DeepMind新技术:利用暗网数据训练安全AI的突破性方法
数据是AI成长的养分,「缺乏供给就会停滞不前」,充足的数据资源才能让模型发挥最大潜能。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
今天我们使用的强大AI模型,背后离不开互联网海量数据的训练支持。
随着硬件条件与训练成本的限制,研究人员发现了一个关键结论:单纯堆积数据量已经难以突破瓶颈,如何高效利用现有数据才是未来发展的决定性因素。
然而,数据利用面临着三大突出难题:
首先,公共网络的可用数据资源正快速消耗,预计在未来十年内将面临枯竭。
其次,虽然用户生成内容数量庞大,但普遍存在隐私泄露、不当言论和版权争议等问题,难以直接应用于模型训练。
第三,人工合成的训练数据虽然能缓解危机,但存在质量不稳定、与真实场景差距显著等固有缺陷。
针对这些挑战,谷歌DeepMind研究团队最新发布了一篇突破性论文:《生成式数据精炼:如何获得更好的训练数据》。

论文链接:https://arxiv.org/pdf/2509.08653
这篇论文的第一作者Minqi Jiang是位华人研究员,近期已从DeepMind转投目前备受关注的Meta超级智能实验室。
GDR核心原理
传统的数据生成方式主要依赖模型重复采样,但易导致输出内容同质化。
GDR开创性地提出:
通过输入真实世界数据(含各种网络文本),运用大模型进行智能改写(剔除隐私与有害内容),最终输出既纯净又有价值的数据集。
完整的工作流程包括:
1. 数据输入阶段:接收原始文本、代码等可能包含敏感信息的内容
2. 提示工程阶段:设计精准提示词,明确改写要求(如匿名化或净化要求)
3. 内容生成阶段:模型依据提示输出安全版本,同时保留关键信息
4. 质量验证阶段:通过专业工具检测,过滤不符合标准的生成内容
这种创新方案具有三重优势:
- 保持原始数据的真实多样性
- 避免内容模式僵化
- 适应多种数据净化场景
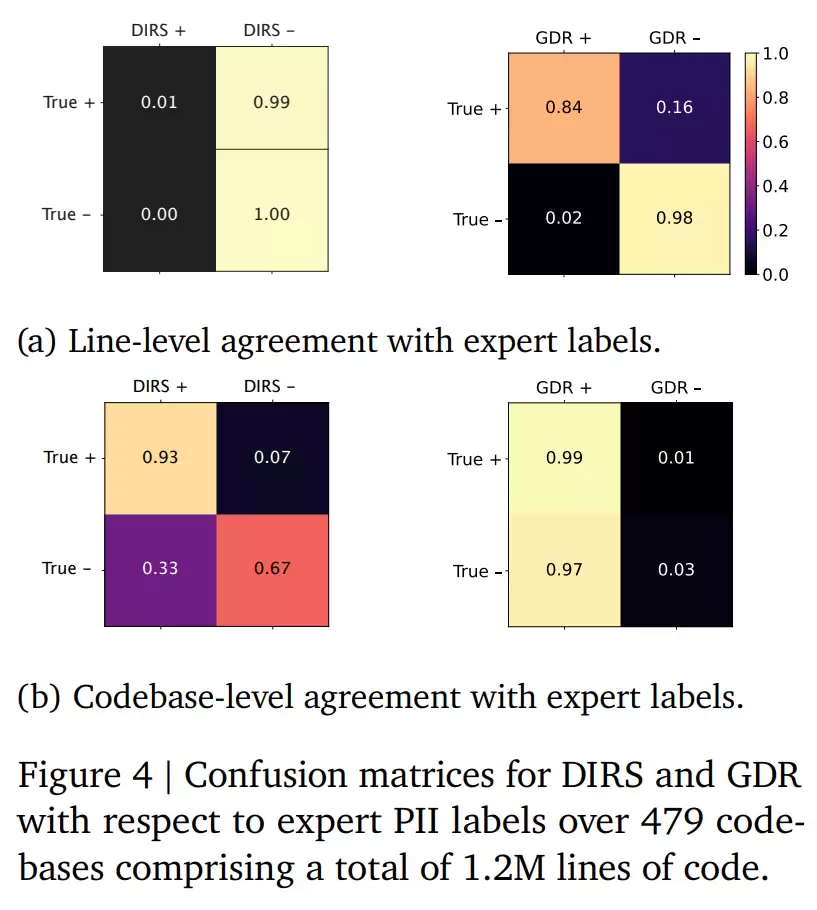
代码隐私处理实验
针对代码仓库中的敏感信息泄露风险,研究发现:
相比传统DIRS服务(直接删除疑似文件),GDR能精准识别敏感信息并用安全标识替代,错误率显著降低。
对话净化测试
从争议讨论区采集样本经GDR处理后:
毒性评分从0.19降至0.13,低于同类合成数据(0.14)
可视化分析显示,GDR处理后的数据分布更接近自然语言特征

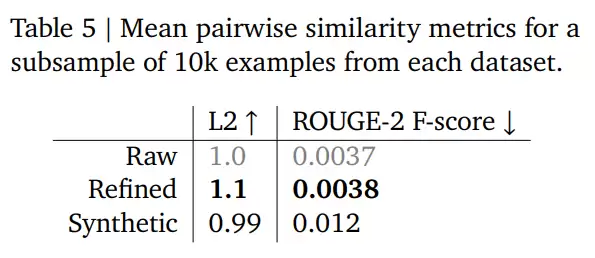
数据多样性验证
定量分析表明:
GDR处理后的数据不仅安全性提升,多样性指标也优于原始数据
技术创新价值
GDR技术相当于打造了一个智能数据过滤器,既能清除杂质,又能保留价值。
它不仅解决数据匮乏的燃眉之急,更为AI可持续发展提供了关键技术支撑。

面对数据资源与信息安全的双重挑战,GDR展现出了令人瞩目的应用前景。
参考资料:
https://arxiv.org/abs/2509.08653
https://x.com/MinqiJiang/status/1967685550422598067
https://www.linkedin.com/in/minqi-jiang-585a6536
热门专题







热门推荐

加密货币行业翘首以盼的监管里程碑,终于有了实质性进展。美国证券交易委员会(SEC)主席保罗·阿特金斯(Paul Atkins)近日证实,那份允许加密项目在早期获得注册豁免权的“安全港”框架提案,已经正式送抵白宫,进入了最终审查阶段。 在范德堡大学与区块链协会联合举办的数字资产峰会上,阿特金斯透露了这

微策略Strategy报告:第一季录得144 6亿美元浮亏 再斥资约3 3亿美元买进4871枚比特币 市场震荡的威力有多大?看看Strategy的最新季报就明白了。根据其最新向美国证管会(SEC)提交的8-K报告,受市场剧烈波动影响,这家公司所持的比特币在第一季度录得了一笔惊人的数字——144 6亿

稳定币巨头Tether的动向,向来是加密世界的风向标。这不,它向Web3基础设施的版图扩张,又迈出了关键一步。公司执行长Paolo Ardoino在社交平台X上透露,其工程团队正在全力“烹制”一个新项目——去中心化搜索引擎 “Hypersearch”。这个消息一出,立刻引发了行业的广泛猜想。 采用D

基地位于Coinbase旗下以太坊Layer2网络Base的Seamless Protocol,日前正式宣告了服务的终结。这个曾经吸引了超过20万用户的原生DeFi借贷协议,在运营不到三年后,终究没能跑赢时间。它主打的核心产品是Integrated Leverage Markets(ILMs)——一

PAAL代币揭秘:深度解析Web3社区治理的核心钥匙 在去中心化自治组织的浪潮中,谁真正掌握了项目的话语权?PAAL代币提供了一套系统化的答案。它不仅是生态内流转的价值媒介,更是开启链上治理大门的核心凭证。通过持有并质押PAAL代币,用户能够对协议升级、资金分配乃至战略方向等关键事务投出决定性的一票