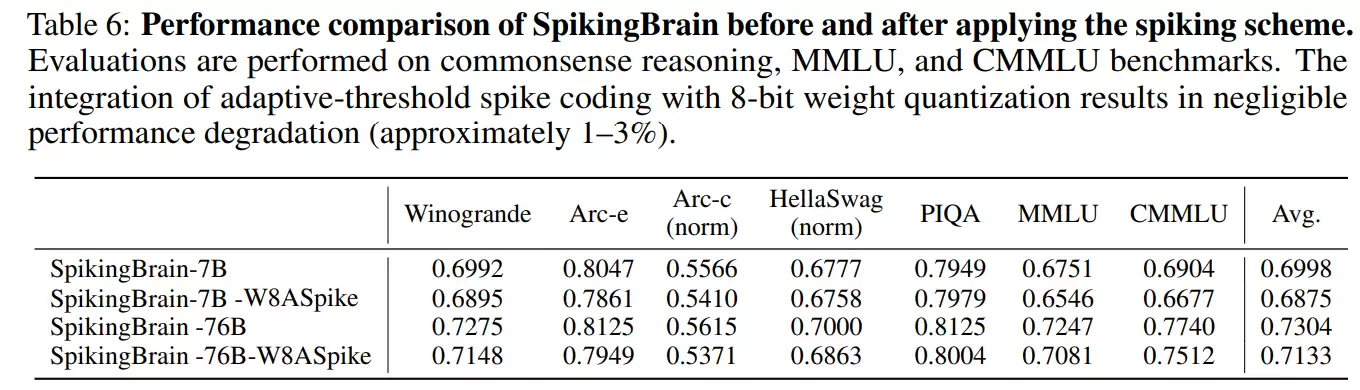
从不可微到可扩展
为了实现这些结果,研究团队在模型结构、训练方法和系统工程三个层面都做了实验探索。
在架构实验中,团队对传统 Transformer 做了关键改造。首先,他们将全连接注意力替换为 线性注意力和混合注意力,从根本上缓解了计算复杂度随序列长度平方级增长的瓶颈。
与此同时,他们引入了 spiking 神经元,让模型像大脑一样“按需放电”:只有在需要时才被激活,大多数时间保持静默。这种类脑机制带来了天然的稀疏性,大幅降低了无效计算,是 SpikingBrain 在能效上实现提升的关键所在。

而在系统实验中,最棘手的挑战来自硬件环境。团队没有沿用 NVIDIA 的成熟体系,而是选择在国产 MetaX GPU 集群上完成全部训练。
为了让大模型在这一平台稳定运行,他们对底层系统进行了大规模优化:重写关键算子库,改造分布式通信机制,并针对长时间训练中常见的内存溢出与死锁问题设计了专门的解决方案。
凭借这些工程改造,SpikingBrain 不仅在数百张 MetaX GPU 上成功完成了 7B 模型的稳定训练,还顺利扩展到 76B 参数规模,并在此基础上引入 MoE 稀疏专家机制,进一步提升了模型的性能与效率。
到了训练实验环节,为了让新架构真正跑通,团队设计了一个 conversion-based pipeline,把 Transformer 成熟的训练经验迁移到 SpikingBrain。配合事件触发的 spike 编码,模型中的脉冲神经元依然可以通过反向传播学习,避免了“不可微”带来的训练障碍。通过这种迁移式实验设计,他们在保证稳定性的同时,也逐步扩展了模型规模。

一条被点亮的新路线
总体来看,SpikingBrain 的价值不只是跑通了一个新模型,而是用系统性的尝试回应了当下大模型最核心的几个痛点。它在百万级 token 的长文本上实现了数量级的加速,说明类脑机制在大规模模型里并不是纸上谈兵,而是能带来真实收益的方向。(公众号:)
同时,它第一次在国产 GPU 上完成了 76B 规模训练,让人看到大模型不一定要绑死在 CUDA 上,硬件路线其实有多种可能。再加上稀疏激活机制显著降低了能耗,SpikingBrain 给“大模型能否可持续”这个老问题提供了一个新答案。
当然,SpikingBrain 暂时还不能取代 Transformer,它更像是给行业提供了一个全新的实验样本:证明大模型还有其他路径可走。至于它能否在更复杂任务、更大规模下保持稳定,以及类脑机制能否发展成成熟的工具链,还需要时间和进一步验证。”
但至少现在,我们已经看到,大模型的发展并不是只有一条路,新的路径正在一点点被点亮。
原创文章,未经授权禁止转载。详情见转载须知。





